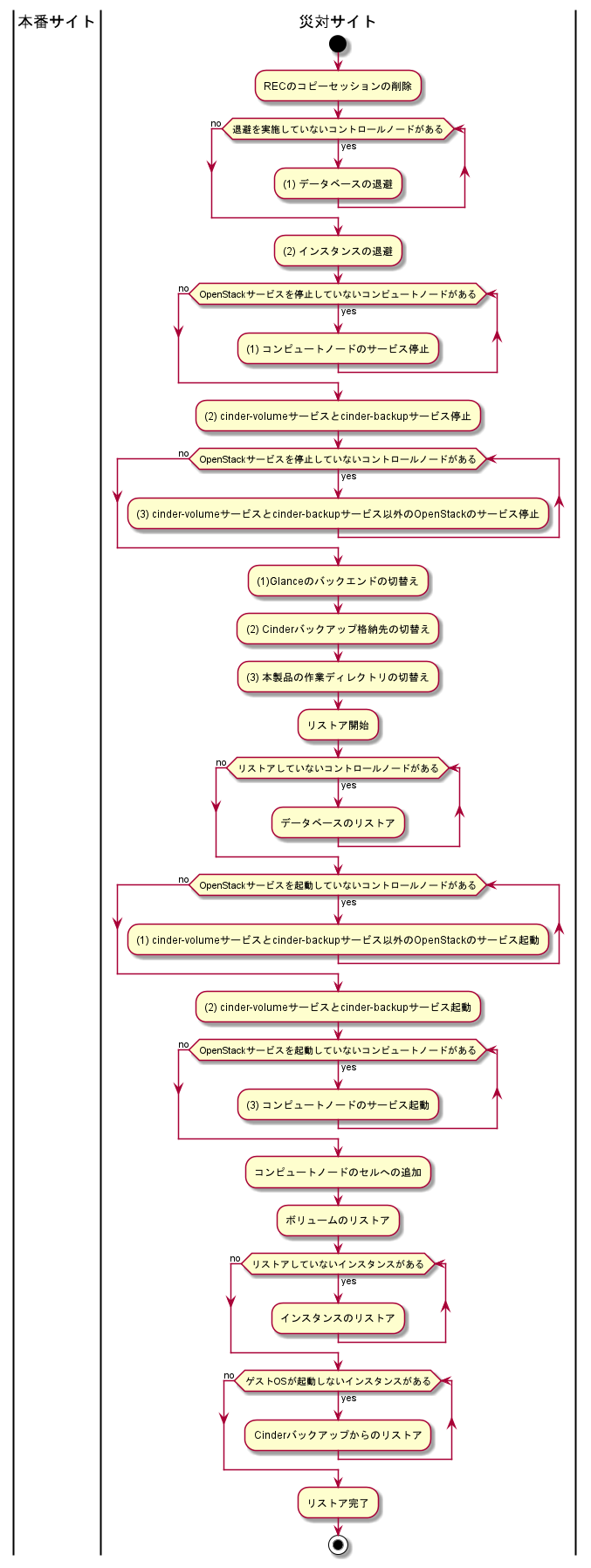
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : AdvancedCopy Manager CCMのインストール先サーバ
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
本番サイト、災対サイト間のRECをすべて停止します。
accopy fcancel -a <diskArrayName> -sa <srcDiskArrayName> -ta <dstDiskArrayName>
accopy fcancelコマンドの詳細は、AdvancedCopy Manager CCMのコマンドリファレンスを参照してください。
以下のコマンドを実行し、本製品の作業ディレクトリがマウントされていることを確認します。
# mount | grep /var/opt/FJSVrcxsr/mnt
上記コマンドは、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コントロールノードごとに1回
例
# mount | grep /var/opt/FJSVrcxsr/mnt 192.168.200.21:/var/nfs/siterecovery_kensyo on /var/opt/FJSVrcxsr/mnt type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=192.168.200.144,local_lock=none,addr=192.168.200.21)
本製品の作業ディレクトリがマウントされていない場合は、「本製品の作業ディレクトリの設定【サイト:災対サイト】」を実施してください。
以下のコマンドを実行し、データベースを退避します。
rcx_srosp_stash system
上記コマンドは、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
以下のコマンドを実行し、システムのバックアップを取得します。
rcx_srosp_stash instance
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
以下のコマンドを実行し、インスタンスの退避の詳細を確認します。
rcx_srosp_stash info
注意
データベースおよび、インスタンスを退避していない状態で本コマンドを実行した場合、インスタンス数および、ボリューム数の情報は表示されません。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコンピュートノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コンピュートノードごとに1回
以下のコマンドを実行し、OpenStackサービスを停止します。
systemctl stop tripleo_*.service
以下を参照し、サービスが停止したことの確認を実施してください。
「コンピュートノード」を確認してください。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
以下のコマンドを実行し、cinder-volumeサービスとcinder-backupサービスを停止します。
pcs resource disable openstack-cinder-volume openstack-cinder-backup
以下を参照し、サービスが停止したことの確認を実施してください。
「コントロールノード」を確認してください。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コントロールノードごとに1回
以下のコマンドを実行し、OpenStackサービスを停止します。
systemctl stop tripleo_*.service
以下を参照し、サービスが停止したことの確認を実施してください。
「コントロールノード」を確認してください。
注意
最後のコントロールノードのサービスの停止時に以下のようなメッセージが表示されますが 問題ありません。
Broadcast message from systemd-journald@<ホスト名> (時刻): haproxy[<プロセスID>]: proxy <プロキシ名> has no server available!
