ここでは、動作環境や運用の設計に考慮が必要な着目点を説明します。
レプリケーションで異なるコード系のデータベースを連携するための文字コード変換方式は2つあります。以下の目的や条件に合わせて文字コード変換方式を選択する必要があります。
※)a、b、cいずれかの条件を同時に満たす必要がある場合、文字コード変換方式は、EBCDIC/JEFコードとシフトJISコードの変換方式を採用してください。
レプリケーションの動作環境を構築した後に、文字コードの変換方式を変更する場合、データベースの再構築やアプリケーションの見直しが必要になるため、事前に要件を整理して文字コード変換の環境を設計しておくことが重要です。
EBCDIC/JEFコードとシフトJISコードの変換
PowerReplicationが、文字データをEBCDIC/JEFコードからシフトJISコードに文字コードを変換する動作環境を設計してください。
連携相手はASP V24以前のシステムを使用してください。ASP V25以降と連携する場合には、ASPレプリケーションサービスの動作文字コードにシフトJISを設定する必要があります。
自サーバには、シフトJISコードのデータベースを構築するように設計してください。
![]()
自サーバ(Windows側)にUnicodeのデータベースを使用した場合、外字(利用者定義文字)をASP側からWindows側へ反映したとき、正しくコード変換できない場合があります。変換できない文字は、‘_’(アンダーバー)に変換されます。
![]()
EBCDIC/JEFコードとシフトJISコードの変換方式は、PowerReplication V2.0/V3.0を使用した場合と同じです。
EBCDIC/JEFコードとUnicodeの変換
EBCDIC/JEFコードとUnicodeの変換はASP側で行われ、PowerReplicationは文字データをUnicodeとして扱います。このための動作環境を設計してください。
連携相手はASP V25以降で、かつ、ASPレプリケーションサービスの動作文字コードにUnicodeを設定する必要があります。
自サーバには、Unicodeのデータベースを構築するように設計してください。自サーバ(Windows)で動作するアプリケーションは、EBCDIC/JEFコードで表現できる範囲のUnicode文字を扱うように設計してください。
ASP側は、EBCDIC/JEFコードとUnicodeを変換する環境の構築が必要です。
![]()
自サーバ(Windows側)にシフトJISコードのデータベースを使用した場合、利用者定義文字をASP側からWindows側へ反映したとき、正しくコード変換できない場合があります。
![]()
PowerReplicationが文字データをUnicodeとして扱う場合、JEFコード変換タイプを指定できません。
JEFコード変換タイプを指定する必要がある場合、EBCDIC/JEFコードとシフトJISコードの変換方式を採用してください。
同期は、レプリケーショングループ単位に実行できます。同期対象とするデータファイルをグループ化して、レプリケーショングループの機能を設計してください。
レプリケーショングループの設計
レプリケーショングループは、同期を実行するタイミングや同期によって反映されるデータ量を考慮して設計してください。
![]()
サーバ間で、レプリケーションの環境を構築する場合、レプリケーショングループを設計する基本的な手順を、以下で説明します。
最初にマスタとなるサーバとレプリカとなるサーバを決定します。
マスタとするサーバで、同期の対象とするデータファイルを更新する利用者プログラム単位にグループ化し、レプリケーショングループとします。
複数のデータファイル間でデータの一貫性を保てるように、利用者プログラムのトランザクションで更新する範囲のデータファイルをグループ化してください。
レプリケーショングループの運用形態を選択します。
マスタまたはレプリカのサーバで、どちらの利用者プログラムで同期対象のデータファイルを更新するかを確認し、運用形態を選択してください。
選択基準 | 運用形態 |
|---|---|
マスタで更新する場合 | 配布 |
レプリカで更新する場合 | 集約 |
両方で更新する場合 | 共用 |
なお、運用中にマスタとレプリカのどちらも更新しない場合、「配布」または「集約」を選択してください。
同期対象のデータ量を見積もります。
同期の対象とするデータファイルの全体件数、および同期対象のデータファイルに対して利用者プログラムなどで単位時間当たりに変更する最大のデータ件数を見積もってください。
たとえば、1日に変更するデータ件数が3000件でも、10時から11時までの間に2000件を変更する業務では、単位当たりに変更するデータ件数は1時間当たり2000件と見積もります。
同期を実行するスケジュールを設定します。
レプリケーショングループに含むデータファイルを、更新する利用者プログラムを実行するタイミングや時間帯などから判断し、スケジュールを設定してください。
レプリケーショングループの同期方式を選択します。
レプリケーショングループに含むデータファイルの更新方法、レプリケーショングループの同期と利用者プログラムを実行するタイミング、およびレプリケーショングループに設定する運用形態で、同期方式を選択してください。
