

| ETERNUS SF Storage Cruiser ユーザーズガイド 13.1 - Solaris (TM) Operating System / Microsoft(R) Windows(R) - |
|
目次
索引
|
本製品では、ファイバチャネルスイッチおよび、ETERNUSディスクアレイに対して性能管理機能をサポートします。この機能により、装置内の細かな動作状況や負荷状況を把握することが可能です。ただし、ETERNUSディスクアレイのメインフレームボリューム及びMVV、SDVに関する性能管理はサポートしていません。
性能情報は、Systemwalker Service Quality Coordinatorで参照することが可能です。ただし、一部サポートしていない性能情報がありますので、詳細についてはSystemwalker Service Quality Coordinatorのマニュアルを確認して下さい。
サポート装置については「1.3.5 サポートレベル」を参照して下さい。

複数の運用管理サーバから1台の装置に対して、同時に性能監視を実施しないで下さい。対象となる運用管理サーバは、Softek Storage CruiserおよびETERNUS SF Storage Cruiser、Systemwalker Resource Coordinatorの運用管理サーバも対象となります。
性能管理機能は運用管理サーバ起動時に常に起動し、性能管理設定を実施した装置に対して、バックグランドで性能情報の採取を開始します。従って、GUI画面の起動・未起動に関わらず性能情報は採取されます。性能情報の採取を終了する場合には、性能管理の停止処理を実施して下さい。
管理できる情報は以下の通りです。
ファイバチャネルスイッチの場合
| 性能情報(単位) | ファイバチャネルスイッチ | |
| ポート | 送信および受信データ転送量(MB/S) | ○ |
| CRCエラー数 | ○ |
ETERNUSディスクアレイの場合
| 性能情報 (単位) | ETERNUS8000 ETERNUS4000(M80/100除く) |
ETERNUS6000 | ETERNUS4000 M80/100, ETERNUS3000(M50除く), ETERNUS GR series (ETERNUS GR720以上) |
|
| LUN LogicalVolume RAIDGroup |
ReadおよびWrite回数 (IOPS) |
○ | ○ | ○ |
| ReadおよびWriteデータ転送量 (MB/S) |
○ | ○ | ○ | |
| ReadおよびWriteの平均応答時間 (msec) | ○ | ○ | ○ | |
| Read,Pre-fetchおよびWriteキャッシュヒット率 (%) | ○ | ○ | ○ | |
| ディスクドライブ | ディスク使用(ビジー)率 (%) | ○ | ○ | ○ |
| CM | 負荷(CPU使用)率 (%) | ○ | ○ | ○ |
| コピー残量 (GB) | ○ | ○ | × | |
| CA | 負荷(CPU使用)率(%) | × | ○ | × |
| ReadおよびWrite回数 (IOPS) |
○ | ○ | × | |
| ReadおよびWriteデータ転送量 (MB/S) |
○ | ○ | × | |
| DA | 負荷(CPU使用)率(%) | × | ○ | × |
| ReadおよびWrite回数 (IOPS) |
× | ○ | × | |
| ReadおよびWriteデータ転送量 (MB/S) |
× | ○ | × |
ETERNUS6000においてRAID Consolidationが行われている場合は RAIDGroupの平均応答時間は表示できません。
ETERNU8000およびETERNUS4000(モデル80,100除く)において、LUN Concatenationにて作成したLogicalVolume(LUN)やそのLogicalVolumeを含むRAIDGroupの性能情報は、表示できません。
ETERNUSディスクアレイのメインフレームボリュームおよびMVV,SDVに関する性能情報は未サポートです。また、SDVを含むRAIDGroupの性能情報の値は保証できません。
各装置で設定可能な性能監視間隔は、「7.2.3 監視間隔設定」を参照してください。
また、以下の時間単位のグラフウィンドウを提供します。
1時間グラフウィンドウ
選択した性能監視間隔の各時間の値を元にした折れ線グラフを1時間分表示します。
例えば、
性能監視間隔が30秒の場合は、各30秒間隔で取得した値を元にした折れ線グラフを1時間分表示します。
性能監視間隔が60秒の場合は、各1分間隔で取得した値を元にした折れ線グラフを1時間分表示します。
性能監視間隔が300秒の場合は、各5分間隔で取得した値を元にした折れ線グラフを1時間分表示します。
性能監視間隔が600秒の場合は、各10分間隔で取得した値を元にした折れ線グラフを1時間分表示します。
1日グラフウィンドウ
10分間の平均値を元にした折れ線グラフを1日分表示します。
1週間グラフウィンドウ
1時間の平均値を元にした折れ線グラフを1週間分表示します。
OSのサマータイム機能を有効にしている場合、サマータイム切替え時刻前後のグラフは、正しく表示できない部分があります。
