コード変換ポリシーとは、コード変換に必要となる以下の情報を集約したものです。
変換に必要な情報
変換元、変換先のコード系種別と文字セット
変換のカスタマイズ情報
エラー時の動作指定
変換できないデータの扱いと動作
文字を代替する場合の代替文字コード
コード変換ポリシー作成作業に入る前にこれらの情報を策定しておきます。策定の際には、それぞれ以下を参照してください。
コード系種別や文字セットについての詳細は、“コード系種別と文字セットについて”を参照してください。
変換のカスタマイズの検討に際しては、“変換仕様について”を参照してください。
エラー時の動作についての詳細は、“変換エラー時の動作について”を参照してください。
コード変換ポリシーはConverterライブラリの入力となり、Converterライブラリはコード変換ポリシーに従ってコード変換を行います。
また、コード変換ポリシーは複数作成できます。各コード変換ポリシーは、固有の文字コード変換IDを持っており、Converterライブラリでコード変換を行うときには、文字コード変換IDを指定します。
Charset Converterによって定義された、コード系種別と文字セットの概念を説明します。
コード系種別とは、大まかな文字コード体系の種別を表すものです。一方、文字セットは各コード系種別での文字の集合の大きさを表します。概念的には、以下の図のように捉えられます。
図2.2 コード系種別と文字セット
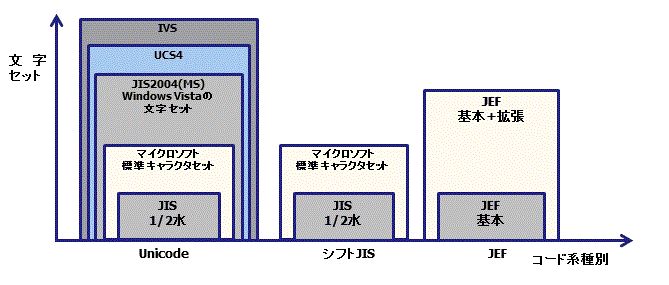
Charset Converterがサポートするコード系種別と、それぞれの有効な文字セットは以下のとおりです。
コード系種別 | 有効な文字セット | 説明 |
|---|---|---|
Unicode | MS932 | Unicodeを表す。 一部の記号はMS方式のマッピングを使用。 |
MS932ex | ||
UCS2 | ||
2004MS | ||
UCS4 | ||
UCS4_IVS | ||
SJIS | MS932 | シフトJISを表す。 |
EUC@EUC_JP | S90 | 日本語EUCを表す。 |
U90 | ||
JEF_ASCII | JEF | JEFコードを表す。半角文字としてはEBCDIC(ASCII)を利用する。 |
JEF_KANA | JEF | JEFコードを表す。半角文字としてはEBCDIC(カナ)を利用する。 |
KEIS | KEIS | 日立ホストで使用されるKEISコードを表す。 |
JIPS_J | JIPS | NECホストで使用されるJIPS(J)コードを表す。半角文字としてはJIS8単位コードを利用する。 |
JIPS_JE | JIPS | NECホストで使用されるJIPS(J)コードを表す。半角文字としてはEBCDIC(カナ)を利用する。 |
JIPS_E | JIPS | NECホストで使用されるJIPS(E)コードを表す。半角文字としてはEBCDIC(カナ)を利用する。 |
DBCS_HOST_ASCII | DBCS_HOST | IBMホストで使用されるDBCS-Hostコードを表す。半角文字としてはEBCDIC(ASCII)を利用する。 |
DBCS_HOST_KANA | DBCS_HOST | IBMホストで使用されるDBCS-Hostコードを表す。半角文字としてはEBCDIC(カナ)を利用する。 |
文字セット | 説明 |
|---|---|
MS932 | - マイクロソフト標準キャラクタセット - 利用者定義文字(1880文字) |
MS932ex | JIS90ベースのMS 明朝(Version2.31)で使用されている以下の文字セット。 - JIS補助漢字(JIS X 0212) - JIS X 0221 日本文字部分レパートリで定義される JAPANESE NON IDEOGRAPHICS SUPPLEMENT(追加非漢字集合)等 - 利用者定義文字(6400文字) |
UCS2 | UCS-2すべて |
2004MS | JIS2004ベースのMS 明朝(Version5.30)で使用されている以下の文字セット。 - JIS X 0212:1990 - JIS X 0213:2004 - JIS X 0221(JAPANESE NON IDEOGRAPHICS SUPPLEMENT)等 - 利用者定義文字(6400文字) |
UCS4 | - UCS-4(0~16面) |
UCS4_IVS | - UCS-4(0~16面) - UCS-4(0~16面)+VS(Variation Selector) ※ VSの有効範囲は「U+E0100~U+E01EF」 |
S90 | - JIS8(JISローマ字・JISカタカナ文字) - JIS非漢字 - JIS第一・第二水準 - 外字 |
