Data Effectorで扱うCSV形式について、以下に説明します。
Data Effectorで扱うCSV形式は、レコード内の各項目の間はカンマ(,)で区切り、レコードの最後には改行を記述します。各項目は項目全体を二重引用符(")で囲うことができます。項目の内容としてカンマ(,)、改行を指定する場合は項目を囲う二重引用符を必ず記述します。項目の内容として二重引用符(")を指定する場合は、項目全体を二重引用符で囲い、項目の内容の二重引用符は、二重引用符を2つ続けて表現します。
先頭行に項目名を記述し、2行目以降にデータが格納されたファイルを、入力ファイルとして扱います。また、項目名の行だけを記述したファイルをスキーマ情報ファイルとして別に指定することで、項目名の行を持たない、データだけからなるファイルを扱うこともできます。
項目名だけの行を、見出し行と呼びます。データの行をデータ行と呼びます。1件のデータを1レコードと呼びます。
以下に、本マニュアルにおけるCSV形式の用語定義を示します。
図2.1 CSV形式の用語定義

データ中の1つの二重引用符(")は、二重引用符(")を2つ続けて表現します。
これは"データ"です。 → "これは""データ""です。" |
以下の図にCSV形式のファイルの例を示します。
"Kbn","Number","Code","Name","Value","Total","Biko" "01","1001","AAA","ブロックA","1,000","1,000","備考:稟議番号 第4023号" "02","1001","BBB","ブロックB","","1,200","備考:稟議番号 第4023号" "03","1002","CCC","ブロックC","800","800","備考:稟議番号 第4023号" |
注意
データファイル中の連続する二重引用符("")は、1文字としてカウントされます。
データ中にカンマ(,)が含まれる場合は、必ずその項目は二重引用符(")で括ります。
1,234,567 → "1,234,567" |
以下の図にCSV形式のファイルの例を示します。
Kbn,Number,Code,Name,Value,Total,Biko 01,1001,AAA,ブロックA,"1,000","1,000",備考:稟議番号 第4023号 02,1001,BBB,ブロックB,,"1,200",備考:稟議番号 第4023号 03,1002,CCC,ブロックC,800,800,備考:稟議番号 第4023号 |
二重引用符で囲んだデータの場合、項目間はカンマ(,)以外の文字があるとエラーになります。区切り文字のカンマ(,)の前後の余分な文字は、削除してください。
"AAA", "ブロックA" → "AAA","ブロックA" |
スキーマ情報ファイルに、項目名以外の情報が存在する場合、エラーとなります。
以下の図に、CSV形式のスキーマ情報ファイルとデータファイルの例を示します。
"Kbn","Number","Code","Name","Value","Total","Biko" |
"01","1001","AAA","ブロックA","1,000","1,000","備考:稟議番号 第4023号" "02","1001","BBB","ブロックB","","1,200","備考:稟議番号 第4023号" "03","1002","CCC","ブロックC","800","800","備考:稟議番号 第4023号" |
見出し行の項目数よりデータ行の項目数が少ないCSV形式のファイルを扱うことができます。この場合、不足している項目に空文字列が指定されているとみなして振舞います。
"項目1","項目2","項目3" "A1","A2","A3" "B1","B2" "C1" |
注意
CSV形式の1レコードの最大サイズは32メガバイトです。
抽出機能では、アンダーライン(_)だけの項目名が存在するファイルを扱えません。
Data Effectorでは、区切り文字として以下が使われている形式も扱うことができます。
なお、本書では、一般的なCSV形式および特殊なCSV形式をまとめて、CSV形式と定義します。
水平タブ
半角空白
"Kbn" "Number" "Code" "Name" "Value" "Total" "Biko" "01" "1001" "AAA" "ブロックA" "1,000" "1,000" "備考:稟議番号 第4023号" "02" "1001" "BBB" "ブロックB" "" "1,200" "備考:稟議番号 第4023号" "03" "1002" "CCC" "ブロックC" "800" "800" "備考:稟議番号 第4023号" |
