shunsortコマンドに対する入力ファイル、出力ファイルなどを記述します。
以下に、sort用動作環境ファイルの実行パラメタを示します。
注意
sort用動作環境ファイルの内容はシステムロケールの文字コードで記述してください。
パラメタ名は行の先頭から記述してください。
パラメタ名 | 省略 | 説明 |
|---|---|---|
可 | 入力ファイル、または入力ファイルが配置されたディレクトリを指定します。(注1) | |
可 | 入力ファイルの見出し行の扱いを指定します。 | |
OutFile | 可 | 出力ファイルを指定します。(注1) |
WorkFolder | 可 | 一時ファイルを格納する作業ディレクトリを指定します。(注1) |
LogFile | 可 | ログファイルを指定します。(注1) |
可 | 複数の入力ファイルを同時にソートするための並列数を指定します。 | |
可 | 出力データの中の文字列値を、二重引用符(")で括るかどうかを指定します。 | |
可 | 入力ファイルタイプがCSVの場合、項目間の区切り文字を二重引用符(")で囲んで指定します。 | |
可 | 入力ファイルタイプがCSVの場合、2つ以上の連続した区切り文字の扱いを指定します。 | |
可 | 入力ファイル中にエラーデータを検出したときの、エラーデータ出力ファイルを指定します。(注1) | |
可 | ユーザーが定義した関数(ユーザー定義関数)を使ってデータを処理する場合に指定します。 | |
可 | キー仕分け機能を使用する場合に指定します。 | |
ResultFolder(注5) | 不可 | キー仕分け機能を使用する場合、キー仕分けの結果を出力するフォルダを指定します。(注1) |
AlternativeName(注5) | 可 | キー仕分け機能を使用する場合、ファイル名に使用する代替文字を指定します。
本パラメタを省略した場合、“###”が指定されたとみなします。 |
OutLineFeedCode | 可 | 出力データにおける、レコード終端の改行コードの取り扱いを指定します。 LF : Lf(0x0A) |
注1) ファイル名、ディレクトリ名、またはフォルダ名に特殊な文字を指定する場合の扱いについては、 “パス名に指定する特殊な文字の扱い”を参照してください。
注2) キー仕分け機能を使用する場合(KeySortパラメタが“1”)、本パラメタは指定できません。
注3) キー仕分け機能を使用する場合(KeySortパラメタが“1”)、本パラメタは無効です。
注4) 英字を指定した場合、小文字としてファイル名に設定されます。
注5) キー仕分け機能を使用しない場合(KeySortパラメタが“0”または省略)、本パラメタは指定できません。
入力ファイル、または、入力ファイルが配置されたディレクトリを指定します。入力ファイルとディレクトリは、混在指定できます。
図1.33 入力ファイルタイプがCSVの場合
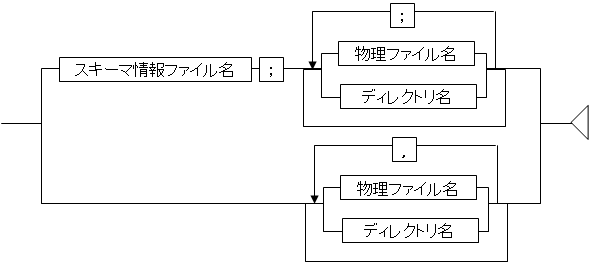
図1.34 入力ファイルタイプがXMLの場合
ソート条件ファイルのInFileTypeパラメタがCSVの場合に、入力ファイルの項目名を記述したスキーマ情報ファイルを指定します。
スキーマ情報ファイルに標準入力は指定できません。
入力ファイルを指定します。物理ファイル名またはディレクトリ名を指定しない場合(""を記述)、標準入力より入力します。
物理ファイル名の先頭に"pipe@"を記述することで、入力ファイルに名前付きパイプを指定できます。
入力ファイルが配置されたディレクトリを指定します。ディレクトリ名または物理ファイル名を指定しない場合(""を記述)、標準入力より入力します。
物理ファイル名とディレクトリ名の混在も指定可能です。
InFileパラメタの規約を以下に説明します。
本パラメタに物理ファイル名およびディレクトリ名を省略した場合は、標準入力より入力します。物理ファイルとディレクトリの混在も指定可能です。
標準入力だけを指定する場合は、二重引用符(")を指定してください(""を記述)。
ソート条件ファイルのInFileTypeパラメタがCSVの場合で、スキーマ情報を指定する場合は、スキーマ情報ファイル名と各物理ファイル名またはディレクトリ名をセミコロン(;)で接続します。