U90 | - JIS8(JISローマ字・JISカタカナ文字) - JIS非漢字 - JIS第一・第二水準 - OASYS拡張文字 - 拡張漢字 - 拡張非漢字 - 外字 |
JEF | - JIS非漢字 - JIS第一・第二水準 - 拡張漢字 - 拡張非漢字 - 外字 - EBCDIC(ASCII)、EBCDIC(カナ) |
KEIS | - EBCDIC(カナ) - JIS非漢字 - JIS第一・第二水準 - KEIS拡張漢字 - KEIS拡張非漢字 - 外字 ※上記には、KEIS2004固有の文字は含まれません。 |
JIPS | - JIS8単位/EBCDIC(カナ) - JIS非漢字 - JIS第一・第二水準 - JIPS拡張漢字 - JIPS拡張非漢字 - 外字 ※2バイト文字は、G0集合、G1集合が対象になります。 |
DBCS_HOST | - EBCDIC(ASCII)/EBCDIC(カナ) - JIS非漢字 - JIS第一・第二水準 - IBM拡張漢字 - IBM拡張非漢字 - 外字 |
参考
IVSの利用方法については、"The Unicode Standard"の"Variation Selectors"および"Unicode Technical Standard #37"を参照してください。
Charset Converterで有効なコード変換の組み合わせは以下のとおりです。
コード系種別 | Uni | SJIS | EUC@ | JEF_ | JEF_ | KEIS | JIPS_J | JIPS_JE | JIPS_E | DBCS_ | DBCS_ |
|---|---|---|---|---|---|---|---|---|---|---|---|
Unicode | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
SJIS | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
EUC@EUC_JP | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
JEF_ASCII | ○ | ○ | ○ | - | - | - | - | - | - | - | - |
JEF_KANA | ○ | ○ | ○ | - | - | - | - | - | - | - | - |
KEIS | ○ | ○ | ○ | - | - | - | - | - | - | - | - |
JIPS_J | ○ | ○ | ○ | - | - | - | - | - | - | - | - |
JIPS_JE | ○ | ○ | ○ | - | - | - | - | - | - | - | - |
JIPS_E | ○ | ○ | ○ | - | - | - | - | - | - | - | - |
DBCS_HOST_ASCII | ○ | ○ | ○ | - | - | - | - | - | - | - | - |
DBCS_HOST_KANA | ○ | ○ | ○ | - | - | - | - | - | - | - | - |
○:組み合わせ可、-:組み合わせ不可
コード系種別と指定可能なエンコーディング形式の対応関係は以下のとおりです。
コード系 | 入力エンコーディング形式 | 出力エンコーディング形式 | 説明 |
|---|---|---|---|
Unicode | UTF-8 | UTF-8 | 【入力エンコーディング形式】 UTF-8(UTF-8)(注1) UCS-2(UCS-2、エンディアン自動判別)(注2) UCS-2BE(UCS-2、ビッグエンディアン) UCS-2LE(UCS-2、リトルエンディアン) UTF-16(UTF-16、エンディアン自動判別)(注2) UTF-16BE(UTF-16、ビッグエンディアン) UTF-16LE(UTF-16、リトルエンディアン) UTF-32(UTF-32、エンディアン自動判別)(注2) UTF-32BE(UTF-32、ビッグエンディアン) UTF-32LE(UTF-32、リトルエンディアン) 【出力エンコーディング形式】 UTF-8(UTF-8、BOMなし) UTF-8_BOM(UTF-8、BOM付き) UCS-2BE(UCS-2、ビッグエンディアン、BOMなし) UCS-2BE_BOM(UCS-2、ビッグエンディアン、BOM付き) UCS-2LE(UCS-2、リトルエンディアン、BOMなし) UCS-2LE(UCS-2、リトルエンディアン、BOM付き) UTF-16BE(UTF-16、ビッグエンディアン、BOMなし) UTF-16BE_BOM(UTF-16、ビッグエンディアン、BOM付き) UTF-16LE(UTF-16、リトルエンディアン、BOMなし) UTF-16LE_BOM(UTF-16、リトルエンディアン、BOM付き) UTF-32BE(UTF-32、ビッグエンディアン、BOMなし) UTF-32BE_BOM(UTF-32、ビッグエンディアン、BOM付き) UTF-32LE(UTF-32、リトルエンディアン、BOMなし) UTF-32LE_BOM(UTF-32、リトルエンディアン、BOM付き) |