区切り文字は、複数指定できます。また、2つ以上の連続した区切り文字を、1つの項目間の区切りとして扱うこともできます。
CSV形式の区切り文字を変更する場合、以下のパラメタで設定します。
コマンド利用時は、各動作環境ファイルのFieldSeparatorパラメタ
C API利用時は、AsisSetEnvironment関数の環境パラメタFieldSeparator
2つ以上の連続した区切り文字の扱いは、以下を設定することで動作します。
コマンド利用時は、各動作環境ファイルのFieldSeparatorModeパラメタ
C API利用時は、AsisSetEnvironment関数の環境パラメタFieldSeparatorMode
以下のような複数の半角空白を項目の区切りにしている入力ファイルを扱う場合について例を示します。入力データ例は、見やすさのために桁あわせしています。
なお、差異がわかりやすいように、処理の結果は表形式で記載しています。
"Number" "Name" "Value" "Biko" "1001" "ブロックA" "1,000" "備考:稟議番号 第4023号" "1002" "ブロックB" "" "備考:稟議番号 第4023号" "1003" "ブロックC" "800" "備考:稟議番号 第4023号" |
FieldSeparator "¥s" FieldSeparatorMode 1 |
FieldSeparatorに、"半角空白"を指定。
FieldSeparatorModeに、"2つ以上の連続した区切り文字を1つの項目間の区切りとして扱う"を指定。
Number | Name | Value | Biko |
|---|---|---|---|
1001 | ブロックA | 1,000 | 備考:稟議番号 第4023号 |
1002 | ブロックB | 備考:稟議番号 第4023号 | |
1003 | ブロックC | 800 | 備考:稟議番号 第4023号 |
注意
FieldSeparatorに指定した区切り文字がレコードの先頭にある場合には、1番目の項目に空文字列が指定されているとみなされます。
例えば、区切り文字に半角空白を設定し、レコードのデータが半角空白で開始している場合、1番目の項目はデータ無しとみなされます。
ポイント
特殊な形式の場合、出力時の区切り文字はリターン式を指定するかどうかで異なります。
リターン式 | 出力時の区切り文字 |
|---|---|
指定あり | カンマ |
指定なし | 入力ファイルと同じ形式 |
参照
FieldSeparatorパラメタの詳細については、以下を参照してください。
コマンド利用時は、“付録B コマンドリファレンス”
C API利用時は、“C.5.1 AsisSetEnvironment”
入力ファイル中に1件でも不当なデータ(以降、エラーデータと呼びます)を検出した場合、Data Effectorでは、エラーメッセージを出力して処理を中断します。そこで、CSV形式の入力ファイル中にエラーデータを検出した場合、処理継続を選択できる機能を提供します。検出したエラーは、専用のエラーデータ出力ファイルに出力されます。
本機能を使用することで、エラーデータは、エラーデータ出力ファイルを参照しながら後でまとめて修正できます。
入力ファイルのエラーデータ出力は、以下を設定することで動作します。
コマンド利用時は、各動作環境ファイルのErrFileパラメタ
C API利用時は、AsisSetErrFile関数
エラーデータ出力の対象ファイル
入力ファイル
入力ジャーナルファイル
入力マスタファイル
注意
スキーマ情報ファイルおよび見出し行は、エラーデータ出力の対象外です。
処理が継続できるエラーデータの内容
本機能では、エラーデータを含むデータを対象外にすることで、処理を継続します。
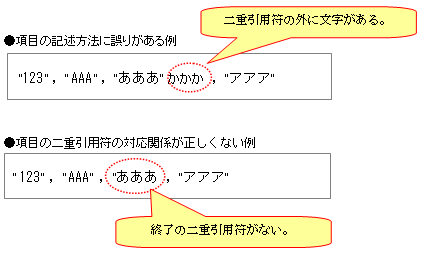
処理が継続可能となるエラーデータの例を以下に示します。
レコードの項目数が見出し行の項目数、または、スキーマ情報ファイルの項目数より多い。
項目の記述方法に誤りがある(二重引用符(")の外に文字がある)。
項目の二重引用符(")の対応関係が正しくない(開始に対する終了がない)。
図2.2 エラーデータの例
エラーデータ出力ファイルの形式