※)"表3.1 データファイルとして扱えるOracleのテーブルとビュー"を参照して使用可否を確認してください。
なお、"3.3.1 運用環境を調査する"で説明した調査の結果が、「一括方式」と「差分方式」の両方の選択基準を満たす必要がある場合、同期実行のスケジュール、利用者プログラムの運用方法、またはデータベースの環境を変更して、同期方式を選択してください。
同期方式に「一括方式」を選択した場合、処理モードを選択してください。
処理モードを選択する基準例を以下に示します。
選択基準 | 処理モード |
|---|---|
反映先のデータファイルを初期化してから、反映元のデータのすべてまたは一部を反映する場合※1 | 創成 |
反映元の一部のデータを反映する場合※2 | 置換 |
反映元のデータを反映先に追加する場合※3 | 追加 |
反映元のデータを反映先に上書き(追加または更新)して反映する場合※3 | 更新 |
※1)複数のレプリカグループと連携するマスタグループで運用形態が「集約」の場合、複数のデータファイルの内容を同時に反映できないため選択不可
※2)反映元のマスタ定義またはレプリカ定義に抽出条件の設定が必要
※3)同期対象のデータファイルに主キーの設定が必須
レプリケーションで関連づけるデータファイルの項目を選択します。
マスタまたはレプリカのサーバで、参照、更新する項目を選択してください。
レプリケーションの環境を構築後、動作検証を行い、必要に応じて上記の設計を見直します。
![]()
差分同期を使用するレプリケーションの環境を構築する場合、1つのデータファイルを複数のレプリケーショングループに定義しないことを推奨します。
![]()
外部キー制約で関連しているすべてのデータファイルを、1つのレプリケーショングループに含めて定義してください。
複数のデータファイルを連携するレプリケーショングループの設計
利用者プログラムのトランザクション区間内で更新するデータファイルは、1つのレプリケーショングループに含めて定義してください。
1回の同期実行で、レプリケーショングループに定義したすべてのデータファイルに対して同期が行われます。この同期実行でエラーが発生すると、同期が中断され、レプリケーショングループに定義した一部またはすべてのデータファイルが処理されません。また、一括同期を実行する場合、レプリケーショングループに含むすべてのデータファイルの同期を完了するまで、同期対象のデータファイルに対する操作ができません。
同期実行でエラーが発生する場合や一括同期の処理時間を考慮して、1つのレプリケーショングループに定義するデータファイルを選択してください。
![]()
1つのレプリケーショングループに定義するデータファイルは、10個以内とすることを推奨します。データファイルのデータ容量についても考慮し、一括同期の時間が長時間とならないようにしてください。
10個を超える場合、必要に応じて利用者プログラムを見直し、レプリケーショングループを分割してください。
![]()
同期実行でエラーが発生した場合、反映先となるOracleのデータファイルは、以下の状態となります。
一括同期でエラーが発生した場合
処理モード | 反映先データファイルの状態 |
|---|---|
創成 | 同期実行前の状態 |
置換 | 同期実行前の状態 |
差分同期でエラーが発生した場合
差分同期では、データファイル単位に同期が行われ、エラー発生直前までの更新データが反映された状態となります。このため、利用者プログラムのトランザクション区間内で複数のデータファイルを更新したデータは、反映先のデータファイル間で一貫性が保たれない場合があります。次の同期実行が完了した時点で一貫性が保たれます。
差分同期で反映先のデータファイルを処理する単位は、"差分同期のトランザクション処理例"を参照してください。
3台以上のサーバを連携するレプリケーショングループの設計
1つのデータファイルを複数のサーバで活用する場合や複数のサーバからデータを集約して1つのデータファイルを作成する場合、1つのマスタグループを複数のレプリカグループに関連づけて実現できます。
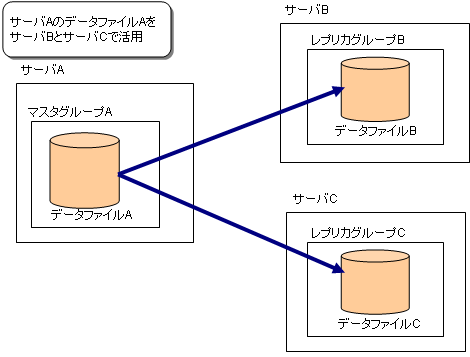
1つのデータファイルを複数のサーバで活用する場合
運用形態に「配布」を設定してレプリケーションの環境を構築してください。
図3.25 1つのデータファイルを複数のサーバで活用する場合
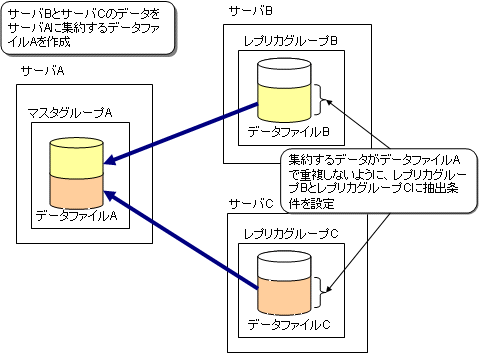
複数のサーバからデータを集約して1つのデータファイルを作成する場合
運用形態に「集約」を設定してレプリケーションの環境を構築してください。
図3.26 複数のサーバからデータを集約して1つのデータファイルを作成する場合
![]()
異なるレプリカグループから集約してマスタグループのデータファイルに反映されるとき、反映するデータの主キーの値が重複しないように、レプリカグループのレプリカ定義に抽出条件を設定してください。
各レプリカ定義に指定する抽出条件は、マスタグループのデータファイルへ反映するときに、抽出したデータが重複しないように設定してください。