ソート条件ファイルのInFileTypeパラメタがCSVの場合で、スキーマ情報を指定しない場合は、各物理ファイル名またはディレクトリ名をカンマ(,)で接続します。
スキーマ情報を指定した場合、物理ファイル名またはディレクトリ名に指定した各ファイルの先頭行には項目名が記述されていないものとみなし、データとしてソート対象になります。
スキーマ情報を指定しない場合、物理ファイル名またはディレクトリ名に指定した各ファイルの先頭行には項目名が記述されているものとみなし、先頭行のデータをソート対象にしません。
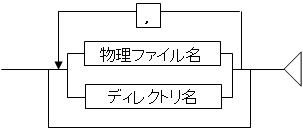
ソート条件ファイルのInFileTypeパラメタがXMLで複数のファイルまたはディレクトリを指定する場合には、各物理ファイル名またはディレクトリ名をカンマ(,)で接続します。
複数のファイルまたはディレクトリを指定する場合、カンマ(,)または(;)の前後に改行を記述できます。
本パラメタを複数行に分けて定義する場合や、ファイル名に空白が含まれる場合は、本パラメタに指定する値全体を二重引用符(")で囲う必要があります。
注意
スキーマ情報ファイルには、名前付きパイプを指定できません。ファイル名の先頭に"pipe@"を記述してもファイル名の一部と認識します。
入力の物理ファイルに名前付きパイプを指定する場合には、あらかじめ利用者が名前付きパイプを作成する必要があります。ただし、DataEffectorのコマンド間で名前付きパイプを使用する場合は、作成する必要はありません。
複数の物理ファイルに名前付きパイプを指定して並列に処理を実施する場合には、物理ファイルごとに別々の名前付きパイプを指定し、ParallelNumパラメタを指定してください。
ディレクトリ配下のファイルは、ファイル名でソートされた順番に処理されます。ただし、ParallelNumパラメタ指定時には、順番は保証されません。
ソート処理実行中に、指定されたディレクトリに対してファイルの追加、削除を実施した場合は、そのファイルが本機能に反映されない場合があります。
指定されたディレクトリが存在しない場合には、異常終了します。
指定されたディレクトリ配下にファイルが存在しない場合、または、処理すべきファイルが存在しない場合には、異常終了します。(ディレクトリが複数指定されていて、1つのディレクトリ配下にファイルが存在しなくても、他のディレクトリ配下にファイルが存在すれば、異常終了しません。)
指定されたディレクトリ直下のファイルだけが処理対象となります。サブディレクトリ配下のファイルは対象としません。
ディレクトリ配下の内容が以下の場合は、異常終了します。
名前付きパイプが存在する
Data Effectorとして処理対象外のファイルが存在する
参照
処理対象のファイルの種類については、“導入・運用ガイド”の“処理対象ファイルの種類”を参照してください。
入力ファイルの見出し行の扱いを指定します。
0: 見出し行を読み飛ばさない。
1: 見出し行を読み飛ばす。
本パラメタを省略した場合、0が指定されたものとみなします。
注意
本パラメタは、入力ファイルタイプがCSVの場合だけ有効です。
本パラメタは、入力定義ファイルにスキーマ情報ファイルが指定されている場合だけ有効です。指定されていない場合、先頭行は読み飛ばしません。
本パラメタは、すべての入力ファイルに対して有効になります。そのため、見出し行のある入力ファイルと、見出し行のない入力ファイルが混在している場合には使用できません。見出し行のない入力ファイルを指定した場合、先頭行を見出し行とみなして読み飛ばします。
出力ファイルを指定します。
注意
キー仕分け機能を使用する(KeySortパラメタが“1”)場合、本パラメタは指定できません。
図1.35 出力ファイルタイプがCSVの場合
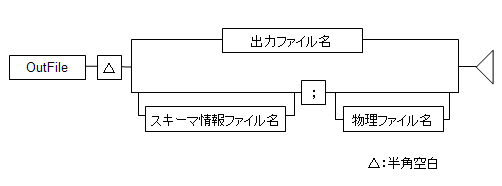
図1.36 出力ファイルタイプがXMLの場合

出力するファイル名を指定します。
出力ファイル名または物理ファイル名の先頭に"pipe@"を記述することで、名前付きパイプを指定できます。
出力ファイルタイプがCSVの場合で見出し行とデータ行を分けて出力したいときは、スキーマ情報ファイルと物理ファイル名に分けて指定してください。