また、性能管理情報を元にファイバチャネルスイッチ及び、ETERNUSディスクアレイに対して閾値監視機能をサポートします。
閾値監視とは、日々の業務運用において、ストレージおよびスイッチの性能値が、ある条件の下で一定の値(閾値)に達した場合に、アラームおよびレポートを通知する機能です。
閾値監視を使うメリットは、日々の業務運用において、扱うデータ量の変化や業務処理量の変化に伴うストレージおよびスイッチの性能低下の兆候を、自動的かつ確実に検出するできることです。
閾値監視機能で期待される効果は、ボトルネック箇所の早期発見および原因の特定、装置構成の改善を図ることにより性能低下による業務への影響を回避し、最適な環境での運用が可能となることです。
閾値監視機能で管理できる情報は以下の通りです。
ファイバチャネルスイッチの場合
Portスループット(%)
※Portスループット値(MB/S)に関して、最大転送能力(MB/S)に対する許容範囲の割合(%)として監視します。
ETERNUSディスクアレイの場合
LUN (OLU)のレスポンス時間(msec)
RAIDGroup (RLU,LUN_R)の平均使用(ビジー)率(%)
CM負荷(CPU使用)率 (%)
なお、閾値監視機能で提供するウィンドウには閾値監視アラームログとコンディションレポートウィンドウがあります。
閾値監視アラームログウィンドウは、この機能により監視されている装置全体で検出された閾値監視アラーム項目の一覧を表示します。
また、コンディションレポートウィンドウは以下の四種のウィンドウを提供します。
LogicalVolumeレスポンスタイム異常
監視装置内のLogicalVolumeレスポンスタイムが指定閾値設定状態を検出したことと対策指針を表示します。
RAIDGroup負荷異常
監視装置内のRAIDGroup使用率が設定状態に到達したことと対策指針を表示します。
CM負荷異常
監視装置内のCM負荷率が設定状態に到達したことと対策指針を表示します。
ポートスループット負荷異常
監視装置内のポート受信/送信使用率が設定状態に到達したことと対策指針を表示します。
閾値監視機能は運用管理サーバ起動時に常に起動され、性能管理設定を実施した装置に対してバックグランドで性能情報確保と同時に閾値監視を開始します。従って、GUI画面の起動・未起動に関わらず性能情報確保と閾値監視がされます。閾値監視を終了する場合は、本製品より閾値監視の停止を実施してください。
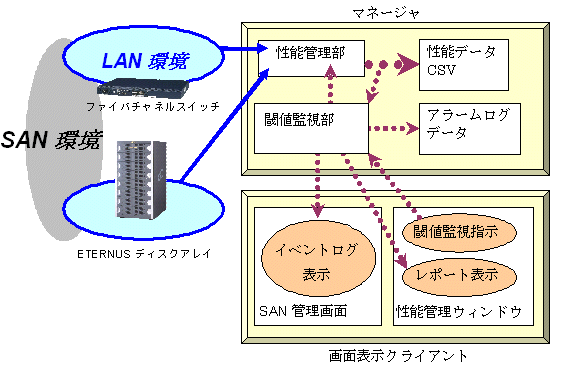
GUI画面上で性能管理対象の装置に対して性能管理指示を行なうと、本製品の性能管理部が各装置に対してLAN経由でSNMPを定期的に発行して装置の性能情報を確保し、性能データとして、運用管理サーバに格納していきます。この性能データを性能管理ウィンドウで表示して管理を実施します。
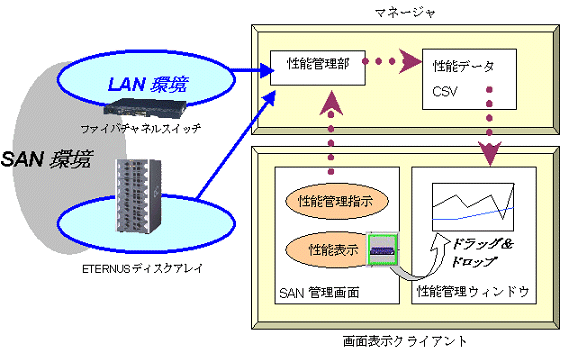
性能管理を実施する上で、性能データ格納用に運用管理サーバに多くのディスク容量が必要です。インストールガイドを参照し、十分なディスク容量が確保できているか確認してください。なお、本製品で設定保持期限を過ぎた性能データを削除する機能を持っています。標準では7日になっており、7日前以前のデータは自動的に削除されます。この設定保持期限の設定は可能です。「付録D カスタマイズ」を参照してください。
リソース管理画面のSANビューで、対象装置を左クリック選択し、メニューの[装置(D)]-[性能管理設定(S)]を選択するか、右クリックでポップアップメニューから[性能管理設定]を選択すると監視状態を設定するダイアログが表示されます。
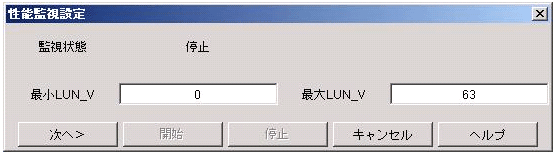
ETERNUSディスクアレイに対する性能管理設定画面
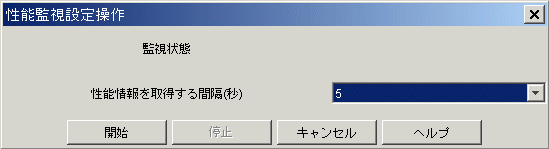
ファイバチャネルスイッチに対する性能管理設定画面
ETERNUSディスクアレイの場合は、性能情報確保対象となるLogicalVolume(LUN_V)の最小値と最大値を入力してください。LUN設定を実施する理由として、必要以外のLogicalVolume確保を実施しないことより、性能データを格納するディスク領域への影響や、性能情報確保負荷の軽減があります。従って、性能データ確保が必要な必要最小限のLogicalVolume範囲を入力することを推奨します。
内部的には64LogicalVolume単位に性能情報を確保するため、ここで入力した前後のLogicalVolumeの性能情報も確保されます。(例えばLogicalVolume(LUN_V)を70-80の範囲で画面上設定した場合、内部的には64から127までのLogicalVolumeの情報が確保されます。)
装置の構成変更を行った場合は、性能管理機能が保持する装置構成情報を更新して下さい。更新の手順については、「7.2.11 構成情報の更新」を参照下さい。
ETERNUS8000シリーズ、ETERNUS6000シリーズ、ETERNUS4000シリーズ、ETERNUS3000シリーズ、GRシリーズ、ファイバチャネルスイッチの共通設定として、性能情報を確保する間隔を入力します。間隔は5秒/10秒/30秒/60秒/300秒/600秒の設定が指定可能です。ただし、指定可能な間隔は、装置および性能を確保するLogicalVolume数により異なります。詳細は下記の表を参照してください。