抽出条件の詳細は、"2.2.3 同期の実行"を参照してください。抽出条件の設定方法は、"6.1.9 レプリカ定義画面"を参照してください。
レプリケーションの同期で、相手サーバへ転送されるデータ量を見積もってください。
同期の実行による業務への影響を、動作検証時に確認するため、同期の実行で反映されるデータ量を見積もっておくことが必要です。
差分同期を使用するレプリケーションの環境を構築する場合、更新情報がOracleの表領域に格納されます。表領域が枯渇すると、同期対象のデータファイルを更新する利用者プログラムでエラーが発生、またはレプリケーションの同期実行でデータベース間の整合性が保てなくなります。
一括同期で反映するデータ量
一括同期で相手サーバへ転送されるデータ量を見積もってください。
一括同期の実行中は、反映元および反映先で、同期対象のデータファイルがテーブルロックで排他獲得されます。このため、大量データのデータファイルを一括同期で反映すると同期の処理時間が長くなります。また、一括同期の実行中は利用者プログラムが実行できず、業務への影響が大きくなります。
一括同期で反映するデータ量を絞り込むことができます。
マスタ定義またはレプリカ定義に、反映するデータの抽出条件を設定できます。相手サーバで必要なデータを絞り込んで一括同期を行うように設計してください。
反映するデータ量を絞り込むことによって、同期の処理時間を短縮できます。
レプリケーションで反映するデータを抽出する機能の詳細は、"2.2.3 同期の実行"を参照してください。抽出条件を設定する方法は、"6.1.7 マスタ定義画面"または"6.1.9 レプリカ定義画面"を参照してください。
一括同期で相手サーバへ転送されるデータ量の見積り方法は、"B.3 通信データ量の見積り"を参照してください。
差分同期で反映するデータ量
差分同期で相手サーバへ転送される更新情報のデータ量を見積もってください。
![]()
システムの負荷が一時的に高くなって同期の完了が遅れる場合などを想定して、更新情報のデータ量は、更新情報ファイルの使用量が80%以下で運用できるように見積もることを推奨します。
差分同期で相手サーバへ転送されるデータ量の見積り方法は、"B.3 通信データ量の見積り"および"B.1 Oracleを使用する更新情報の見積り"を参照してください。
![]()
運用形態が「共用」の場合、相手サーバから差分同期の実行で反映される更新情報のデータ量を加算して見積もることが必要です。
![]()
連携する相手サーバで、システム異常の発生や予定外にシステムを停止する場合などを想定し、更新情報の見積りをn倍してください。(nを繰越数と呼びます)
差分同期を使用するレプリケーションの環境を構築する場合、相手サーバが停止している状態でも自サーバで利用者プログラムを運用できます。この場合、差分同期の実行がエラーとなりますが、更新情報は正常に蓄積されます。このため、差分同期が正常に実行できないことによって、更新情報が数倍以上に蓄積されます。このような事態を想定して見積りをn倍してください。
更新情報ファイルが枯渇しなければ、相手サーバのPowerReplicationのサービスが開始後蓄積された更新情報が反映されるため、データベース間の整合性は保たれます。
![]()
システム異常の発生や設計、運用の誤りなどで、データベース間の整合性が保てなくなった場合、データファイルを復旧するために一括同期の実行が必要となる場合があります。
このため、一括同期を実行する前提で、見積りを行うことが必要です。
利用者プログラムが実行される時間帯を考慮して、レプリケーションの同期を実行するスケジュールを設計してください。
スケジュールによる同期の実行は、1分以上の間隔で設計してください。
一括同期を利用する場合
定常的な業務の終了後、または月次処理や日次処理などのバッチ処理を行った後に、同期を実行するようにスケジュールを設計してください。
一括同期を実行すると、同期対象のデータファイルがテーブルロックで排他獲得されるため、同期実行中は、利用者プログラムからデータファイルにアクセスできません。
このため、業務が停止している時間帯に同期を開始、完了するようにスケジュールを設計することが必要です。
たとえば、日次業務が23時に完了し、翌日7時までの間、業務を運用しない時間帯が確保できる場合、一括同期を23時よりも後に実行するスケジュールを設定してください。このとき、一括同期は、翌日7時よりも前に完了していなければなりません。
このため、一括同期の処理にかかる時間を考慮して、同期実行の開始時間を設定してください。
差分同期を利用する場合
差分同期によって反映するデータ量と反映されたデータの処理に要する時間を調整して同期を実行するスケジュールを設計してください。
同期の実行間隔が短過ぎると、同期の実行間隔内に同期が完了できない場合があります。
差分同期を実行するスケジュールは、以下を考慮して設計してください。
利用者プログラムが、同期対象のデータファイルを更新するデータ量
利用者プログラムが、同期の実行で反映されたデータを処理する時間
同期の実行で反映するデータ量と同期に要する時間
同期に要する時間は、サーバの性能や動作環境に依存します。このため、スケジュールに設定する間隔は、動作検証を行いながら調整することが必要です。
![]()