注意
スキーマ情報ファイルと物理ファイルの扱い
指定の組合せと出力先を以下に示します。
指定例 | 出力先 | |
|---|---|---|
スキーマ情報ファイル | 物理ファイル | |
スキーマ情報ファイル名;物理ファイル名 | 指定したファイル | 指定したファイル |
;物理ファイル名 | 作成されない | 指定したファイル |
スキーマ情報ファイル名; | 指定したファイル | 標準出力 |
; | 作成されない | 標準出力 |
見出し行とデータ行に分けて標準出力へ出力することはできません。
スキーマ情報ファイル名と物理ファイル名には、セミコロン(;)を含むことはできません。
注意
名前付きパイプの扱い
スキーマ情報ファイルには、名前付きパイプを指定できません。ファイル名の先頭に"pipe@"を記述してもファイル名の一部と認識します。
出力ファイルに名前付きパイプを指定する場合には、利用者が名前付きパイプを作成する必要ありません。
コマンドの実行結果が出力されるまで、名前付きパイプは作成されないため、名前付きパイプが作成されるまでに時間がかかる場合があります。
OSのコマンドを使用して、Data Effectorのコマンドをキャンセルした場合、名前付きパイプのファイルが残る場合があります。この場合は、必要に応じてファイルを削除してください。
ソート処理において一時ファイルを格納する作業ディレクトリを指定します。
指定した作業ディレクトリに、以下の名前の一時ファイルが作成されます。一時ファイルは、ソート処理実行後に削除されます。
作成される一時ファイルの命名規約は、以下です。
一時ファイル:AsIs.[PID][TID][NO] |
[PID]:5桁の数字でプロセスIDを表します。
[TID]:10桁の数字でスレッドIDを表します。
[NO]:3桁の数字です。
本パラメタを省略した場合、OSで設定されている一時ディレクトリ(/tmpディレクトリ)を利用します。
注意
OSで設定されている一時ディレクトリが存在しない、または設定されていない場合、作業ディレクトリの指定を省略することはできません。
キー仕分け機能を使用する(KeySortパラメタが“1”)場合、本パラメタは指定できません。
本コマンドの実行中にキャンセルをした場合、作業ディレクトリ配下に一時ファイルが残ることがあります。この場合は、一時ファイルを削除してください。
ポイント
OSで設定されている一時ディレクトリは、他のプロセスからもアクセスされるため、アクセスが集中すると配下の一時ファイルの読み書きが遅くなる可能性があります。
大量のデータをソートする場合など、一時ファイルを使用する可能性が高い場合は、他のプロセスから同時にアクセスされないディスクにWorkFolderパラメタを使って作業ディレクトリを指定してください。
InFileパラメタで2つ以上の入力ファイルを指定した場合、複数の入力ファイルから同時にソートを行う並列数を指定します。
ParallelNumパラメタに指定できる値は、1から128までです。
ParallelNumパラメタで指定した並列数が入力ファイル数よりも小さい場合、並列数以上の入力ファイルは、並列数以内の入力ファイルのソートが終わった後に順次、実行されます。
ParallelNumパラメタで指定した並列数が入力ファイル数よりも大きい場合、入力ファイルの数が同時にソートを行う並列数となります。
注意
ParallelNumパラメタに2以上を指定した場合、入力ファイルは複数の物理ディスクに分散して配置することで、読込み処理のディスクI/Oの負荷を分散でき、並列効果を最大限に発揮できます。
そのため、ParallelNumパラメタに指定した並列数と、入力ファイルを配置する物理ディスクの数を同じにすることを推奨します。
出力ファイルタイプがCSVの場合、出力データの中の文字列値を二重引用符(")で括るかどうかを指定します。
0: 出力データの中の文字列値を、二重引用符(")で括る。
1: 出力データの中の文字列値を、二重引用符(")で括らない。
ソート条件ファイルにリターン式を指定した場合だけ、本パラメタが有効になります。
リターン式を指定しない場合は、入力データをそのまま出力します。
組合せを以下に示します。
