コード変換ポリシー定義ファイルはテキストファイルで、以下の形式で指定します。
FileEncoding=Shift_JIS
ID=Charset-Conversion-Policy
Version=1.0
# コード変換ID
ConversionID=KEIRI-UNI_TO_JINJI-JEF
# 変換元文字セット
SourceConverterKeyword=Unicode(UCS2)
# 変換元無効コードポイント
SourceInvalidCode=\
0000-001F, \ # 制御コードを無効化
EC1E-F8FF # 3102文字以降の外字を無効化
# 変換先文字コード系
DestinationConverterKeyword=JEF_ASCII(JEF)
# 変換先無効コードポイント
DestinationInvalidCode=\
0000-003F # 制御コードを無効化
# 製品規定の対応定義の使用
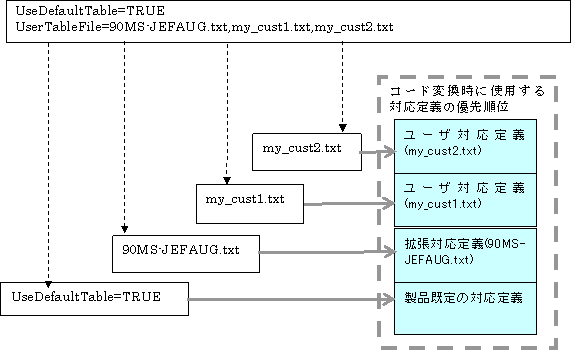
UseDefaultTable=TRUE
# ユーザ対応定義ファイル
UserTableFile=usertable.txt以下のルールに従います。
1行1定義とし、定義の終了は、改行またはEOFになります。
定義の構成要素には、キー句、値句、コメント句があります。キー句、値句に指定できる文字列については、“コード変換ポリシー定義ファイルのキー句と値句”を参照してください。コメント句は、#で始まる文字列です。
行の種類とその構成は以下のとおりです。
キー句+区切り記号+値句から成る行です。区切り記号は"="です。
キー句+区切り記号+値句+コメント句から成る行です。
コメント句から成る行です。
0回以上の空白記号の連続から成る行です。空白記号とは、半角空白、タブを指します。
行頭とコメント句の前にある空白記号は無視されます。
同じキー句を2個以上定義すると、エラーになります。
キーは大文字小文字を区別します。
値句を複数行に連続して記載したい場合には、改行をエスケープ"\"してください。
コード変換ポリシー定義ファイルのキー句と値句
本設定ファイルのファイルエンコーディングを指定します。本キーは必ず1行目に指定してください。値句は大文字小文字を区別します。指定できる値は以下のとおりです。
文字列 | 意味 |
|---|---|
Shift_JIS | シフトJISエンコーディングであることを示します。 |
ファイル識別子を指定します。省略はできません。値句は大文字小文字を区別します。指定できる値は以下のとおりです。
文字列 | 意味 |
|---|---|
Charset-Conversion-Policy | コード変換ポリシー定義ファイルであることを示します。 |
ファイルのバージョンを指定します。省略はできません。指定できる値は以下のとおりです。
文字列 | 意味 |
|---|---|
1.0 | バージョン1.0であることを示します。 |
文字コード変換IDを指定します。文字コード変換IDとは、変換ポリシーを指定するためのID文字列として使用します。省略はできません。
文字コード変換IDは以下のルールに従って、任意に命名してください。
使用できる文字は英数字と半角アンダースコア「_」、ハイフン「-」です。
英大文字・小文字は同一視されます。
長さは50文字までです。
変換元のConverterキーワードを指定します。省略はできません。指定できる値については、“表3.1 Converterキーワードとコードポイントの表記方法”を参照してください。大文字・小文字は同一視されます。
変換元の文字セットの中の特定のコードポイントを無効としたい場合に、そのコードポイントを指定します。コードの指定方法については、“表3.1 Converterキーワードとコードポイントの表記方法”を参照してください。
変換元の文字セットに、コードポイントを追加します。コードポイントの指定方法については、“表3.1 Converterキーワードとコードポイントの表記方法”を参照してください。このキーワードはSourceConverterKeywordのコード系種別がUnicodeのときのみ有効です。利用できるコードポイント範囲はU+0000~U+10FFFFで、SourceInvalidCodeに指定されたコードポイントと指定が重複する場合、そのコードは無効文字となります。
例
Unicode2面の文字すべてを文字セットに加えるには以下のようにします。
SourceAdditionalBasecode=20000-2FFFF