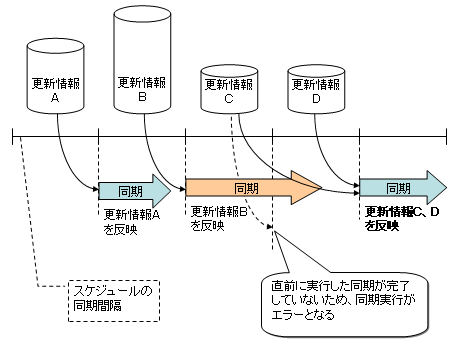
スケジュール機能を使用して特定の間隔で同期を実行する場合、同期間隔内で差分同期の処理が完了しないと、次に実行される同期がエラーとなります。エラーとなった同期で反映しようとした更新情報は、更にその次以降の同期実行で反映されます。
図3.27 差分同期がエラーとなった場合に更新情報が反映されるタイミング
![]()
1つのマスタと複数のレプリカを関連づける場合、マスタの更新情報は、すべてのレプリカへ反映が完了してから削除されます。スケジュール機能、レプリケーションマネージャ、またはrpsyncコマンドを使用し、レプリカグループ定義を選択して差分同期を実行した場合、実行時に指定したレプリカグループ定義とマスタグループ定義との間でのみ差分同期が実行され、更新情報は削除されません。
このため、更新情報ファイルが枯渇しないように、差分同期を実行するタイミングとマスタグループ定義/レプリカグループ定義の指定を意識してください。スケジュールはマスタグループ定義に設定することを推奨します。
![]()
不定期に発生する業務でサーバ間のデータベースを活用するために、業務の運用と連動して同期の実行を行いたい場合、PowerReplicationのスケジュール機能を使用せず、rpsyncコマンドを利用できます。
Windowsのバッチプログラムなどを使用して利用者プログラムとrpsyncコマンドを順次実行するようにバッチプログラムを作成することで、利用者プログラムと同期の実行を連動できます。
rpsyncコマンドの詳細は、"7.2 同期実行コマンド"を参照してください。
![]()
1分よりも短い間隔で同期を実行したい場合、スケジュール機能(同期実行の最短間隔1分間)を使用せず、相手サーバに反映する更新情報が存在するときにだけ、同期を実行できます。
更新情報取得の状態検査コマンド(rpctldif)は、相手サーバに反映する更新情報の有無を判別できます。このコマンドと同期実行コマンド(rpsync)を組み合わせたWindowsのバッチプログラムを作成することによって、数秒間隔で同期を実行できます。ただし、一回の同期で反映するデータ量が少ない場合に限ります。(一括同期の場合約8000件以下、差分同期の場合約2000件以下が目安)
サンプルプログラム
**********************************************************************************
@ECHO OFF
REM <<レプリケーション繰り返し同期実行バッチ>>
REM <<ループ処理開始>>
:LOOP
REM <<更新情報の開始状態検査>>
rpctldif -x -d ORACLE -U OracleUser xxxxxxxx REPLGRP
SET ret=%ERRORLEVEL%
REM <<戻り値判定>>
IF %ret%==0 GOTO CASE0
IF %ret%==1 GOTO CASE1
IF %ret%==2 GOTO CASE2
IF %ret%==3 GOTO CASE3
REM <<コマンドエラー(戻り値が0~3以外)>>
ECHO コマンドエラー処理を終了します
PAUSE
GOTO END
REM <<戻り値が0の場合。更新データが格納されている。>>
:CASE0
REM<<差分同期を実行>>
rpsync -w -n -d ORACLE -u OracleUser xxxxxxxx REPLGRP
REM <<戻り値が1の場合。更新データが格納されていない。>>
:CASE1
REM <<同期実行を迂回>>
ECHO 更新情報がありません。
GOTO WAIT
REM <<戻り値が2の場合。同期が実行中>>
:CASE2
REM <<同期実行を迂回>>
GOTO WAIT
REM <<戻り値が3の場合。更新情報取得が停止状態>>
:CASE3
ECHO 更新情報取得が停止状態です。処理を終了します。
PAUSE
GOTO END
REM <<3秒間WAIT>>
:WAIT
rpwait -s 3
GOTO LOOP
:END
**********************************************************************************************
rpctldifコマンドの詳細は、"7.4 更新情報取得の開始/停止/状態検査コマンド"を、rpsyncコマンドの詳細は、"7.2 同期実行コマンド"を参照してください。
上記のサンプルで使用しているrpwaitについて説明します。
rpwaitは、プログラムの実行を一定時間待ち合わせて復帰します。記述形式は以下のとおりです。
rpwait -s 待合せ時間 |
待合せ時間は秒単位で、1~6553の範囲で指定します。
サンプルを使用する場合、以下を考慮してください。
rpsyncコマンドで同期実行するレプリケーショングループには、スケジュールを設定しないでください。
rpctldifコマンドは、相手サーバの更新情報の存在を確認できません。このため、運用形態が「共用」の場合、相手サーバの更新情報を適切なタイミングで反映できません。
rpwaitの待合せ時間を極端に短くすると、システムの負荷が増加します。動作検証などを行って適切な待合せ時間を設定してください。
