3つの具体的な例を用いて、抽出定義の定義例を説明します。
ここで示す3つの例は、“2.4.2 インデックス構造の例”と“2.6.2 Textアダプタ定義の例”の前提となります。
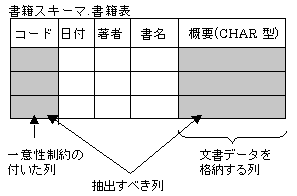
“図2.5 CHAR型の列の文書データを全文検索の対象とする場合”での表と列に対する前提を以下に示します。
CHAR型の「概要」列に全文検索の対象とする文書データを格納しています。「概要」列はCHAR型なので、格納される文書データは、テキスト文書に限定されます。
「コード」列に、一意性制約(PRIMARY KEY)が付いています。
「日付」列、「著者」列、「書名」列は、検索対象または検索結果の付随する情報として、利用者に返却されません。
この表が存在するデータベース名は「書籍データベース」、スキーマ名は「書籍スキーマ」、表名は「書籍表」です。
図2.5 CHAR型の列の文書データを全文検索の対象とする場合
以下に、上図での抽出定義の説明をします。
REPNAME = 書籍データ抽出定義 REPTYPE = TEXTADP DBMSKIND = SYMFO DATABASE = 書籍データベース SCHEMA = 書籍スキーマ TABLE = 書籍表 SELECT = コード,概要 LOGPATH = /home/work/logdata_db01 LOGSIZE = 1G,LARGE LOGTYPE = LITTLE
抽出定義名を「書籍データ抽出定義」としています。(REPNAME)
データベース名は、「書籍データベース」となります。(DATABASE)
スキーマ名は、「書籍スキーマ」となります。(SCHEMA)
表名は、「書籍表」となります。(TABLE)
定義項目SELECTでは、抽出する列名を列挙しますが、ここでは、検索対象とする文書データを格納した「概要」列に加え、一意性制約(PRIMARY KEY)の付いた「コード」列を指定します。
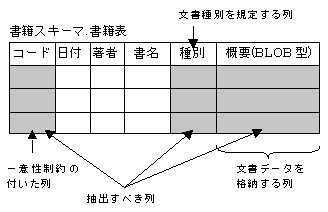
“図2.6 BLOB型の列の文書データを全文検索の対象とする場合(1)”での表と列に対する前提を以下に示します。
BLOB型の「概要」列に全文検索の対象とする文書データを格納しています。「概要」列はBLOB型なので、格納した文書データは、いくつかの文書種別をもつ可能性があります。文書種別には、テキスト文書/HTML文書/Word文書/OASYS for Windows文書/一太郎文書/Excel文書/PowerPoint文書/PDF文書があります。
「概要」列に格納した文書データの文書種別を規定する「種別」列をもちます。この列の値については、“2.2 データベースの表の設計”の文書種別を規定する例を参照してください。
「コード」列に、一意性制約(PRIMARY KEY)が付いています。
「日付」列、「著者」列、「書名」列は、検索対象または検索結果の付随する情報として、利用者に返却されません。
この表が存在するデータベース名は「書籍データベース」、スキーマ名は「書籍スキーマ」、表名は「書籍表」です。
図2.6 BLOB型の列の文書データを全文検索の対象とする場合(1)
以下に、上図での抽出定義の説明をします。
REPNAME = 書籍データ抽出定義
REPTYPE = TEXTADP
DBMSKIND = SYMFO
DATABASE = 書籍データベース
SCHEMA = 書籍スキーマ
TABLE = 書籍表
SELECT = コード,種別,概要
LOGPATH = /home/work/logdata_db01
LOGSIZE = 1G,LARGE
LOGTYPE = LITTLECHAR型の列の文書データを全文検索の対象とする場合と異なるのは、以下の点です。
定義項目SELECTで指定する列名として、「コード」列、「概要」列に加え、文書種別を規定する「種別」列を追加しています。これは、Textアダプタが、「種別」列の値を参照して、「概要」列の文書種別を判断するのに必要となります。
BLOB型の列の文書データを全文検索の対象とし、ほかの列のデータを検索結果に付随する情報と、付随する場合の例を以下に示します。
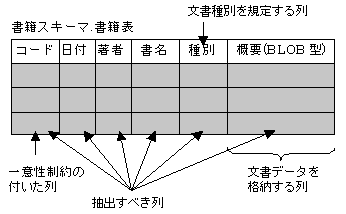
“図2.7 BLOB型の列の文書データを全文検索の対象とする場合(2)”での表と列に対する前提を、以下に示します。
BLOB型の「概要」列に全文検索の対象とする文書データを格納しています。「概要」列はBLOB型なので、格納した文書データは、いくつかの文書種別をもつ可能性があります。文書種別には、テキスト文書/HTML文書/Word文書/OASYS for Windows文書/一太郎文書/Excel文書/PowerPoint文書/PDF文書があります。
「概要」列に格納した文書データの文書種別を規定する「種別」列をもちます。この列の値については、“2.2 データベースの表の設計”の文書種別を規定する例を参照してください。
「コード」列に、一意性制約(PRIMARY KEY)が付いています。
定義項目SELECTで指定したすべての列が、検索対象または検索結果の付随する情報として、利用者に返却されます。
この表が存在するデータベース名は「書籍データベース」、スキーマ名は「書籍スキーマ」、表名は「書籍表」です。
図2.7 BLOB型の列の文書データを全文検索の対象とする場合(2)
以下に、上図での抽出定義の説明をします。
REPNAME = 書籍データ抽出定義 REPTYPE = TEXTADP DBMSKIND = SYMFO DATABASE = 書籍データベース SCHEMA = 書籍スキーマ TABLE = 書籍表 SELECT = コード,日付,著者,書名,種別,概要
LOGPATH=/home/work/logdata_db01 LOGSIZE = 1G,LARGE LOGTYPE = LITTLE
BLOB型の列の文書データを全文検索の対象とする場合(1)と異なるのは、以下の点です。
定義項目SELECTで指定する列名として、「コード」列、「種別」列および「概要」列に加え、検索対象または検索結果の付随する情報となる「日付」列、「著者」列および「書名」列も指定します。