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コントロールノードごとに1回
Glanceのバックエンドに使用するNFS用ボリュームを「(2) コピー先ボリュームの作成【サイト:災対サイト】」で作成したコピー先のボリュームに切替えてください。
Glanceのバックエンドに使用するNFS用ボリュームの切替えに伴うGlanceの設定については、Red Hat OpenStack Platformのドキュメントを参照してください。
本手順で切り替える前の検証環境用のボリュームは「(1) Glanceバックエンドの切替え」で使用します。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コントロールノードごとに1回
Cinderのバックアップ格納先に使用するNFS用ボリュームを「(2) コピー先ボリュームの作成」で作成したコピー先のボリュームに切替えてください。
Cinderのバックアップ格納先に使用するNFS用ボリュームの切替えに伴うCinderの設定については、Red Hat OpenStack Platformのドキュメントを参照してください。
本手順で切り替える前の検証環境用のボリュームは「(2) Cinderバックアップ格納先の切替え」で使用します。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コントロールノードごとに1回
本製品の作業ディレクトリに使用するNFS用ボリュームを「(2) コピー先ボリュームの作成」で作成したコピー先のボリュームに切り替えてください。
本手順で切り替える前の検証環境用のボリュームは「(2) Cinderバックアップ格納先の切替え」で使用します。
以下のディレクトリに、本製品の作業ディレクトリとして、NFS共有をマウントします。
ディレクトリ
/var/opt/FJSVrcxsr/mnt
すべてのコントロールノードで同じNFS共有をマウントしてください。
OS起動時に自動的にマウントするには、/etc/fstabに設定を記載してください。
/etc/fstabの記載例
server:/remote/export /var/opt/FJSVrcxsr/mnt nfs defaults 0 0
/etc/fstabの構文についてはOSのドキュメントを参照してください。
以下のコマンドを実行し、本製品の作業ディレクトリがマウントされていることを確認します。
# mount | grep /var/opt/FJSVrcxsr/mnt
上記コマンドは、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コントロールノードごとに1回
例
# mount | grep /var/opt/FJSVrcxsr/mnt 192.168.200.21:/var/nfs/siterecovery on /var/opt/FJSVrcxsr/mnt type nfs4 (rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=192.168.200.144,local_lock=none,addr=192.168.200.21)
本製品の作業ディレクトリがマウントされていない場合は、「(3) 本製品の作業ディレクトリの切替え」を実施してください。
以下のコマンドを実行し、リストアするバックアップデータを指定します。
rcx_srosp_restore begin <backup_name>
上記コマンドは、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コントロールノードごとに1回
以下のコマンドを実行し、データベースをリストアします。
rcx_srosp_restore system
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コントロールノードごとに1回
以下のコマンドを実行し、起動対象のOpenStackサービスを確認します。
systemctl list-unit-files tripleo_*.service | awk '$2=="enabled"{print $1}'
以下のコマンドを実行し、OpenStackサービスを起動します。NAMEには上記で確認したサービスを入れてください。
systemctl start NAME...
以下を参照し、サービスが起動したことの確認を実施してください。
「コントロールノード」を確認してください。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
以下のコマンドを実行し、cinder-volumeサービスとcinder-backupサービスを起動します。
pcs resource enable openstack-cinder-volume openstack-cinder-backup
以下を参照し、サービスが起動したことの確認を実施してください。
「コントロールノード」を確認してください。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : すべてのコンピュートノード
手順実施ユーザー : インフラ管理者
手順実施回数 : コンピュートノードごとに1回
以下のコマンドを実行し、起動対象のOpenStackサービスを確認します。
systemctl list-unit-files tripleo_*.service | awk '$2=="enabled"{print $1}'
以下のコマンドを実行し、OpenStackサービスを起動します。NAMEには上記で確認したサービスを入れてください。
systemctl start NAME...