同期対象とするデータファイルの項目の関連づけと同期の実行で反映するデータの抽出条件を設計してください。
関連づけるデータファイルの項目
連携する相手サーバのデータファイルの構造と一致するように、データファイルの関連づけを設計してください。
データ型
関連づけに対応できるデータ型を選択してください。
関連づけに対応できるデータ型は、"付録D データ型対応づけの仕組み"を参照してください。
項目長
文字列型の項目と関連づける場合、格納するデータの長さが一致するように選択してください。
数値型の項目と関連づける場合、数値の精度、位取りが一致するように選択してください。
一意性制約
一意性制約の定義が、関連づける項目と一致するように選択してください。
NOT NULL制約
NOT NULL制約の定義が、関連づける項目と一致するように選択してください。
作成済みのデータファイルを使用する場合、上記を確認して必要に応じてデータファイルの構造を変更してください。
![]()
レプリケーションの主キーを構成する項目は、必ず、項目長、精度、位取り、一意性制約およびNOT NULL制約を一致させて関連づけてください。
主キーを複数の項目で構成している場合、項目の並び順を一致させてください。
NCHAR型の項目を含む主キーは、レプリケーションの主キーとして扱えません。
文字データに日本語文字が含まれる場合、NCHAR型を選択してください。
CHAR型を選択すると、扱う文字データの最大バイト長を項目長として設定する必要があり、データベースのコード系によって最大バイト長(項目長)が異なります。NCHAR型を選択すると、扱う文字データの最大文字数を項目長として設定でき、データベースのコード系に依存しません。
![]()
レプリケーションの主キーを構成する項目以外は、項目長、一意性制約が一致していない場合でも関連づけできます。ただし、同期実行中に、関連づけた項目に格納できないデータが存在すると、同期の実行がエラーとなり、以降のデータが反映されません。差分同期でこのような事象が発生すると、復旧するため一括同期の実行が必要です。
このため、関連づける項目の属性が一致するように設計してください。
![]()
NCHAR型の項目を含む主キーは、関連づけできません。
マスタ定義にNCHAR型の項目を含む主キーを設定して作成できますが、レプリカ定義との関連づけでエラーとなります。
![]()
CHECK制約および外部キー制約を定義したデータファイルを使用する場合、関連づけるデータファイルと制約を一致させる必要はありません。しかし、同期の実行によって反映されるデータがCHECK制約および外部キー制約に違反しないように設計してください。
このため、相手サーバで動作する利用者プログラムが、関連づけた項目に対してCHECK制約および外部キー制約に違反するデータで更新および追加しないことを確認してください。
![]()
データファイルを構成する一部の項目を選択して関連づける場合、関連づけで選択しない項目(関連づけない項目)には、データファイルの作成時にDEFAULT句を定義して暗黙値を設定してください。
関連づけた相手サーバのデータファイルに対して利用者プログラムなどでデータを追加し、同期の実行によってデータが追加されると、データファイルの作成時に設定した暗黙値が、関連づけていない項目に反映されます。
このとき、関連づけていなかった項目に暗黙値を設定せず、一意性制約やNOT NULL制約を設定していると、同期の実行でデータが反映されたときに、一意性制約違反またはNOT NULL制約違反のエラーが発生し、同期が中断されます。
同期実行で反映するデータ
連携する相手サーバで必要なデータのみを反映するように、データの抽出条件を設定してください。
抽出条件は、以下のいずれかの環境を構築する場合に設定してください。
不要なデータを反映しない(同期の処理時間を短縮したい)
データファイルの一部のデータを相手サーバで活用する場合に設定してください。
同期の処理時間は、反映するデータ量に依存するため、相手サーバで不要なデータを反映しないように抽出条件を設定することで、処理時間を短縮できます。
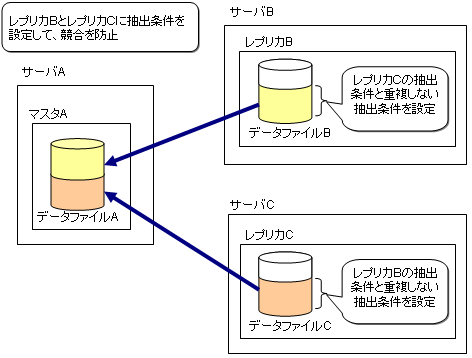
複数のレプリカから1つのマスタにデータを反映する場合
マスタの同一データに対して複数のレプリカから反映されると、競合が発生する場合があります。競合の発生を防止するため、マスタの同一データに対して複数のレプリカから反映されないように、レプリカ定義に抽出条件を設定してください。
図3.28 複数のレプリカから1つのマスタにデータを反映する場合
同期の実行で反映するデータの抽出条件の詳細は、"2.2.3 同期の実行"を参照してください。抽出条件の設定方法は、"6.1.7 マスタ定義画面"または"6.1.9 レプリカ定義画面"を参照してください。
![]()
抽出条件は、反映元のマスタ定義またはレプリカ定義に設定してください。
運用形態 | 抽出条件を設定するマスタ定義またはレプリカ定義 |
|---|---|
配布 | マスタ定義 |
集約 | レプリカ定義 |
共用 | マスタ定義およびレプリカ定義 |
![]()