ソート条件ファイルの | 本パラメタの指定 | 二重引用符(") |
|---|---|---|
指定あり | 0 | 二重引用符(")で括る |
1 | 二重引用符(")で括らない | |
指定なし | 無効 | 入力ファイルと同じ形式 |
本パラメタを省略した場合、0が指定されたものとみなします。
注意
キー仕分け機能を使用する(KeySortパラメタが“1”)場合、本パラメタは無効です。
注意
本パラメタに“1”を設定した場合、結果データの文字列値にセパレータ文字や改行が存在しても、二重引用符は設定されません。そのため、その後の処理において、想定したデータとして扱われない場合があります。
処理対象のデータに、セパレータ文字や改行が存在する場合には、“0”を指定することを推奨します。以下に例を示します。

本パラメタに“1”を設定した場合、結果データの項目に二重引用符(")が存在しても二重引用符(")によるエスケープは設定されません。
本パラメタに“1”を設定した場合、入力ファイルのデータの項目に二重引用符(")が設定されていたときでも、結果データの項目には、二重引用符(")は付加されなくなります。
入力ファイルの区切り文字が半角空白や水平タブの場合、リターン式を指定すると結果データはカンマ区切りで出力されます。このため、入力ファイルのデータにカンマなどが存在している場合に、本パラメタに“1”を指定すると、結果データが想定したデータとして扱われない場合があります。
入力ファイルタイプがCSVの場合、項目間の区切り文字を変更する場合は、新しく区切り文字とする文字を二重引用符(")で囲んで指定します。区切り文字として使用できる文字は、以下のとおりです。
区切り文字 | 指定方法 |
|---|---|
カンマ | \, |
半角空白 | \s |
水平タブ | \t |
区切り文字として複数指定する場合は、個々の文字列をカンマ(,)で区切って指定します。
注意
本パラメタを指定した場合の出力時の区切り文字は、ソート条件ファイルにおけるリターン式の指定によって、以下のように異なります。
リターン式 | 出力時の区切り文字 |
|---|---|
指定あり | カンマ |
指定なし | 入力ファイルと同じ形式 |
入力ファイルタイプがCSVの場合、2つ以上の連続した区切り文字の扱いを指定します。
0:1つの区切り文字を1つの項目間の区切りとして扱う。
1:2つ以上の連続した区切り文字を1つの項目間の区切りとして扱う。
本パラメタを省略した場合、0が指定されたものとみなします。
入力ファイルタイプがCSVの場合、エラーデータ出力ファイルと、エラーデータの最大出力件数を指定します。
本パラメタを指定すると、エラーデータを検索対象外のデータとして扱い、ソート処理を継続します。
本パラメタを省略した場合、エラーデータを検出したとき、検出した時点でコマンドが異常終了します。
図1.37 エラーデータ出力の定義
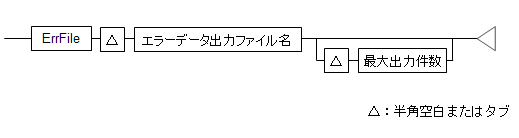
入力ファイル中にエラーデータを検出したとき、そのエラーデータの情報を出力します。
指定したファイルがすでに存在している場合は、その情報が上書きされます。
入力ファイル中にエラーデータが存在しなかった場合、エラーデータ出力ファイルは作成されません。
エラーデータの最大出力件数に指定できる値は、1から2147483647までです。
エラーデータの最大出力件数を指定すると、エラーデータが指定件数分、出力された時点でコマンドが異常終了します。
本パラメタを省略した場合、1000が指定されたものとみなします。
ポイント
入力ファイル名の工夫
ErrFileパラメタを指定した場合、入力ファイル名に半角英数字以外が含まれるとき、エラーデータ出力ファイルに出力される入力ファイル名が、文字化けすることがあります。そのため、入力ファイル名には半角英数字を使うことを推奨します。
入力定義ファイルに指定するファイル名に半角数字で日付情報を付加する例を以下に示します。
InFile "/home/Shunsaku/data/売上情報_20080101.csv ,
/home/Shunsaku/data/売上情報_20080102.csv ,
/home/Shunsaku/data/売上情報_20080103.csv ,