入力ファイル内にエラーデータを検出したときの、エラーデータ出力ファイルの形式を以下に示します。
図2.3 エラーデータ出力ファイルの形式

注意
システムロケールの文字コードとデータの文字コードが異なる場合
データの文字コード環境でエラーデータ出力ファイルを参照すると、入力ファイル名に半角英数字以外が含まれるとき、エラーデータ出力ファイルに出力される入力ファイル名が、文字化けすることがあります。
そのため、入力ファイル名には半角英数字を使うことを推奨します。
エラーデータ出力ファイルの例
入力ファイル内にエラーデータを検出したときの、エラーデータ出力ファイルの例を以下に示します。
入力ファイルの以下の箇所でエラーデータを検出した場合
入力ファイル名"data1.csv"の、200件目、350件目、375件目のレコード
入力ファイル名"data2.csv"の、150件目、210件目のレコード
![]() Windowsの場合
Windowsの場合
"D:¥indata¥data1.csv",200,"19980120","鈴木太郎","2201-1101","東京都千代田区",・・・ "D:¥indata¥data1.csv",350,"20012111","佐藤花子","2201-1204","大阪府大阪市阿倍野区",・・ "D:¥indata¥data1.csv",375,"19980120","鈴木太郎","2201-1101","神奈川県横浜市港北区",・・ "D:¥indata¥data2.csv",150,"20021010","田中一郎","2201-1010","愛知県名古屋市東区",・・ "D:¥indata¥data2.csv",210,"20071225",""山田愛","2201-1225","兵庫県神戸市",・・ |
![]()
![]() Linux/Solarisの場合
Linux/Solarisの場合
"/home/indata/data1.csv",200,"19980120","鈴木太郎","2201-1101","東京都千代田区",・・ "/home/indata/data1.csv",350,"20012111","佐藤花子","2201-1204","大阪府大阪市阿倍野区",・・ "/home/indata/data1.csv",375,"19980120","鈴木太郎","2201-1101","神奈川県横浜市港北区",・・ "/home/ndata/data2.csv",150,"20021010","田中一郎","2201-1010","愛知県名古屋市東区",・・ "/home/indata/data2.csv",210,"20071225",""山田愛","2201-1225","兵庫県神戸市",・・ |
FieldSeparatorパラメタに半角空白が指定されていて、入力ファイルの以下の箇所でエラーデータを検出した場合
入力ファイル名"data1.csv"の、200件目、350件目のレコード
![]() Windowsの場合
Windowsの場合
"D:¥indata¥data1.csv" "200" "19980120" "鈴木太郎" "2201-1101" "東京都千代田区" ・・・ "D:¥indata¥data1.csv" "350" "20012111" "佐藤花子" "2201-1204" "大阪府大阪市阿倍野区" ・・ |
![]()
![]() Linux/Solarisの場合
Linux/Solarisの場合
"/home/indata/data1.csv" "200" "19980120" "鈴木太郎" "2201-1101" "東京都千代田区" ・・ "/home/indata/data1.csv" "350" "20012111" "佐藤花子" "2201-1204" "大阪府大阪市阿倍野区" ・・ |
参照
本機能の詳細については、以下を参照してください。
コマンド利用時は、“付録B コマンドリファレンス”
C API利用時は、“C.5.2 AsisSetErrFile”
注意
本機能は、入力ファイルがXML形式の場合は、利用できません。
エラーデータ出力ファイルが出力された場合は、入力ファイルにエラーデータが含まれているため、正しい出力結果を得ることができません。入力ファイルの内容を確認して、再度処理を実行してください。
エラーデータ出力ファイルの区切り文字は、リターン式の指定の有無に関係なく、FieldSeparatorパラメタで指定した値になります。