運用形態の「共用」を利用してレプリケーションの環境を構築する場合、関連づけるマスタ定義とレプリカ定義の抽出条件が一致するように設定してください。
抽出条件を文字列型の項目に設定し、範囲指定する場合、抽出されるデータはDBMSに設定された照合順序に依存します。DBMSに設定された照合順序が自サーバと相手サーバで異なると、マスタとレプリカで抽出されるデータが異なります。このため、運用形態の「共用」を利用する場合、抽出条件で範囲指定するには数値型の項目に設定してください。
照合順序の詳細は、DBMSのマニュアルを参照してください。
システムを安定して稼動させるため、レプリケーション、データベースおよび利用者プログラムの運用方法を設計してください。
運用の開始と停止
以下の順序で、PowerReplicationのサービスを開始および停止を行ってください。
図3.29 運用の開始/停止手順
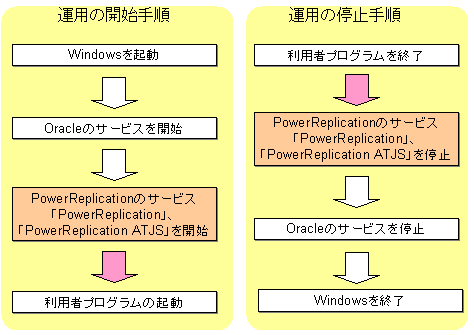
サービスの開始方法は"4.1 PowerReplicationの運用を開始する"を、停止方法は"4.2 PowerReplicationの運用を停止する"を参照してください。
更新情報のすべてが反映されていない状態でPowerReplicationのサービスを停止した場合、更新情報は保持されます。保持された更新情報は、次にサービスを再開し、差分同期を実行した時に相手サーバに反映されます。
データ更新を行う利用者プログラムの終了後、直ちにPowerReplicationのサービスを停止すると、相手サーバに反映されるタイミングが遅れる場合があります(サービス開始が翌日になると、データが反映されるのも翌日になります)。このため、同期実行によるデータ反映を完了してからシステムを停止することが必要な業務では、同期実行によるデータ反映を待ち合わせて、PowerReplicationのサービスを停止する運用の設計が必要です。
![]()
差分同期を利用してレプリケーションの環境を構築する場合、事前に更新情報の取得を開始しておくことが必要です。
初回の同期(一括同期)を実行すると、更新情報の取得は、自動的に開始されます。開始された後は、以下の場合を除いて停止されることはありません。
レプリケーションマネージャを使用して、更新情報の取得停止
rpctldifコマンドを使用して、更新情報の取得停止
更新情報ファイル枯渇の発生
システム異常の発生
このため、運用の開始時および停止時に、更新情報の取得を開始および停止する必要はありません。
![]()
更新情報の取得が停止されると、PowerReplicationのサービスを停止、開始しても、更新情報の取得は、自動的に開始されません。Windowsを再起動しても同様です。
このため、意図的に更新情報の取得を停止した場合、必ずレプリケーションマネージャまたはrpctldifコマンドを使用して、更新情報の取得を開始してください。
![]()
PowerReplicationのサービスを停止しても、更新情報の取得は自動的に停止されません。このため、サービスの停止中であっても、同期対象のデータファイルに対してデータ更新すると、更新情報が取得され、サービスを開始し同期実行で反映されます。
ただし、サービス停止中は同期実行できないため、更新情報が処理されず更新情報ファイルの枯渇が発生する原因となります。このため、サービス停止中は、同期対象のデータファイルを操作する利用者プログラムなどを、実行しない運用を推奨します。
![]()
同期実行時は、相手サーバでPowerReplicationのサービスが開始されていることが必要です。PowerReplicationのサービスが開始されていない場合、同期実行はエラーとなります。
![]()
差分同期を利用してレプリケーションの環境を構築する場合、運用形態の設定にかかわらず、マスタ側とレプリカ側の両方で更新情報取得を開始状態にしてください。両方で更新情報取得が開始状態になっていないと、同期実行はエラーとなります。
差分同期を使用するレプリケーションの環境を構築する場合、競合が発生しないように利用者プログラムを設計してください。
自サーバと相手サーバの両方で同期対象のデータファイルを更新する(運用形態に「共用」を設定する)場合、競合が発生すると、どちらか一方のサーバで更新したデータが破棄されます。
自サーバと相手サーバで動作する利用者プログラムが、同期対象のデータファイルを更新するときに、主キーの値が同じレコードの更新/削除を、1回の同期間隔内で自サーバおよび相手サーバの両方で行わないように利用者プログラムを作成してください。
以下の図で、競合を防止する利用者プログラムの例を説明します。
図3.30 競合を防止する利用者プログラムの例
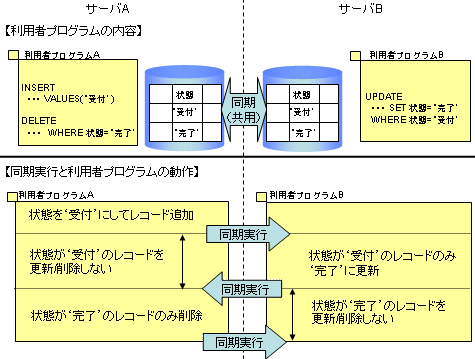
サーバAの利用者プログラム
データファイルの項目「状態」の値を‘受付’にしてレコードを追加し、値が‘完了’となったレコードのみを削除。
サーバBの利用者プログラム
データファイルの項目「状態」の値が‘受付’のレコードのみを‘完了’に変更。
このように利用者プログラムを作成することにより、1回の同期間隔内で同一レコードが、サーバAとサーバBの両方の利用者プログラムから更新、削除されることはありません。
![]()
