ロードシェア運用を行う場合、以下の点を考慮して設計してください。
ノード間通信で使用する装置について
Symfoware Serverのノード間通信は、クラスタシステムのクラスタインタコネクトを使用します。そのため、クラスタインタコネクトの通信インタフェースにイーサーネット(TCP/IP)を使用する場合は、高速転送が可能なギガビットインタフェース対応製品を使用してください。
ロードシェア運用を行うためには、以下の運用を行っている必要があります。
スケーラブルログ運用
スケーラブルディレクトリ運用
Capitalシステムは、クラスタシステムを構成する主なノードに運用系のCapitalシステムを配置し、それ以外のノードに待機系のCapitalシステムを配置してください。
Capitalシステムは、システムロググループを配置し、RDBディクショナリを管理します。
Satelliteシステムに待機系は必要ありません。
Satelliteシステムは、ユーザロググループを配置し、データベースを管理します。
ダウンした場合、ユーザロググループを他のノードに引き継ぎます。
ノードダウンが発生した場合、この単位で処理を引き継ぎます。
ユーザロググループは、ロードシェアシステム全体で、1600-1個定義できます。
ユーザロググループの配置先を設計します。
ロードシェアシステム起動時、各RDBシステムは“配置先”に指定されたユーザロググループを担当します。ノード故障などでRDBシステムがダウンした場合、“引継ぎ先”に指定されたRDBシステムが、当該ユーザロググループを引き継いで担当します。
ユーザロググループの配置先および引継ぎ先の設定は、ロードシェア構成パラメタファイルで行います。詳細については、“7.4.13 Capitalシステム用のロードシェア構成パラメタファイルの編集”を参照してください。
以下に、予備ノードがない場合と、予備ノードがある場合の例を示します。
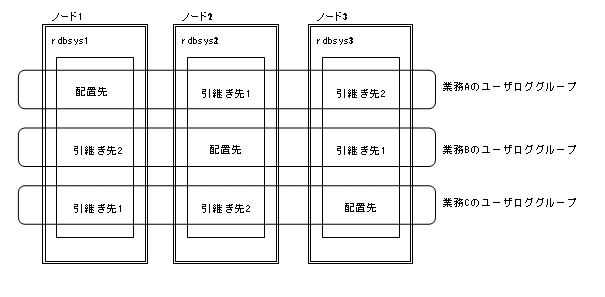
以下の図の例では、ロードシェアシステム起動時はrdbsys1が業務Aのユーザロググループを、rdbsys2が業務Bのユーザロググループを、rdbsys3が業務Cのユーザロググループをそれぞれ担当します。例えばこの状態でrdbsys1がダウンした場合、rdbsys2かrdbsys3のいずれかが業務Aのユーザロググループを担当しますが、業務Aのユーザロググループの引継ぎの優先順位はrdbsys2が“引継ぎ先1”、rdbsys3が“引継ぎ先2”のため、優先順位が高いrdbsys2が業務Aのユーザロググループを引き継いで担当します。
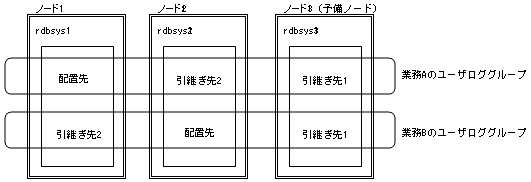
以下の図の例では、ロードシェアシステム起動時はrdbsys1が業務Aのユーザロググループを、rdbsys2が業務Bのユーザロググループをそれぞれ担当し、rdbsys3は予備ノードとなります。例えばこの状態でrdbsys1がダウンした場合、rdbsys2かrdbsys3のいずれかが業務Aのユーザロググループを担当しますが、業務Aのユーザロググループの引継ぎの優先順位はrdbsys2が“引継ぎ先2”、rdbsys3が“引継ぎ先1”のため、優先順位が高いrdbsys3が業務Aのユーザロググループを引き継いで担当します。
縮退やダウンリカバリを高速に行いたい場合は、以下の機能を利用してください。ただし、以下の機能を利用しない場合よりも容量を必要とするため注意が必要です。正しく見積りを行ってから利用してください。
引継ぎ先ノードでのDSIの事前メモリ常駐
フラッシュトリートメントリカバリ
詳細は、“1.6.4 引継ぎの高速化”を参照してください。
縮退後にもSymfoware/RDBが動作可能なように値を設定してください。
OS資源(カーネル編集)
多重度(RDB構成パラメタファイルのRDBCNTNUM)、および、共用メモリサイズ(RDB構成パラメタファイルのRDBEXTMEM)