|
監視条件 |
指定可能な間隔 |
|
|---|---|---|
|
装置機種 |
性能を確保するLogicalVolume数 |
|
|
ETERNUS3000 |
128以下 |
5秒/10秒/30秒/60秒/300秒 |
|
129~2047 |
30秒/60秒/300秒 |
|
|
2048以上 |
60秒/300秒 |
|
|
ETERNUS6000 |
64以下 |
10秒/30秒/60秒/300秒 |
|
65~2047 |
30秒/60秒/300秒 |
|
|
2048以上 |
60秒/300秒 |
|
|
ETERNUS8000 ETERNUS4000 |
256以下 |
30秒/60秒/300秒/600秒 |
|
257~1024 |
60秒/300秒/600秒 |
|
|
1025~8192 |
300秒/600秒 |
|
|
8193以上 |
600秒 |
|
|
ETERNUS SN200 ETERNUS SN200 MDS |
- |
5秒/10秒/30秒/60秒 |
LANトラフィックの状況あるいはサブネット越え( 性能監視対象装置と運用管理サーバ間がゲートウェイをまたぐ) などの状況では、設定した監視間隔内で性能情報を取得できない場合があります。性能情報の取得状況に応じて、監視間隔を設定して下さい。
このダイアログで[開始]を実行すると、性能管理部に対して性能情報確保指示が発行され(性能管理の流れの図参照)、性能管理部がLANを経由して装置の性能情報を確保し、性能データとして格納していきます。なお、性能管理部は運用管理サーバのデーモンとして起動されるため、運用管理サーバ起動中はGUI画面の起動なしに性能を確保し続けます。
ストレージに対しては装置の論理構成を認識し性能情報確保を開始します。よって選択されたストレージに対して初めて性能情報確保開始時は、実際の性能情報確保まで論理構成確保時間(数十秒から数分)が掛かります。
性能監視が開始されると、マップ表示上のアイコンの左上に緑色の『P』マークが表示されます。また、性能管理ウィンドウが開かれ、当該ファイバチャネルスイッチ、ストレージがツリー上に表示されている場合、装置名が『P』マークと同色で表示されます。


このPマークの色と状態、対処方法については以下の通りです。なお、この色は現状の状態と異なる場合があります。GUI画面で、[最新の情報に更新]または[F5]を実行して最新の状態を確認してください。
|
Pマークの色 |
状態 |
対処 |
|---|---|---|
|
緑 |
性能監視中(正常) |
性能監視中です。 |
|
黄 |
性能監視リカバリ中(装置タイムアウト等) |
運用管理サーバから装置に通信できません。ネットワークの状態や装置の状態を確認してください。また、ETERNUSmgr/GRmgrでログイン状態にある場合は、ログオフしてください。 |
|
赤 |
性能情報ファイル書き込み失敗 |
ファイルの書き込み権、ファイルシステムの容量を確認してください。 |
|
GRの登録パスワード違い |
本製品で装置の再登録をやり直し、再度性能監視を起動してください。 |
|
|
内部エラー |
当社保守員までご連絡ください。 |
性能を表示するために、性能管理ウィンドウを起動します。性能管理ウィンドウは、GUI画面のメニューの[ファイル(F)]-[性能管理ウィンドウ(W)]を選択するか、右クリックでポップアップメニューから[性能管理ウィンドウ]を選択することによって起動されます。
リソース管理画面で表示されている装置アイコンをドラッグして性能管理ウィンドウにドロップすることにより性能管理ウィンドウで装置の性能情報を表示することが可能になります。性能管理ウィンドウは複数作成することも可能です。また、1つの性能管理ウィンドウに対して複数の装置をドロップし、表示させることも可能です。
性能管理ウィンドウの装置のツリー表示上で、性能を表示させたいファイバチャネルスイッチのポート番号を選択し、右クリックしてポップアップメニューから[性能グラフ表示]を選択します。
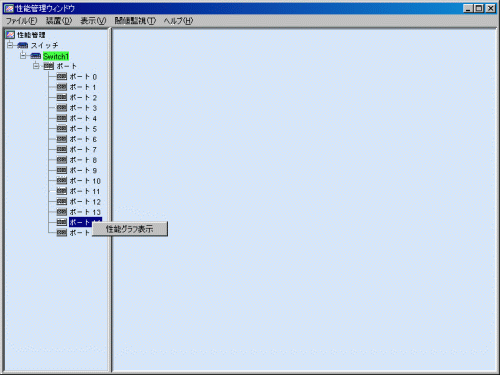
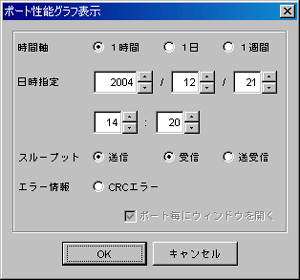
以下のダイアログが表示されます。このダイアログでは表示する内容を選択します。
|
時間軸 |
表示させたいグラフの時間幅を選択します。1時間、1日、1週間のいずれかを選択します。 |
|
日時指定 |
現在の時刻が表示されますが、表示させたいグラフの日時を選択します。 |
|
スループット |
データ転送量(MB/S)を表示します。ここでは情報種類を選択します。ポートの送信側性能のグラフウィンドウを表示するか、受信側性能のグラフウィンドウを表示するか、送受信両方性能の同時表示する1つのグラフウィンドウを表示するかを選択します。送信と受信は同時に選択可能ですが、送受信を選択すると送信・受信は選択できなくなります。 |
|
エラー情報 |
当該ポートで発生しているCRCエラー数のグラフを表示する機能です。 |