以下を参照し、サービスが起動したことの確認を実施してください。
「コンピュートノード」を確認してください。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
以下の手順に従い、コンピュートノードをセルに追加します。
以下のコマンドを実行し、nova_apiコンテナにログインします。
podman exec -it nova_api bash
以下のコマンドを実行し、コンピュートノードをセルに追加します。
nova-manage cell_v2 discover_hosts --by-service --verbose
例
# nova-manage cell_v2 discover_hosts --by-service --verbose Found 2 cell mappings. Skipping cell0 since it does not contain hosts. Getting computes from cell 'default': a7c8e84b-d4a6-4383-bead-ecbb41a7ea6a Creating host mapping for service <hostname-0> Creating host mapping for service <hostname-1> Found 2 unmapped computes in cell: a7c8e84b-d4a6-4383-bead-ecbb41a7ea6a
以下のコマンドを実行し、コンピュートノードがセルに追加されたことを確認します。
nova-manage cell_v2 list_hosts
例
# nova-manage cell_v2 list_hosts +-----------+--------------------------------------+--------------------------------------+ | Cell Name | Cell UUID | Hostname | +-----------+--------------------------------------+--------------------------------------+ | default | a7c8e84b-d4a6-4383-bead-ecbb41a7ea6a | <hostname-0> | | default | a7c8e84b-d4a6-4383-bead-ecbb41a7ea6a | <hostname-1> | +-----------+--------------------------------------+--------------------------------------+
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
以下のコマンドを実行し、ボリュームを一括でリストアします。
rcx_srosp_restore volume
リストア済みボリュームの確認方法は「リストア済みボリュームの確認」を参照してください。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : リストアするインスタンス台数分
以下のコマンドを実行し、インスタンスをリストアします。
rcx_srosp_restore instance <instance_id>
<instance_id>は、「(1) NovaインスタンスにアタッチされたCinderボリュームのバックアップ」および 「(1) NovaインスタンスにアタッチされたCinderボリュームのバックアップ」 で控えたものを使用してください。
<instance_id>がわからない場合は「リストア前のNovaインスタンスidを控え忘れた場合」を参照し <instance_id>を確認してください。
注意
定義ファイルの記載内容に誤りがある場合
rcx_srosp_restore instanceコマンドを実行する際に、以下の定義ファイルの内容をすべて検証するため、<instance_id>に指定されたインスタンス以外のインスタンスの定義に誤りがある場合もエラーが出力されます。その場合、「メッセージ」の対処に従って、定義ファイルを見直してください。
/etc/opt/FJSVrcxsr/instance_port_sequences_main.json
復旧済みのインスタンスが残っている場合
復旧済みのインスタンスが残っている場合、rcx_srosp_restore instanceコマンドを実行してもインスタンスはリストアされません。 本手順を実施する前に、以下の手順を参照し、復旧済みインスタンスを削除してください。
openstack server delete <instance_id>
<instance_id>にはrcx_srosp_restore instanceコマンド実行時に出力されたIDを指定してください。
上記コマンド実行後、インスタンス削除が完了したことを確認します。以下のコマンドを実行し、出力がないことを確認してください。
openstack server list --all-projects | grep <instance_id>
<instance_id>にはrcx_srosp_restore instanceコマンド実行時に出力されたIDを指定してください。 出力がある場合、インスタンス削除はまだ完了していないので、しばらく待ってから再度確認してください。
※上記コマンドを実行するために、admin権限を持つOpenStackユーザーのクレデンシャルファイル(ここではopenrcとします)を読み込むことが必要です。クレデンシャルファイルについては「OpenStackコマンドの実行について」を参照してください。
インスタンス削除完了後に、「残存ポートの削除」に記載される手順を参照し、残存ポートの有無を確認してください。 ポートが残存する場合は、手順に従い、ポートを削除してください。
リストア済みインスタンスの確認方法は「リストア済みインスタンスの確認」を参照してください。
本手順は、インスタンスのリストア後に、ゲストOSが起動しなかった場合などに、Cinderバックアップからインスタンス(ボリューム)を復旧します。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : リストアするインスタンス台数分
以下のコマンドを実行し、Cinderバックアップからインスタンスをリストアします。
rcx_srosp_restore instance <instance_id> --from-backup
注意
復旧済みのインスタンスが残っている場合、rcx_srosp_restore instanceコマンドを実行してもインスタンスはリストアされません。 本手順を実施する前に、以下の手順を参照し、復旧済みインスタンスを削除してください。
openstack server delete <instance_id>
<instance_id>にはrcx_srosp_restore instanceコマンド実行時に出力されたIDを指定してください。
上記コマンド実行後、インスタンス削除が完了したことを確認します。以下のコマンドを実行し、出力がないことを確認してください。
openstack server list --all-projects | grep <instance_id>
<instance_id>にはrcx_srosp_restore instanceコマンド実行時に出力されたIDを指定してください。 出力がある場合、インスタンス削除はまだ完了していないので、しばらく待ってから再度確認してください。
※上記コマンドを実行するために、admin権限を持つOpenStackユーザーのクレデンシャルファイル(ここではopenrcとします)を読み込むことが必要です。クレデンシャルファイルについては「OpenStackコマンドの実行について」を参照してください。
インスタンス削除完了後に、「残存ポートの削除」に記載される手順を参照し、残存ポートの有無を確認してください。 ポートが残存する場合は、手順に従い、ポートを削除してください。
リストア済みインスタンスの確認方法は「リストア済みインスタンスの確認」を参照してください。
本手順は、以下の条件で実施してください。
手順実施サイト : 災対サイト
手順実施サーバ : メイン作業用コントロールノード
手順実施ユーザー : インフラ管理者
手順実施回数 : 1回
以下のコマンドを実行し、リストアを完了します。
rcx_srosp_restore end