変換先のConverterキーワードを指定します。省略はできません。指定できる値については、“表3.1 Converterキーワードとコードポイントの表記方法”を参照してください。大文字・小文字は同一視されます。
変換先の文字セットの中の特定のコードポイントを無効としたい場合に、そのコードポイントを指定します。コードの指定方法については、“表3.1 Converterキーワードとコードポイントの表記方法”を参照してください。
変換先の文字セットに、コードポイントを追加します。コードポイントの指定方法については、“表3.1 Converterキーワードとコードポイントの表記方法”を参照してください。このキーワードはDestinationConverterKeywordのコード系種別がUnicodeのときのみ有効です。利用できるコードポイント範囲はU+0000~U+10FFFFで、DestinationInvalidCodeに指定されたコードポイントと指定が重複する場合、そのコードは無効文字となります。
製品既定の対応定義を有効とするかどうかを指定します。製品既定の対応定義とは、標準コード変換機能の標準の変換対応(カスタマイズせずに変換した場合)と同等です。変換内容については、“Charset Manager 使用手引書 標準コード変換機能編”の“付録A 標準の変換対応と縮退文字一覧”、“付録B 他社ホストコード系との変換対応と縮退文字一覧”を参照してください。
以下のいずれかを指定します。省略した場合、TRUEの扱いとなります。
文字列 | 意味 |
|---|---|
TRUE | 製品既定の対応定義を有効とします。 |
FALSE | 製品既定の対応定義は無効とし、UserTableFileキーで指定された対応定義のみが使用されます。この場合、UserTableFileキーを省略すると、変換できるコードが0となり、警告が表示されます。 |
コード変換をカスタマイズするためのユーザ対応定義ファイル、または拡張対応定義ファイルのファイル名を指定します。ここに指定されたファイル名は下記の2つのディレクトリより検索されます。ファイル名が重複した場合にはa)のディレクトリが優先になります。
コード変換ポリシー定義ファイル(本ファイル)と同じディレクトリ
ユーザ対応定義ファイルを配置します。形式については、“対応定義ファイル形式”を参照してください。
Charset Managerインストールディレクトリ\converter\data\extra
製品に添付された拡張対応定義ファイルが格納されています。詳細については、“拡張対応定義ファイルについて”を参照してください。
なお、ファイル名はカンマ区切りで5つまでの複数指定が可能です。複数指定した場合、同じコードに対する設定は後の指定が有効となります。
例
以下のように指定した場合、各ファイルの対応定義の優先順位関係は以下のようになります。
コード変換ができない文字を、変換先のコード系において、どのコードポイントで代替出力するかを指定します。省略した場合、代替文字は変換先のコードでのアンダースコア文字になります。デフォルトの代替文字のコードポイントについては、“代替文字について”を参照してください。
以下のように指定します。
<16進コードポイント値>
例
Alternative=3013
各コード系種別におけるコードポイントの表記法については、“表3.1 Converterキーワードとコードポイントの表記方法”を参照してください。
コード変換ができない半角文字を、変換先のコード系において、どのコードポイントで代替出力するかを指定します。OperationForInconvertibleCharにALTERNATEを指定した場合に、有効となります。指定方法はAlternativeと同様となります。このパラメタを省略した場合、代替文字は変換先のコードでの半角アンダースコア文字になります。デフォルトの代替文字のコードポイントについては、“代替文字について”を参照してください。
なお、変換元コード系種別で半角として扱われる文字の定義についても、“代替文字について”を参照してください。
変換元の文字列に、不正エンコーディングが検出された場合の動作を指定します。以下のいずれかを指定します。大文字小文字を区別します。省略した場合、EXCEPTIONの扱いとなります。
文字列 | 意味 |
|---|---|
EXCEPTION | 例外を発生させます。(C言語インタフェースの場合、STOPと同じ動作になります) |
STOP | 処理を中断します。 |