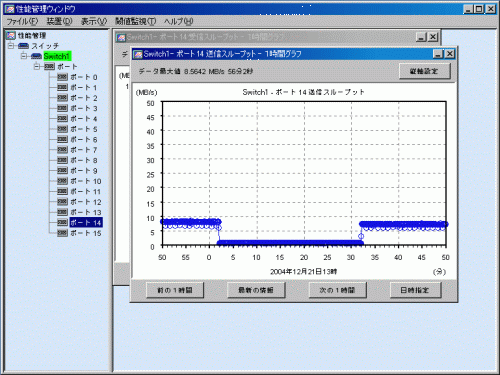
以下は上記ダイアログを選択した場合の表示結果です。送信側と、受信側の別々のスループットのグラフウィンドウが時間幅1時間で表示されます。このグラフからポートの動作状況が把握できます。グラフウィンドウの詳細な使い方については、「B.10.5 グラフウィンドウ機能説明」を参照してください。
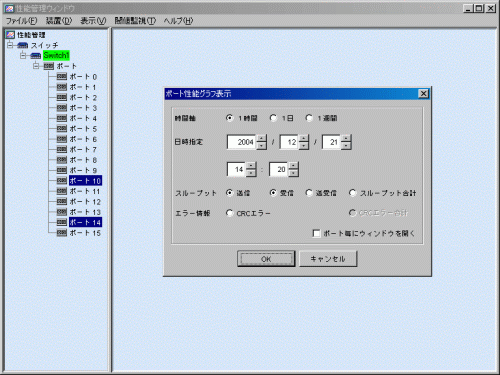
ツリー上で[Ctrl]や[Shift]キーを押しながらポートを左クリックすることにより複数ポートを選択し、右クリックしてグラフ表示を実行すると、同時に複数のポートの性能情報を表示可能です。
この場合、表示の前のダイアログでは以下のように、『ポート毎にウィンドウを開く』を選択する部分が追加されています。これを設定した場合、ポートごと別々のウィンドウが開きます。
設定しない場合は、ダイアログ内の『スループット合計』が選択可能になります。これを選択するとポートの合計値をグラフ化したものが表示され、選択しない場合は各ポートの値が同一グラフウィンドウに表示されます。なお、この時、送受信を選択し、スループットの合計を未選択とすることはできません。
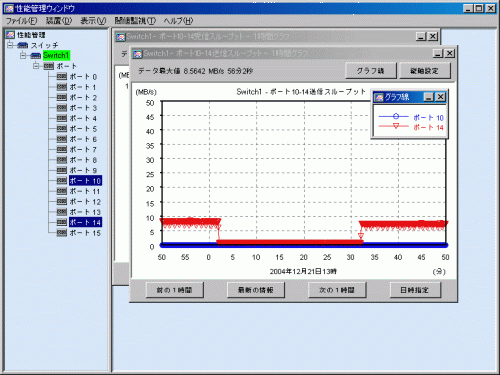
以下は『ポート毎にウィンドウを開く』及び『スループット合計』を選択せずに表示した例です。ウィンドウ上のグラフ線ボタンを選択することにより、各ポートがどのグラフ線に相当するか確認できます。この例の場合は、ポート14の使用率が高いということが分かります。
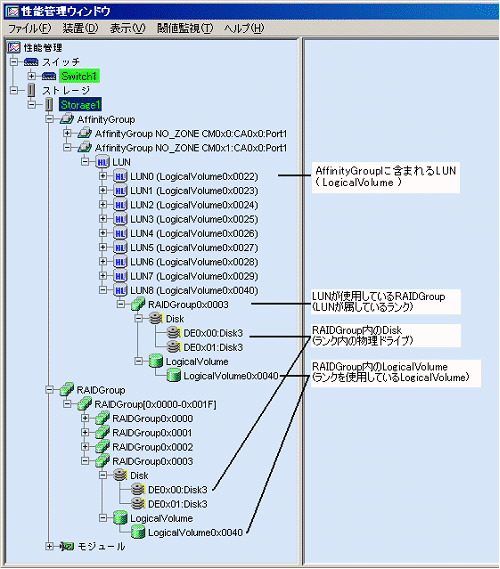
ETERNUSディスクアレイのアイコンを性能管理ウィンドウにドロップすると、以下のようなストレージの論理構成ツリーを表示することができます。
『AffinityGroup』は選択したストレージのゾーン機能の番号を表示します。
『LUN』はサーバノード側に見える論理ユニット番号になります。これは装置内部で管理している装置内ユニークな番号が与えられる『LogicalVolume(OLU、LUN_V)』に割り当てられるため、ツリーでは『LUN X(LogicalVolume X)』のように表現しています。
『LUN』配下に位置される『RAIDGroup』はそのLUNがどの『RAIDGroup』(=ランク)に含まれるかを示します。
『RAIDGroup』または『RAIDGroup[x-x]』配下の『Disk』(=物理ドライブ)はランクを構成しているドライブを表示します。『RAIDGroup』または『RAIDGroup[x-x]』配下の『LogicalVolume』は、同一RAIDGroupに属している他のLogicalVolumeの番号を表示します。
詳細については、「B.10.3 ツリー表示の説明」を参照してください。
"0x"で始まる数字は16進数、その他の数字は10進数です。
性能管理ウィンドウの装置のツリー表示上で、性能を表示させたいLUNまたはRAIDGroup番号を選択し、右クリックでポップアップメニューを表示させ[性能グラフ表示]を選択します。
この際、複数選択することも可能です。[Ctrl]や[Shift]キーを押しながらLUNまたはRAIDGroupを左クリックすることにより複数選択し、右クリックして[性能グラフ表示]を実行します。
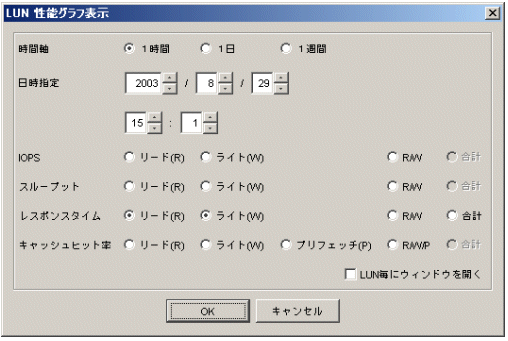
以下のダイアログが表示されます。このダイアログで表示するグラフウィンドウを選択します。
|
時間軸 |
表示させたいグラフの時間幅を選択します。1時間、1日、1週間のいずれかを選択します。 |
|
日時指定 |
現在の時刻が表示されますが、表示させたいグラフの日時を選択します。 |
|
IOPS |
1秒間に何回のI/Oが発行されたかを表示します。 |
|
スループット |
データ転送量(MB/S)を表示します。 |
|
レスポンスタイム |
平均I/O処理時間(msec)を表示します。 |
|
キャッシュヒット率 |
キャッシュにヒットした割合(%)を表示します。 |
ETERNUS6000においてRAID Consolidationが行われている場合は RAIDGroupの平均応答時間は表示できません。
ETERNU8000およびETERNUS4000(モデル80,100除く)において、LUN Concatenationにて作成したLogicalVolume(LUN)やそのLogicalVolumeを含むRAIDGroupの性能情報は、表示できません。
ETERNUSディスクアレイのメインフレームボリュームおよびMVV,SDVに関する性能情報は未サポートです。また、SDVを含むRAIDGroupの性能情報の値は保証できません。
* IOPS、スループット、レスポンスタイムは、それぞれリードのグラフウィンドウを表示するか、ライトのグラフウィンドウを表示するか、 R/W(リード及びライト)両方の情報を同時表示する1つのグラフウィンドウを表示するかを選択できます。リードとライトは同時に選択可能ですが、R/Wを選択するとリードとライトは選択できなくなります。