SJIS | Shift_JIS | Shift_JIS | シフトJISのエンコーディング形式 |
EUC@EUC_JP | EUC-JP | EUC-JP | 日本語EUC(EUC_JP)のエンコーディング形式 |
JEF_ASCII | JEF | JEF | 富士通ホストで利用されている、JEFのエンコーディング形式 |
KEIS | KEIS | KEIS | 日立ホストで利用されている、KEISのエンコーディング形式 |
JIPS_J | JIPS(J) | JIPS(J) | NECホストで利用されている、JIPS(J)のエンコーディング形式 |
JIPS_E | JIPS(E) | JIPS(E) | NECホストで利用されている、JIPS(E)のエンコーディング形式 |
DBCS_HOST_ASCII | DBCS-Host | DBCS-Host | IBMホストで利用されている、DBCS-Hostのエンコーディング形式 |
注1:BOMなしのみサポートしています。BOMは"ZERO WIDTH NO-BREAK SPACE"として処理します。
注2:BOMでリトルエンディアン/ビッグエンディアンを判別します。BOMがない場合はエラーとなります。
次に示すエンコーディング形式は、文字のエンコーディングにシフトコードを使用します。
JEF
KEIS
JIPS(J)
JIPS(E)
DBCS-Host
各エンコーディング形式に対するシフトコードについては、“Charset Manager 使用手引書 標準コード変換機能編”の“付録E ホストコード系のシフトコード”を参照してください。
変換仕様について
Charset Converterは、以下の二つの利用ケースを想定しています。
システム間データ流通用の文字コードとしてUnicodeを用いるケース
Unicodeを使わずJIS領域ベースで各コード系間を流通させるケース
一般的に、後者は策定が楽な反面、流通する文字数が制限され、システム間で字形が異なる、といった問題があり、前者は逆の特徴を持っています。これらに対応するため、製品既定のコード対応定義には以下の特徴があります。
Unicodeと他のコード系の間の変換では、字形に基づいた対応定義になっています。
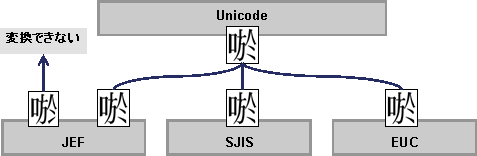
Unicode以外のコード系同士の変換では、JIS領域ベースに基づいた対応定義になっています。
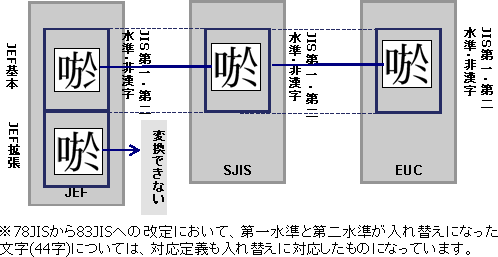
Unicodeをシステム間データ流通に用いるケースで、Unicode以外のコード系間でもデータ流通が行われる場合、製品既定のままでは全体のデータ流通に矛盾が発生するケースがあります。例えば、JEF→SJIS→Unicode→JEFといった経路のデータ流通においては、下記のように一巡すると文字コードが変わってしまう問題があります。
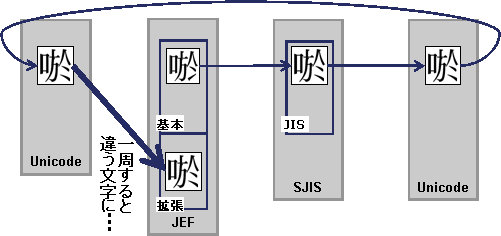
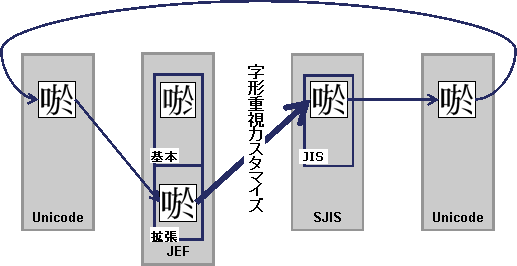
このような場合には、JEF-SJIS間の対応定義に対して、字形重視カスタマイズを行います。方法については“3.1.2 コード変換ポリシー定義ファイル”のUserTableFileの説明を参照してください。
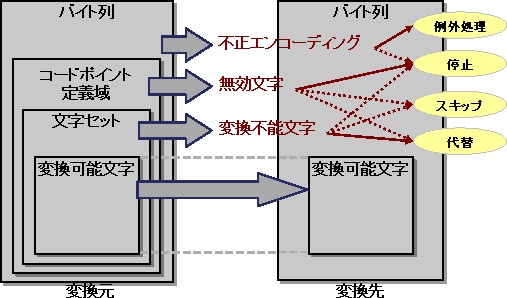
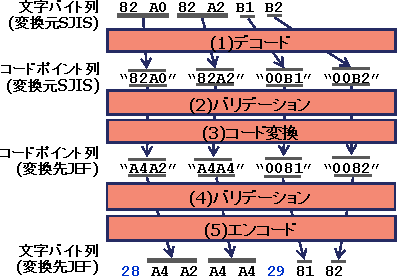
変換元、及び変換先の文字データについて、コード系種別・文字セットが定められると、これらの情報を元にConverterライブラリは下記のように動作します。
図2.3 Converterライブラリの動き
この動きの段階で、変換できないデータは以下の三つに分類されます。
これに対して、プログラムの動作を以下のように指定することができます。
指定可能な組合せは以下のようになります。
プログラム動作→ 変換エラー↓ | 代替 | スキップ | 停止 | 例外処理 |
|---|---|---|---|---|
不正エンコーディング | × | × | ○ | ◎ |
無効文字 | ○ | ○ | ◎ | × |
変換不能文字 | ◎ | ○ | ○ | × |
◎:既定値、○:選択可能、×:指定不可
図2.4 変換エラーとプログラム動作