SourceConverterKeywordキー、DestinationConverterKeywordキーに指定できるキーワードと、キーワードごとのコードポイントの表記方法については、以下のとおりです。コード系種別と文字セットについては、“表2.1 コード系種別一覧”を参照してください。
Converterキーワード | コード系種別 | 文字セット | コードポイントの表記方法 |
|---|---|---|---|
Unicode(MS932) | Unicode | MS932 | UCSのコードポイント値を利用します。例えば、U+2000Bのコードポイントは2000Bとなります。 IVSはConverterキーワードが IVSは、基底文字のコードの直後にアンダースコア(‘_’)を記述し、続いてVSのコードポイントを記載します。 VSは、E0100からE01EFをサポートします。 例)基底文字 U+8FBB、VS U+E0100の文字のコードポイントは8FBB_E0100となります。 |
Unicode(MS932ex) | MS932ex | ||
Unicode(UCS2) | UCS2 | ||
Unicode(2004MS) | 2004MS | ||
Unicode(UCS4) | UCS4 | ||
Unicode(UCS4_IVS) | UCS4_IVS | ||
SJIS(MS932) 注1) | SJIS | MS932 | SJISコード値そのものがコードポイントとなります。例えば、'A'→0041、'あ'→82A0 |
EUC@EUC_JP(S90) 注2) | EUC@EUC_JP | S90 | EUCコード値そのものがコードポイントとなります。3バイトの補助漢字も同様です。(8FA1A1など) |
EUC@EUC_JP(U90) 注2) | U90 | ||
JEF_ASCII(JEF) | JEF_ASCII | JEF | 1バイト文字はEBCDIC(ASCII)コード、2バイト文字はJEFコードがそれぞれコードポイントとなります。 |
JEF_KANA(JEF) | JEF_KANA | JEF | 1バイト文字はEBCDIC(カナ)コード、2バイト文字はJEFコードがそれぞれコードポイントとなります。 |
KEIS(KEIS) | KEIS | KEIS | 1バイト文字はEBCDIC(カナ)コード、2バイト文字はKEISコードがそれぞれコードポイントとなります。 |
JIPS_J(JIPS) | JIPS_J | JIPS | 1バイト文字はJIS8単位コード、2バイト文字はJIPS(J)コードがそれぞれコードポイントとなります。 |
JIPS_JE(JIPS) | JIPS_JE | 1バイト文字はEBCDIC(カナ)、2バイト文字はJIPS(J)コードがそれぞれコードポイントとなります。 ※JIPS_Eの場合も、コードポイント表現としてJIPS(J)コードを使用します。 | |
JIPS_E(JIPS) | JIPS_E | ||
DBCS_HOST_ASCII(DBCS_HOST) | DBCS_HOST_ASCII | DBCS_HOST | 1バイト文字はEBCDIC(ASCII)コード、2バイト文字はDBCS-Hostコードがそれぞれコードポイントとなります。 |
DBCS_HOST_KANA(DBCS_HOST) | DBCS_HOST_KANA | 1バイト文字はEBCDIC(カナ)コード、2バイト文字はDBCS-Hostコードがそれぞれコードポイントとなります。 |
注意
Shift_JISエンコーディング形式が扱う2バイト文字の各バイトの値の範囲は、次の通りです。この条件に合致しない場合、不正エンコーディングとして扱います。
第1バイト : 0x81~0x9F および 0xE0~0xFC 第2バイト : 0x40~0x7E および 0x80~0xFC
EUC-JPエンコーディング形式が扱う2バイト、3バイト文字の各バイトの値の範囲は、次の通りです。この条件に合致しない場合、不正エンコーディングとして扱います。
2バイト文字
第1バイト : 0x8E および 0xA1~0xFE 第2バイト : 0xA1~0xFE
3バイト文字
第1バイト : 0x8F 第2バイト : 0xA1~0xFE 第3バイト : 0xA1~0xFE
SourceInvalidCodeキー、SourceAdditionalBasecodeキー、DestinationInvalidCodeキー、およびSourceAdditionalBasecodeキーのコードの指定方法は以下のとおりです。