* キャッシュヒット率は、リードのヒット率のグラフウィンドウを表示するか、ライトのヒット率のグラフウィンドウを表示するか、プリフェッチヒット率のグラフウィンドウを表示するか、 R/W/P(リードヒット/ライトヒット/プリフェッチヒット)全ての情報を同時表示する1つのグラフウィンドウを表示するか選択できます。リードとライトとプリフェッチは同時に選択可能ですが、R/W/Pを選択するとリードとライトとプリフェッチは選択できなくなります。
ここで複数の論理ユニット番号を指定してグラフ表示を実行した場合は、ダイアログに『LUN毎にウィンドウを開く』が表示され、これを選択すると、LUNごとにグラフウィンドウが表示されます。
これを選択しない場合は、ダイアログに『合計』を選べる部分が表示され、これらを選択すると『合計』のグラフが表示され、選択しない場合は複数の論理ユニット番号の情報が同一グラフウィンドウに表示されます。なお、この時、R/W/PやR/Wを選択し、『合計』を未選択にすることはできません。
性能管理ウィンドウの装置のツリー表示上で、性能を表示させたいDisk番号を選択し、右クリックでポップアップメニューを表示し[性能グラフ表示]を選択します。
この際、複数のDiskを選択することも可能です。[Ctrl]や[Shift]キーを押しながらDiskを左クリックすることにより複数選択し、右クリックして[性能グラフ表示]を実行します。
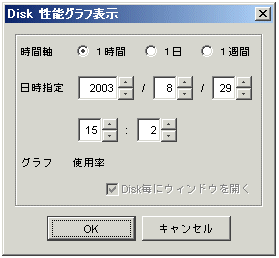
以下のダイアログが表示されます。このダイアログで表示したいグラフウィンドウを選択します。
|
時間軸 |
表示させたいグラフの時間幅を選択します。1時間、1日、1週間のいずれかを選択します。 |
|
日時指定 |
現在の時刻が表示されますが、表示させたいグラフの日時を選択します。 |
ここで複数のDisk番号を指定してグラフ表示を実行した場合は、ダイアログに『Disk毎にウィンドウを開く』が表示され、これを選択すると、Diskごとにグラフウィンドウが表示されます。これを選択しない場合は、複数Diskの情報が同一グラフウィンドウに表示されます。
性能管理ウィンドウの装置のツリー表示上で、性能を表示したいモジュール(CM,CA,DA)を選択し、右クリックでポップアップメニューを表示し、[性能グラフ表示]を選択します。 この際、複数選択することも可能です。[Ctrl]や[Shift]キーを押しながらCM/CA/DAを左クリックすることにより複数選択し、右クリックして[性能グラフ表示]を実行します。
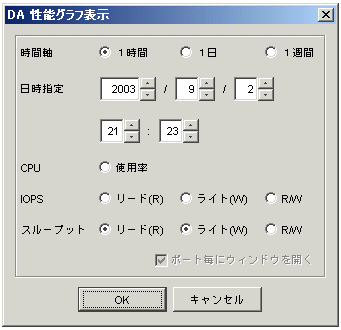
DAの場合は以下のダイアログが表示されます。CAの場合はCA性能グラフ表示ダイアログが表示されます。このダイアログで表示するグラフウィンドウを選択します。
|
時間軸 |
表示させたいグラフの時間幅を選択します。1時間、1日、1週間のいずれかを選択します。 |
|
日時指定 |
現在の時刻が表示されますが、表示させたいグラフの日時を選択します。 |
|
CPU |
DAまたはCAのCPU使用率(%)を表示します。 |
|
IOPS |
DAまたはCAポートで1秒間に何回のI/Oが発行されたかを表示します。 |
|
スループット |
DAまたはCAポートのデータ転送量(MB/S)を表示します。 |
ETERNUS8000、ETERNUS4000のCA性能グラフ表示ダイアログでは、CPUは表示されません。
CMの場合は次のダイアログが表示されます。このダイアログで表示されるグラフウィンドウを選択します。
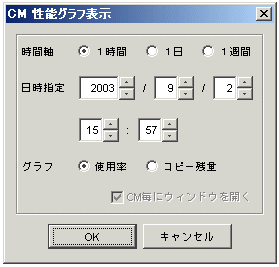
|
時間軸 |
表示させたいグラフの時間幅を選択します。1時間、1日、1週間のいずれかを選択します。 |
|
|
日時指定 |
現在の時刻が表示されますが、表示させたいグラフの日時を選択します。 |
|
|
グラフ |
使用率 |
CMモジュールのCPU使用率(%)を表示します。 |
|
コピー残量 |
アドバンスト・コピー(EC,OPC)の残りコピー量(GB)を表示します。EC/OPCが共に動いている場合、EC/OPCのトータル残りコピー量となります。 |
|
ETERNUS3000 (M50除く)、GR (ETERNUS GR720以上)のCMに対するダイアログでは、コピー残量は表示されません。
ダイアログの『ポート毎にウィンドウを開く』および『CM毎にウィンドウを開く』は、複数選択を行なった場合に選択すると、それぞれのモジュール単位にグラフウィンドウが表示されます。
性能データが大きい場合 (特にETERNUSディスクアレイのRAIDGroupや複数選択時)、LANの負荷が高い場合、<前の1時間>ボタン、<次の1時間>ボタンでグラフを表示するまで時間が掛かります。この場合は、グラフウィンドウの画面部で右クリックし、ポップアップメニューを起動すると、グラフの時間幅を変更したグラフウィンドウを表示できるコマンドが表示されます。このコマンドを選択し、1時間単位のグラフウィンドウから1日グラフウィンドウを表示させ、1日グラフウィンドウ内の見たい時刻にマウスを移動させ、再度右クリックのポップアップメニューより、1時間グラフウィンドウを選択し、確認したい時刻を中心にグラフをスムースに移動させることが可能となります。
