1つのXML文書が1レコードとして管理されたファイルを、入力ファイルとして扱います。1ファイル内に複数のXML文書を連続して格納しておくことにより、1回の操作で複数のXML文書を取り扱えます。
Data Effectorで扱うXML文書は、整形式のXML文書(well-formed XML document)です。整形式のXML文書とは、XML文書の仕様に準拠するための以下の基準を満たした文書のことです。また、XML宣言やDTDなどの前書きがない、本文だけのXML文書も格納できます。
整形式の条件について記述します。
1つ以上の要素を含んでいる。
ルートと呼ばれる要素が1つ存在する。
ルートと呼ばれる要素以外の要素の開始タグが他の要素の内容の中に存在する場合には、終了タグも同じ要素の内容の中に存在する。
ポイント
要素とは、開始タグで始まり、終了タグで終わる単位です。
開始タグと終了タグの間に要素の内容があります。要素の内容が空である場合、空要素タグ(例:<Company/>)のように記述できます。Data Effectorでは、“<”で始まる文字をルート要素の開始タグ(ルートタグ名)とみなし、対応する終了タグまでをXML文書とします。XML文書内では空白、タグおよび改行などを含めたそのままの形式で扱います。
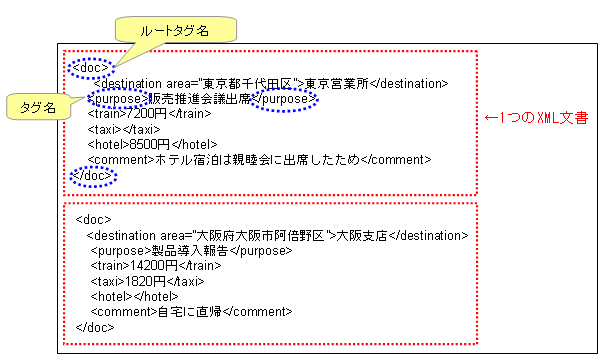
以下の図に、XML形式のレコードの例を示します。
図2.4 XML形式レコードの例
注意
以下の部分は抽出、連結、集計、およびソートの対象になりません。
XML宣言やDTDなどの前書きの部分
名前空間の値
コメント
処理命令
XML文書の内部実体展開、および、外部実体の展開は行いません。
XML文書の要素や属性の名前空間を認識しません。要素名や属性名が名前空間接頭辞で修飾された名前の場合、名前空間接頭辞とコロン(:)を含めたものを要素名、または属性名として扱います。
DTD宣言で指定した属性のデフォルト値での抽出はできません。
属性値の正規化(連続する半角空白、復帰文字、改行文字、水平タブを半角空白で置き換えること)は行いません。属性値はXML文書に記述されたままの状態で扱います。
開始タグ名と終了タグ名が異なるXMLデータに対しても、各階層を開始タグに記述されたタグ名で識別するため、正しいXML文書として許容しています。
1つの要素内に同じ属性名を重複して記述できます。抽出機能では、1つの要素内に同じ属性名が複数記述されている場合、どちらかの属性値に条件に一致する文字列または数値が含まれれば真となります。
XML文書の妥当性検証は実施しません。
XML形式の1レコードの最大サイズは32メガバイトです。
XML形式の入力ファイルでは、ルート要素に“!”で始まる名前を使用できません。