コードは16進数で、6桁までの半角英数字で記述してください。
大文字、小文字は区別しません。
指定するコードは、SourceConverterKeywordキー、DestinationConverterKeywordキーに指定したConverterキーワードに対応するコードポイントの表記方法に従ってください。詳しくは、“表3.1 Converterキーワードとコードポイントの表記方法”を参照してください。
IVSはConverterキーワードが”Unicode(UCS4)”または"Unicode(UCS4_IVS)"の場合のみ記述することができます。
IVSは、基底文字のコード直後に'_'を記述し、続いてVSのコードポイントを記載します。
ハイフン(-)を使ってIVSの連続するコード範囲を指定する場合は、基底文字とVSを別々に指定(「(基底文字の範囲指定)_(VSの範囲指定)」の形式で指定)します。VS無しの基底文字とIVSを同時に範囲指定できません。
VSは、E0100からE01EFをサポートします。
最終コードを省略した場合、先頭コード1文字を対象範囲とします。
カンマで区切って複数範囲を指定することができます。
例
E000からE010までの場合
E000-E010
E000とE010の場合
E000,E010
E000からE010とE020の場合
E000-E010,E020
8FBAと8FBA E0100の場合
8FBA,8FBA_E0100
8FBA E0100と8FBA E0101と8FBB E0100と8FBB E0101の場合
8FBA-8FBB_E0100-E0101
変換元と変換先のコードを定義するテキストファイルです。以下のルールに従って作成します。
ファイルのエンコーディングはコード変換ポリシー定義ファイルに従います。
変換元コードポイントと変換先コードポイントを、一行ごとに記述します。
変換元コードポイント、変換先コードポイントとも、任意桁数の16進数を指定します。ゼロサプレス指定も任意です。
変換元コードポイントと変換先コードポイントの間はタブで区切ります。
コードポイントはソートされている必要はありません。
標準の対応定義を削除する場合には、変換先コードポイントに”_NONE_”を指定します。
同じ変換元コードポイントが2つ以上定義された場合、後から出現した方が有効となります。
例
E000\tE000 E001\tE001 E002\t3013 E003\t3013 E004\t3013 E008\t_NONE_ …
拡張対応定義ファイルについて
製品に添付されている拡張対応定義ファイルは以下のとおりです。
注意
JIS2004字形変更文字の詳細については、“Charset Manager 使用手引書 標準コード変換機能編”の“A.3 JIS2004字形変更文字の対応”を参照してください。
参考
同等の変換を行う標準コード変換の設定について
拡張対応定義ファイルで用意されている変換と同等の変換を、Charset Managerの標準コード変換機能で行う場合の設定は以下のとおりです。標準コード変換機能については、“Charset Manager 使用手引書 標準コード変換機能編”を参照してください。
ただし、Charset ConverterではConverterキーワードとして指定した文字セットに応じて、対応定義範囲が狭められるため、Unicodeでは、標準コード変換とは同一の変換にならないことがあります。同一の変換を行う場合には、Unicodeの文字セットとしてUCS2を使用してください。
ファイル名 | 標準コード変換での設定 | ||
|---|---|---|---|
変換元キーワード | 変換先キーワード | サンプルの対応定義ファイル | |
90MS-U90.txt | Unicode系(注1) | U90 | - |
2004MS-U90.txt | Unicode系(注1) | U90 | U90_2004MSUni.CTL |
FUJ-U90.txt | Unicode系(注1) | U90 | U902FUNI.CTL |
2004MS-JEF.txt | Unicode系(注1) | jefkana または | JEFA_2004MSUni.CTL |
FUJ-JEF.txt | Unicode系(注1) | jefkana または | Jef2FUNI.ctl |
SJ90MS-JEFAUG.txt | sjisms | JEF字形重視(注2) | - |
SJ2004MS-JEFAUG.txt | sjisms | JEF字形重視(注2) | JEFA_2004MS.CTL |