また、1日グラフウィンドウ、1週間グラフウィンドウの<ピーク>ボタンで最大値グラフを表示できます。これにより、最大値の時刻にマウスを移動させ、右クリックのポップアップメニューにより、最大値の時刻を同様に中心としてのグラフをスムースに移動させることが可能となります。
詳細は、「B.10.5 グラフウィンドウ機能説明」を参照してください。
サーバノードからストレージに対するI/O遅延が発生した際に、ストレージ内に要因がないかを以下の方法によって調査することが可能です。なお、これは例であり、I/O遅延を決定する要素を100%この方法によって断定することを可能としているわけではありません。
I/O処理遅延が発生した時間とアクセスパスを特定してください。
本製品より対象アクセスパスに定義されているのAffinityGroup番号、LUN番号を確認します。
性能管理より対象LUN性能を表示、確認します。
LUN部のレスポンスタイムが悪い場合は、RAIDGroupの性能を確認します。RAIDGroupのレスポンスタイムも悪い場合は、RAIDGroupに属している他のLogicalVolumeを検索し、そのLogicalVolumeがどのLUNに割り当てられているかを検索します。それらのLUNのI/O状況を確認し、RAIDGroupに対して高い負荷を与えていないかを確認します。もし、高い負荷を与えていると判断した場合は、当該LUNを他RAIDGroupに移動させる等の処置を行ないます。
GUI画面で、対象装置を左クリック選択し、メニューの[装置(D)]-[性能管理設定(S)]を選択するか、右クリックでポップアップメニューから[性能管理設定(S)]を選択し、監視状態を設定する画面で[停止]を選択します。
性能管理機能では、独自に装置の構成情報を保持しています。
装置の構成を変更する場合、以下の手順に従って性能管理機能が保持する装置の構成情報を更新してください。また、性能監視および閾値監視を実施している装置に対し構成を変更した場合も、以下の手順にて構成情報を更新してください。
性能監視および閾値監視を実施している装置に対し構成を変更した場合、性能監視および閾値監視は、更新前の構成情報で監視を実施しています。以下の手順にて、構成情報を更新するまでの性能情報および閾値監視は、保証できません。
《構成情報を更新する手順》
性能監視の設定内容を記録する (性能監視を実施している場合)
《記録する設定内容》
性能情報を取得する間隔 (秒)
性能監視対象(最小LUN_V, 最大LUN_V)
閾値監視の設定内容を記録する (閾値監視を実施している場合)
《記録する設定内容》
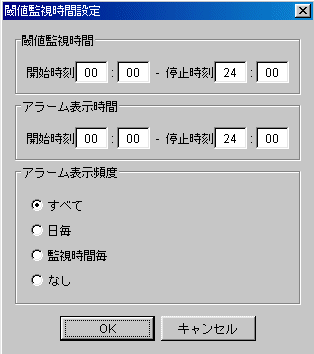
閾値監視時間設定
閾値監視時間 (開始時刻, 停止時刻)
アラーム表示時間 (開始時刻, 停止時刻)
アラーム表示頻度
閾値監視設定
閾値監視対象
閾値
閾値監視単位時間
アラーム許容範囲
アラーム許容時間
下限値
閾値監視を停止する (閾値監視を実施している場合)
「7.3.7 閾値監視停止指示」を参照してください。
性能監視を停止する (性能監視を実施している場合)
「7.2.10 性能監視停止指示」を参照してください。
装置に対し、構成変更を実施する
性能管理ウィンドウのメニューバーより[装置]-[構成情報ファイル作成]の実行する
1で記録した設定内容をもとに、性能監視を開始する (性能監視を実施している場合)
2で記録した設定内容をもとに、閾値監視を開始する (閾値監視を実施している場合)
「7.3.3 閾値監視時間帯の設定」、「7.3.4 閾値監視情報の設定」を参照してください。
性能データは運用管理サーバの以下のディレクトリ配下にCSVファイルにて格納されます。
[Solaris OS版マネージャ] /var/opt/FJSVssmgr/current/perf/配下
[Windows版マネージャ] 運用管理サーバ作業用ディレクトリ\Manager\var\opt\FJSVssmgr\current\perf\配下
必要に応じて性能データをディレクトリごと保管し、必要時に同じ形式で復旧することにより以前の情報を表示させることが可能です。
ただし、性能データは自動削除機能が動作していますので、リストア時には、データ保持期限の日数を確認の上実行してください。データ保持期限については、「D.4 perf.confパラメータ説明」を参照してください。
例:(Solaris OS)
バックアップ時
# cd /var/opt/FJSVssmgr/current/perf/
# tar -hcf - csv |compress -c > csv.backup.tar.Z
リストア時
# cd /var/opt/FJSVssmgr/current/perf/
● # uncompress -c /var/opt/FJSVssmgr/current/perf /csv.backup.tar.Z | tar -xvf -
性能管理ウィンドウで性能管理対象の装置に対して閾値監視指示を行なうと、本製品の性能管理部が各装置に対してLAN経由でSNMPを定期的に発行して装置の性能情報が確保されることで閾値監視部が性能情報を逐次、解析を行ないます。
この結果、情報として問題を検出した場合に、SAN管理画面ではアラームとしてイベントログに表示、性能管理ウィンドウでは閾値監視アラーム通知ログウィンドウに表示されます。