利用者プログラムの設計とレプリケーションの運用設計によって、競合発生を防止できる場合、競合解消ルールに「反映元優先」を設定してください。競合発生が防止できない場合、競合解消ルールは「マスタ優先」または「レプリカ優先」のいずれかを選択してください。
利用者プログラムと同期の同時実行
レプリケーションの同期と同時実行した利用者プログラムが排他エラーとなった場合、レプリケーションの同期が完了後、利用者プログラムを再度実行してください。
一括同期の実行中は、同期対象のデータファイルにアクセスする利用者プログラムは実行できません。差分同期で大量データを反映する同期実行中は、レプリケーションサービスのトランザクションによって利用者プログラムが排他エラーとなる場合があります。
レプリケーションのトランザクションによる排他エラーを想定し、利用者プログラムのトランザクションを再実行するか、利用者プログラムを再実行するように設計してください。
バッチ処理で一度に大量データを更新するデータファイルの同期を行う場合、一括同期を利用して設計してください。
差分同期の対象とするデータファイルを更新するバッチ処理は、差分同期の対象としないデータファイルへの更新に比べて、バッチ処理の処理時間が長くなります。
差分同期の対象とするデータファイルをバッチ処理で更新する必要がある場合、以下の実行順序でバッチ処理を行うように設計してください。
バッチ処理で更新する同期対象のデータファイルにアクセスするすべての利用者プログラムを終了してください。相手サーバでも同様に利用者プログラムを終了してください。
対象のレプリケーショングループに設定したスケジュールを停止してください。
差分同期を実行し、更新情報を反映してください。
対象のレプリケーショングループの更新情報取得を停止してください。相手サーバのレプリケーショングループも更新情報取得を停止してください。
バッチ処理(データ更新処理)を実行してください。
対象のレプリケーショングループに対して、一括同期を実行してください。
対象のレプリケーショングループの更新情報取得が開始されていることを確認してください。相手サーバのレプリケーショングループも同様に確認してください。
停止したスケジュールを開始し、利用者プログラムの運用を再開してください。
差分同期を使用してレプリケーションの環境を構築する場合、以下の運用を考慮して設計してください。
DBMSのユーティリティ
Oracleのトリガー機能が動作しないユーティリティ(DataPump、SQL*Loaderなど)を使用して同期対象のデータファイルを更新した場合、差分同期の実行でデータベース間の整合性が保てなくなります。
差分同期を利用するレプリケーションの環境では、Oracleのトリガー機能が正しく動作できるユーティリティを使用して運用方法を設計してください。
データベースの退避/復元
同期対象のデータファイルおよび更新情報を格納する表領域(スキーマ)を退避し、後に復元すると、差分同期が正しく動作せず、データベース間の整合性が保てなくなります。
データベースの退避/復元時は、退避した同期対象のデータファイルおよび更新情報を格納する表領域(スキーマ)を復元しないように運用方法を設計してください。
同期対象のデータファイルに設定されるトリガーの変更
同期対象のデータファイルに設定されるトリガーを削除または内容を変更すると、利用者プログラムが同期対象のデータファイルへのアクセスでエラーとなります。または、差分同期が正しく動作せず、データベース間の整合性が保てなくなります。
データファイルに設定されるトリガーに対し、削除および内容の変更を行わないでください。
一括同期と差分同期に共通して、以下の運用を考慮して設計してください。
インスタンスの起動
複数のデータベースのインスタンスを起動して同時に連携できません。1つのインスタンスと連携するように設計してください。
データベースの変更
同期対象のデータファイルを削除(DROP TABLE)および変更(ALTER TABLE)すると、同期の実行でエラーとなります。
同期対象のデータファイルを削除および変更しないように運用方法を設計してください。
ユーザの変更
レプリケーションの動作環境に設定するOracleのユーザは、ユーザ名および権限を変更すると、同期の実行でエラーとなります。
動作環境に設定したOracleのユーザは、削除および変名しないでください。また、権限を変更しないでください。
レプリケーションマネージャの運用方法を設計してください。
レプリケーションマネージャは、複数のWindowsサーバまたはWindowsクライアントから同時に使用できません。同時に使用すると、無応答状態になる場合があります。
レプリケーションマネージャを使用する環境はできるだけ特定し、PowerReplicationの運用管理者が単独で使用してください。
レプリケーションマネージャは、以下のいずれかを使用できます。
レプリケーションマネージャ(Windowsサーバ)
レプリケーションマネージャ(Windowsクライアント)
レプリケーションマネージャ(ASPクライアント)
連携するレプリケーション製品のバージョンレベルが異なる場合、最も新しいレプリケーション製品に同梱されているレプリケーションマネージャを使用してください。