S90-JEFAUG.txt | S90 | JEF字形重視(注2) | - |
U90-90MS.txt | U90 | Unicode系(注1) | - |
U90-2004MS.txt | U90 | Unicode系(注1) | U90_2004MSUni.CTL |
U90-FUJ.txt | U90 | Unicode系(注1) | U902FUNI.CTL |
JEFAUG-S90.txt | JEF字形重視(注2) | S90 | - |
JEF-2004MS.txt | jefkana または | Unicode系(注1) | JEFA_2004MSUni.CTL |
JEF-FUJ.txt | jefkana または | Unicode系(注1) | Jef2FUNI.ctl |
JEFAUG-SJ90MS.txt | JEF字形重視(注2) | sjisms | - |
JEFAUG-SJ2004MS.txt | JEF字形重視(注2) | sjisms | JEFA_2004MS.CTL |
S90-JIPSAUG.txt | S90 | N_JIPSJAUG または | - |
SJ-JIPSAUG.txt | sjisms | N_JIPSJAUG または | - |
JIPSAUG-S90.txt | N_JIPSJAUG または | S90 | - |
JIPSAUG-SJ.txt | N_JIPSJAUG または | sjisms | - |
2004MSA-U90.txt | Unicode系(注1) | U90 | U90_2004Uni.CTL |
2004UNI-JEF.txt | Unicode系(注1) | jefkana またはjefascii | JEFA_2004Uni.CTL |
U90-2004MSA.txt | U90 | Unicode系(注1) | U90_2004Uni.CTL |
JEF-2004UNI.txt | jefkana またはjefascii | Unicode系(注1) | JEFA_2004Uni.CTL |
注1)UCS2、UCS2LE、UTF8、UTF16BE、UTF16LE、UTF8_4のいずれか。
注2)jefkana、jefascii、jefaugkana、jefaugasciiのいずれか。ただし、jefkana、jefasciiの場合、変換仕様ユーティリティ、環境変数にて字形重視の設定が必要。
各コード系種別のデフォルト代替文字のコードポイント値と、半角として扱われるコードポイントの定義については以下のとおりです。
コード系種別 | 代替文字の既定値(コードポイント値) | 半角として扱われるコードポイント | |
|---|---|---|---|
デフォルト代替文字 | デフォルト半角文字用代替文字 | ||
Unicode | FF3F | 005F | 0000~007F, FF60~FF9Fの範囲のうち、文字セットUCS2に含まれるコードポイント。 |
SJIS | 8151 | 005F | 0000~00FFの範囲のうち、文字セットMS932に含まれるコードポイント。 |
EUC@EUC_JP | A1B2 | 005F | 0000~007F, 8EA1~8EDFの範囲のうち、文字セットS90に含まれるコードポイント。 |
JEF_ASCII | A1B2 | 006D | 0000~00FFのうち、EBCDIC(ASCII)として有効なコードポイント。 |
JEF_KANA | A1B2 | 006D | 0000~00FFのうち、EBCDIC(カナ)として有効なコードポイント。 |
KEIS | A1B2 | 006D | 0000~00FFのうち、EBCDIC(カナ)コードとして有効なコードポイント。 |
JIPS_J | 2132 | 005F | 0000~00FFのうち、JIS8単位コードとして有効なコードポイント。 |
JIPS_JE | 2132 | 006D | 0000~00FFのうち、EBCDIC(カナ)コードとして有効なコードポイント。 |
JIPS_E | 2132 | 006D | 0000~00FFのうち、EBCDIC(カナ)コードとして有効なコードポイント。 |
DBCS_HOST_ASCII | 426D | 006D | 0000~00FFのうち、EBCDIC(ASCII)コードとして有効なコードポイント。 |
DBCS_HOST_KANA | 426D | 006D | 0000~00FFのうち、EBCDIC(カナ)コードとして有効なコードポイント。 |