接続数(システム用の動作環境ファイルのMAX_CONNECT_SYSおよびMAX_CONNECT_TCP)
共用バッファ
カーネル編集、RDB構成パラメタファイル、システム用の動作環境ファイルの詳細については、“セットアップガイド”を参照してください。
共用バッファの詳細については、“8.5 共用バッファの設定”を参照してください。
ロードシェア運用では、アプリケーションやRDBコマンドがRDBディクショナリの定義情報にアクセスする場合、ノード間通信が発生します。このため、rdbpldicコマンドで事前に定義情報のメモリ展開を行うことを推奨します。
縮退が発生した場合にも、リカバリの実施が行えるように設計を行ってください。
バックアップの取得は、縮退が発生していない状態で行ってください。
また、Advanced Backup Controllerを利用する場合で、ストレージ管理製品と連携した運用を行う場合には、AdvancedCopy Managerの運用設計において、縮退時における運用継続を考慮する必要があります。
参照
バックアップしたファイルの配置先の詳細については、“1.8.4 ファイル配置の考慮点”を参照してください。
Advanced Backup Controllerを利用する場合で、ストレージ管理製品と連携する場合の、縮退時における運用継続についての詳細は、“ETERNUS SF AdvancedCopy Manager運用手引書”または“ETERNUS SF AdvancedCopy Manager 運用ガイド”を参照してください。
RDBディクショナリまたはRDBディレクトリファイルに入出力障害が発生した場合のフォールバック運用について
フォールバック運用に関して、以下の点を考慮してください。
参照
フォールバック運用については“RDB運用ガイド”を参照してください。
1つのSQL要求で大量のデータをノード間で送受信するような業務では、ノード間通信における通信バッファについて最適な通信性能が得られるよう、ロードシェアシステムを構成するすべてのRDBシステムで、ロードシェア構成パラメタファイルのRDBDWHINCOMに“YES”を指定してください。
詳細は、“7.4.13 Capitalシステム用のロードシェア構成パラメタファイルの編集”および“7.4.20 Satelliteシステム用のロードシェア構成パラメタファイルの編集”を参照してください。
ノードダウン後の性能を考慮したい場合は、各ノードの負荷が均等になるようにユーザロググループを設計してください。
設計するときには、以下の2つを考慮してください。
ユーザロググループ数
ユーザロググループで扱うデータ量
各ノードが担当するユーザロググループ数を均等にしてください。
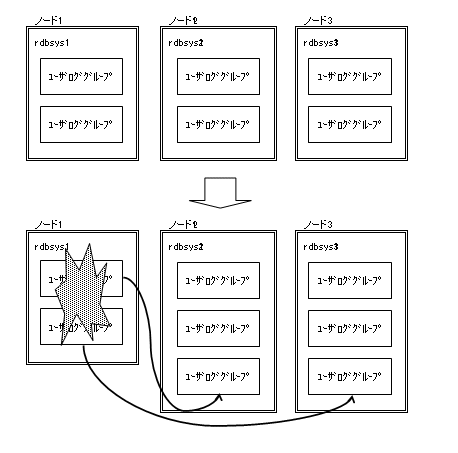
例えば、1つのSatelliteシステムに対して、“ロードシェアシステムを構成する全Satelliteシステム数 - 1”のユーザロググループを割り付けます。Satelliteシステムが3つ場合、1つのSatelliteシステムが最初に担当するユーザロググループは“2”になります。ロードシェアシステム全体では、“3(Satelliteシステム)×2(ユーザロググループ) = 6(ユーザロググループ)”となります。
この状態で縮退が発生した場合、ノードダウンが発生したSatelliteシステムが担当していた2つのユーザロググループを、生存している2つのSatelliteシステムに割り振ることにより、各Satelliteシステムのユーザロググループ数は3となり、均等にすることができます。
システム用の動作環境ファイルにWORK_PATHパラメタを指定してください。WORK_PATHパラメタに指定するディレクトリは、ローカルディスク上にRDBシステムごとに異なるディレクトリを作成する必要があります。なお、WORK_PATHに指定したディレクトリは、他で使用しないでください。