アラームとしてイベントログに表示されるとき、イベントレベルは"Warning"となります。
閾値監視を実施する上で、閾値監視アラーム通知ログのコンディションレポート格納用として運用管理サーバにディスク容量が必要です。おおよそ4MBを使用しますので、ディスク容量が確保できるか確認ください。なお、本製品で設定保持期限を過ぎたコンディションレポートデータを自動的に削除する機能を持っています。標準では365日になります。365日以前のデータは自動的に削除されます。この設定保持期限は変更可能です。「B.10.6 閾値監視ダイアログ機能説明」のアラーム削除設定を参照してください。
GUI画面の性能管理ウィンドウのツリーから装置名ツリーノードを選択し、メニューから[閾値監視(T)]を選択すると各種閾値監視設定のメニューが表示されます。ただし、対象装置がすでに性能管理にて性能確保指示が行われている必要があります。
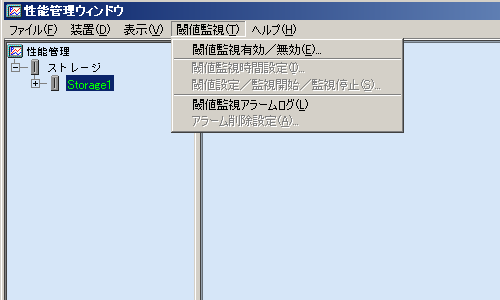
ここで、[閾値監視有効/無効(E)]を選択してください。これにより閾値監視有効となり各種閾値監視設定が可能となります。
[閾値監視時間設定(I)]を選択することで閾値監視時間帯の設定が行なえます。設定を行なわない場合はすべての時間帯での閾値監視およびアラームとしてイベントログに表示されます。閾値設定内容によっては閾値監視アラームログが大量に報告される場合が考えられます。閾値監視時間設定は対象装置の使われ方により負荷状態が大きく変化するようなシステム環境におきましては性能が最も気になる時間帯の設定をお勧めします。
次に[閾値設定/監視開始/監視停止(S)]を選択し、対象装置の閾値設定情報を設定し、監視開始を指示します。これにより、閾値監視が開始されます。なお、閾値監視部は性能管理部と共に運用管理サーバのデーモンとして起動されるため、運用管理サーバ起動中はGUI画面の起動なしに閾値監視を続けます。また、閾値設定情報の設定に関しては「B.10.6 閾値監視ダイアログ機能説明」を参照ください。
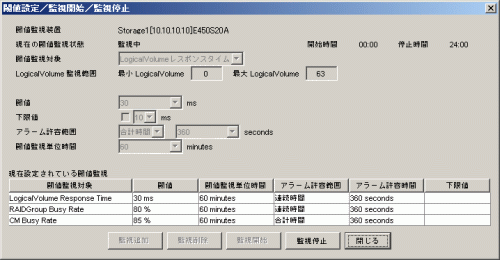
閾値監視アラームログを表示する場合は性能管理ウィンドウを起動し、メニューの閾値監視を選択し、リストが表示されますので、[閾値監視アラームログ(L)]を選択することにより起動できます。閾値監視で検出されたアラームログのリストが表示されます。性能管理ウィンドウは、GUI画面のメニューの[ファイル(F)]-[性能管理ウィンドウ(W)]の選択によって起動されます。
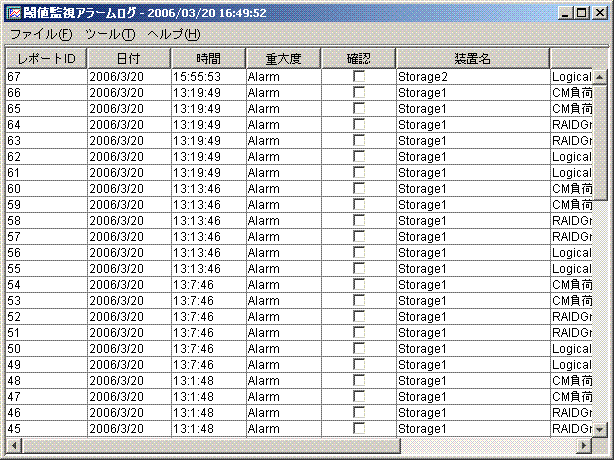
[閾値監視アラームログ(L)]で表示されたリストの詳細内容が表示されます。このレポートログ表示により各々の閾値監視アラームに対する対策指針を知ることができます。閾値監視アラームログの参照したいレポート行にマウスを合わせ、左ダブルクリックすることで表示されます。
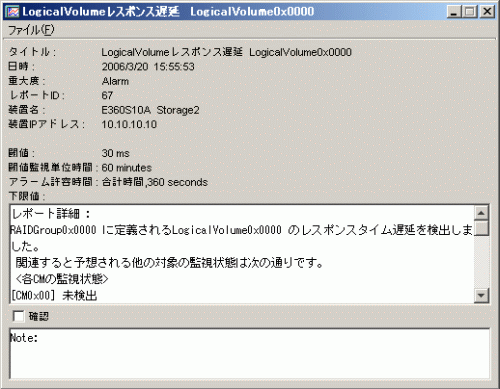
GUI画面の性能管理ウィンドウのメニューの[閾値監視(T)]を選択し、[閾値設定/監視開始/監視停止(S)]を選択します。表示される閾値設定画面の<監視停止>ボタンにて指示します。
ストレージにおける閾値について
ストレージにおける閾値の目安を以下に示します。
|
|
オンラインレスポンス重視システム |
バッチスループット重視システム |
|
LogicalVolumeレスポンス |
30msec以下 |
- |
|
RAIDGroupビジー率 |
60%以下 |
80%以下 |
|
CMビジー率 |
80%以下 |
90%以下 |
オンライン業務のようなレスポンス重視のシステムでは、LogicalVolumeレスポンスを30msec以内に収めることが、ストレージを快適に使用する一つの目安になります。レスポンスを30msec以下にするためには、RAIDGroupビジー率を60%以下、CMビジー率を80%以下に抑えてください。
バッチ業務のようなスループット重視のシステムでは、シーケンシャルアクセスによりキャッシュヒット率が高くなるため、LogicalVolumeのレスポンスは数msecとなります。ただし、キャッシュヒット率はアプリケーションのアクセスに大きく影響されるため値の変動が激しくなります。その結果レスポンスも数msec~50msec以上となることもあるので、バッチ業務の場合、LogicalVolumeレスポンスの閾値の目安はありません。
バッチ業務においてスループットを高くするためには、ストレージの資源を最大限に使用することが必要となりますが、上記の閾値を超えた場合、急激な性能低下となる可能性があります。従って、バッチ業務において、RAIDGroupビジー率80%以下、CMビジー率90%以下を目安にして下さい。
なお、アドバンスト・コピー実行中の時間帯では、アドバンスト・コピー処理自体によりCMビジー率が高くなります。
その場合は、アドバンスト・コピー実行も加味した上で、閾値設定を行ってください。
スイッチのポートにおける閾値について
「閾値」、「下限値」は対象スイッチのタイプ(1Gbpsまたは2Gbps)によって変わります。1Gbpsタイプであれば「100MB/s」、2Gbpsタイプであれば「200MB/s」が最大値(使用率100%の値)となります。設定する閾値は、最大値に対して何%の使用を許容範囲とするか、を指定します。
