ここでは、スレーブサーバに異常が発生した際の動作について、説明します。
スレーブサーバで以下に示す異常が発生した場合、他のスレーブサーバが実行中のジョブを代替し、処理が継続されます。
システムの異常
業務 LAN ネットワークの異常
iSCSI ネットワークの異常
図16.3 スレーブサーバにおける異常発生から業務再開までの流れ
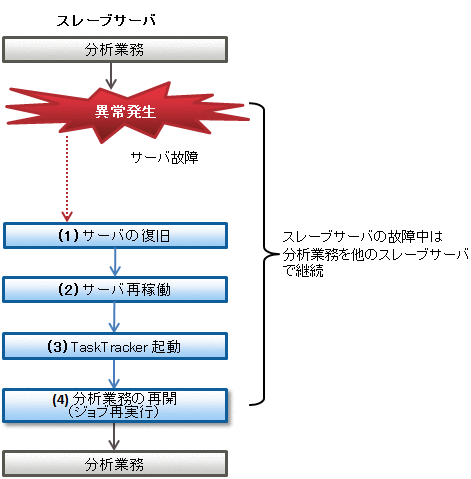
対象のスレーブサーバのシステムログなどを参照して異常の原因を調査し、取り除いてください。
システムログの参照やスレーブサーバの再起動だけでは解決できない重度の障害が発生した場合は、対象のスレーブサーバの復旧作業を行ってください。
スレーブサーバのリストア手順については、「15.2.1.2 スレーブサーバのリストア」を参照してください。
ポイント
リストアを行うためには、事前に正常稼働時のスレーブサーバのバックアップを採取している必要があります。
スレーブサーバのバックアップ手順については、「15.1.2.2 スレーブサーバのバックアップ」を参照してください。
スレーブサーバの復旧が完了した後、復旧を行ったスレーブサーバの再起動を行ってください。
スレーブサーバの復旧・再稼働が完了したあとは、マスタサーバから bdpp_start コマンドを実行し、異常となったスレーブサーバ上の Hadoop を再起動してください。
Hadoop の起動については、「A.14 bdpp_start」を参照してください。
注意
一部のスレーブサーバのHadoopを再起動するために、bdpp_start コマンドを実行した場合、"bdpp:WARN:001" メッセージが出力されますが、スレーブサーバの Hadoop の再起動には問題ありません。
スレーブサーバの復旧が完了したあとは、必要に応じてジョブの実行を行い、業務を再開してください。