将来的に、レプリケーションで連携するサーバを追加する場合、レプリケーションマネージャを最新版に入れ換えが可能なように、レプリケーションマネージャ(Windowsクライアント)またはレプリケーションマネージャ(ASPクライアント)を使用してください。
なお、同じコンピュータに複数のレプリケーションマネージャをインストールすることはできません。
3つのレプリケーションマネージャの区別については、"2.4 レプリケーションマネージャ"を参照してください。
PowerReplicationの運用を行う各作業者のユーザ名と権限を設計してください。
たとえば、以下のように作業者と権限を設定してください。
作業者 | 用途 | 必要な権限 |
|---|---|---|
開発者 | PowerReplicationのすべての機能を使用し、環境を構築、動作検証を行う | レプリケーション管理者 |
PowerReplicationの運用管理者 | レプリケーションマネージャ、コマンド、Windowsのサービスおよびイベントビューアを使用して、レプリケーションの運用と保守を行う | レプリケーション管理者 |
データベースの管理者 | 更新情報を格納する表領域が枯渇した場合、表領域の拡張を行う | DBMS管理者 |
利用者 | 利用者プログラムを実行する | データファイルの所有者 |
レプリケーション専用ユーザ※ | レプリケーションサービスがDBMSに接続 | DBMS管理者 |
※)同期実行時にレプリケーションサービスがDBMSに接続するためのユーザを設定することが必要です。Oracleに組み込まれているユーザ(例:SYS,SYSTEM)をレプリケーション専用ユーザとしないでください。このレプリケーション専用ユーザは、レプリケーションサービスの動作環境に設定し、その他の用途で使用できません。
レプリケーション専用ユーザを他の用途で使用した場合、PowerReplicationの動作は保証されません。
上記に示される「レプリケーション管理者」と「DBMS管理者」の詳細については、"2.3.4 機密保護"を参照してください。
作業者を更に分割して運用する利用者の権限を制約することも可能です。詳細は、"2.3.4 機密保護"を参照してください。
![]()
権限の設定誤りや運用違反などによる問題発生時に、詳細メッセージ情報ファイルを使用して調査できます。
詳細メッセージ情報ファイルには、PowerReplicationの各機能の実行履歴や認証の履歴が記録されます。詳細は、"F.5 監査ログ情報の出力"を参照してください。
なお、詳細メッセージ情報ファイルは、レプリケーションの動作環境に設定したファイルサイズに達すると、循環して使用され古い情報が消去されるため、詳細メッセージ情報ファイルは定期的に退避しておくことを推奨します。
![]()
PowerReplicationが作成するレプリケーション資源には、第三者が操作できないようにアクセス権が設定されています。
「第三者」とは、以下のいずれの権限も持たない利用者を示します。
レプリケーション管理者
DBMS管理者
資源の所有者
レプリケーション資源の詳細は、"2.1.5 動作環境の構成"の"レプリケーション資源"を参照してください。
同期実行結果の確認方法
レプリケーションの運用中に同期の実行結果を確認する手順を設計してください。
同期の実行結果は、利用者プログラムに通知されません。実行結果は、以下を使用して確認できます。
レプリケーションマネージャ
イベントビューア(アプリケーションログ)
詳細メッセージ情報ファイル
同期が正常に動作していることを定期的に確認してください。特に、レプリケーションの環境を新規構築、追加、変更した場合や、運用の変更などが発生した直後に、問題が発生する可能性が高くなります。このような状況を想定して、同期実行結果の確認方法を設計しておきます。
実行結果を確認する手順は、"4.3 運用状態を監視する"を参照して設計してください。
自サーバまたは相手サーバでシステム異常が発生した場合を想定して、レプリケーションの環境を復旧する作業手順を、"5.2 システム異常発生時の復旧方法"を参照して設計してください。
![]()
システムに異常が発生し、レプリケーションの運用が中断された場合、復旧するために一括同期を実行することが必要な場合があります。一括同期を実行すると、未反映の更新情報は削除されるため、利用者プログラムから更新した内容の一部が無効となる場合があります。また、システム異常が発生したサーバの復旧が遅れると、相手サーバで更新情報ファイルの枯渇が発生するなど、被害が拡大し、復旧時間が更に長期化する場合があります。
![]()
関連づけたデータファイル間でデータが一致している状態であれば、一括同期を実行せずに、運用が開始できます。一括同期を実行することのほかに、データファイル間の差異を解消する方法を準備しておくことにより、システム異常発生時に復旧作業の作業時間を短縮できます。
同期対象のデータファイルにアクセスする利用者プログラムや同期対象のデータファイルの構造を考慮して、以下の復旧方法を設計することが有効です。
関連づけたデータファイル間の差異検出(差異を検出する利用者プログラム作成)
差異を解消(DBMSのユーティリティ活用または差異を解消する利用者プログラム作成)
レプリケーションの修復(更新情報の取得開始)