例えば、2Gbpsタイプのスイッチの閾値として「90%」を指定した場合、
200MB/s×90%=180MB/s(受信・送信の合計)
これがスループットの閾値となります。スループットが180MB/sに達した場合にアラームが上がります。
スイッチポートの閾値監視は、サーバ側のパス数とストレージ側のパス数に差がある場合に有効です。
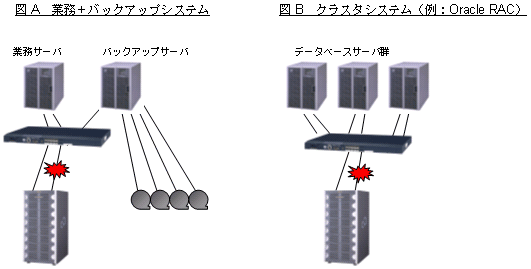
以下に、閾値監視の使用例を示します。
どのようなケースにおいて、どのような設定を行なうべきか等、閾値監視の考え方としてご参照ください。
ケース1:架空A社様 オンライン業務システムの場合
|
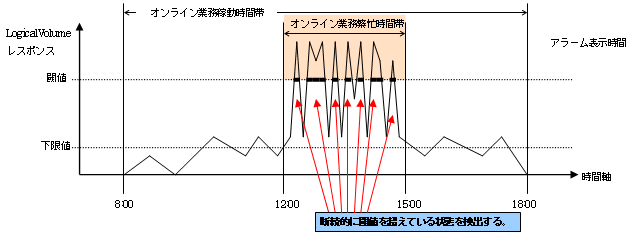
|
資料1に対応する番号 |
設定項目 |
設定値(設定内容) |
|---|---|---|
|
1 |
閾値監視時間 |
8:00-18:00 |
|
2 |
アラーム表示時間 |
12:00-15:00 |
|
3 |
閾値監視対象 |
LogicalVolumeレスポンス |
|
3 |
閾値 |
30msec |
|
4 |
閾値監視単位時間 |
60分 |
|
4 |
アラーム許容範囲 |
合計時間 360秒 |
|
5 |
下限値 |
10msec |
|
6 |
アラーム表示頻度 |
日毎 |
ケース2:架空B社様 オンラインショッピングシステムの場合
|
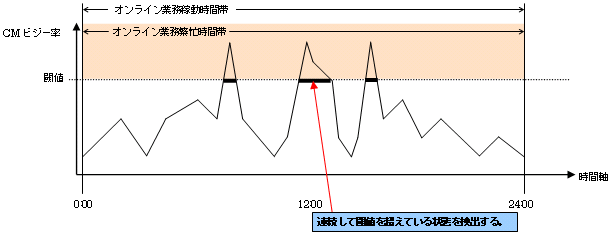
|
資料2に対応する番号 |
設定項目 |
設定値(設定内容) |
|---|---|---|
|
1 |
閾値監視時間 |
0:00-24:00 |
|
2 |
アラーム表示時間 |
0:00-24:00 |
|
3 |
閾値監視対象 |
CMビジー率 |
|
3 |
閾値 |
60% |
|
4 |
アラーム許容範囲 |
連続時間 300秒 |
|
5 |
アラーム表示頻度 |
すべて |
|
資料2に対応する番号 |
設定項目 |
設定値(設定内容) |
|---|---|---|
|
1 |
閾値監視時間 |
0:00-24:00 |
|
2 |
アラーム表示時間 |
0:00-24:00 |
|
3 |
閾値監視対象 |
RAIDGroupビジー率 |
|
3 |
閾値 |
80% |
|
4 |
アラーム許容範囲 |
連続時間 300秒 |
|
5 |
アラーム表示頻度 |
すべて |
ケース3:架空C社様 複数DBサーバ(クラスタシステム)によるバッチ処理運用の場合
|
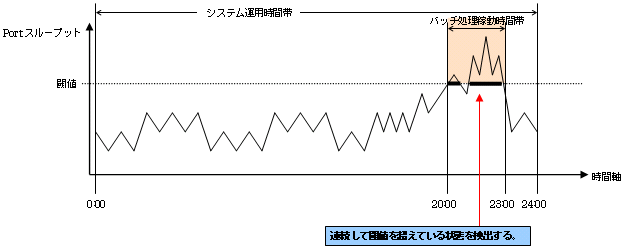
|
資料3に対応する番号 |
設定項目 |
設定値(設定内容) |
|---|---|---|
|
1 |
閾値監視時間 |
0:00-24:00 |
|
2 |
アラーム表示時間 |
20:00-23:00 |
|
3 |
閾値監視対象 |
Portスループット |
|
3 |
閾値 |
80% |
|
4 |
アラーム許容範囲 |
連続時間 1800秒 |
|
5 |
アラーム表示頻度 |
監視時間毎 |
|
レポート詳細: |
|
高負荷状態検出 |
同じ時間帯でCM負荷異常としてアラームログが作成されています。レスポンス遅延を検出したLogicalVolumeの担当CMが『高負荷状態検出』の場合、CMネックによるレスポンス遅延の可能性があります。当該CMのアラームの対策指針を行ってください。 |
|
監視継続中 |
アラームとして検出されてはいませんが、何度か閾値を超えて、アラーム検出のため監視中の状態です。 |
|
未検出 |
【CMビジー率が監視対象になっている場合】 |
|
【CMビジー率が監視対象になっていない場合】 |
|
高負荷状態検出 |
同じ時間帯でRAIDGroup負荷異常としてアラームログが作成されています。RAIDを構成するDiskネックによるレスポンス遅延の可能性があります。当該RAIDGroupのアラームの対策指針を行ってください。 |
|
監視継続中 |
アラームとして検出されてはいませんが、何度か閾値を超えて、アラーム検出のため監視中の状態です。 |
|
未検出 |
【RAIDGroupビジー率が監視対象になっている場合】 |
|
【RAIDGroupビジー率が監視対象になっていない場合】 |
|
レポート詳細: |
|
レポート詳細: |
|
高負荷状態検出 |
同じ時間帯で当該CMもCM負荷異常としてアラームログが作成されています。 |
|
監視継続中 |
アラームとして検出されてはいませんが、何度か閾値を超えて、アラーム検出のため監視中の状態です。 |
|
未検出 |
同じ時間帯で当該CMはネックにはなっていません。 |
業務とアドバンスト・コピーが競合している場合、CMは非常に高負荷状態になります。
この場合は、例えば業務負荷が比較的少ない時間帯にアドバンスト・コピーを実行する等の運用見直し、 あるいはコピー元、コピー先ボリューム(RAIDGroup)の担当CMが同一である時には担当CM変更(各々 別のCMに設定する)等の対処も必要となります。
|
レポート詳細: |
|
目次
索引
|