/home/Shunsaku/data/売上情報_20080104.csv" |
参照
エラーデータ出力ファイルの出力例は、“導入・運用ガイド”の“入力ファイルのエラー処理”を参照してください。
ユーザーが定義した関数(ユーザー定義関数)でデータを処理する場合に指定します。
ユーザー定義関数名、その変換処理を実装したC言語関数名およびライブラリ名を指定します。
本パラメタは、複数個指定できます。最大で256個までです。
本パラメタを省略した場合、ユーザー定義関数を記述しても構文エラーとなります。
図1.38 ユーザー定義関数の定義

ユーザー定義関数の変換処理を実装したC言語アプリケーションが格納された、実行モジュールのライブラリのパスを指定します。
パス名にパス区切り文字が含まれている場合、絶対パスまたはカレントディレクトリからの相対パスとみなします。
パス区切り文字が含まれていない場合、OS標準の探索方法に従ってファイルを探します。
ユーザー定義関数名は、1つの処理内で一意である必要があります。
ユーザー定義関数名には、以下の文字から成る1文字以上の文字列を使用してください。ただし、関数名の先頭に、“-”および“.”は指定できません。
! | - | . | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | @ |
A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
P | Q | R | S | T | U | V | W | X | Y | Z | _ | ` | a | b |
c | d | e | f | g | h | I | j | k | l | m | n | o | p | q |
r | s | t | u | v | w | x | Y | z |
C言語関数名には、ライブラリパスで指定した実行モジュールからエクスポートされているシンボルを指定します。
C言語関数名は、C言語に規約に従って作成してください。
参照
ユーザー定義関数の書式については、“4.6 単一行関数(ユーザー定義関数)”を参照してください。
ユーザー定義関数の作成例については、“第7章 ユーザー定義関数の作成例”を参照してください。
ユーザー定義関数の利用方法については、“導入・運用ガイド”の“ユーザー定義関数を使う”を参照してください。
0:キー仕分け機能を使用しない(通常のソート機能を使用する)。
1:キー仕分け機能を使用する。
本パラメタを省略した場合、0が指定されたものとみなします。
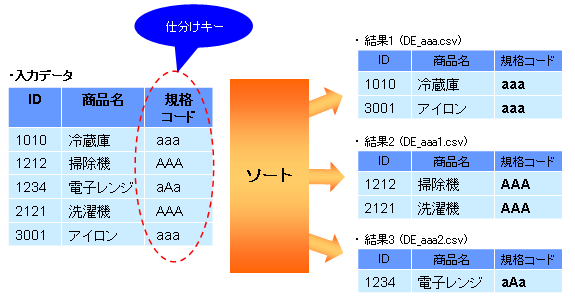
キー仕分けの条件となる仕分けキーは、ソート条件ファイルのOConditionパラメタに指定します。
キー仕分けの結果を出力するフォルダを指定します。フォルダ名は、96バイト以内で指定してください。
結果のファイル名は、Data Effectorが自動的に決定します。CSV形式の場合、見出し行を出力しないこともできます。詳細については、以下を参照してください。
キー仕分け機能を使用する場合、本パラメタを省略できません。
フォルダ名は、複数記述できません。フォルダ名に標準出力および名前付きパイプは指定できません。
ただし、キー仕分け機能を使用しない場合(KeySortパラメタが“0”または省略)、本パラメタは指定できません。
ファイル名は、“DE_(仕分けキー値)”です。
ファイル名の最大長は、128文字です(固定文字の「DE_」は除外)。
ファイルの拡張子は、ソート条件ファイルのInFileTypeパラメタの内容で決定されます。
InFileType | 拡張子 |
|---|---|
CSV | csv |
XML | xml |
注意
ファイル名に含まれる英字は、小文字となります。
仕分けキーは、項目の内容の20バイトまでが対象となります。21バイト以上を仕分けキーとしたい場合は、substr関数を指定してください。最大128文字までが対象となります。
ファイル名の対象となった仕分けキーが同じ(128バイトまで同じ内容)場合には、キーの後に“1~”の通番が設定されます。ただし、この場合は、ファイル名が128バイト(固定文字「DE_」を除く)以上となります。
ファイル名:DE_(仕分けキー値)+(通番1~)
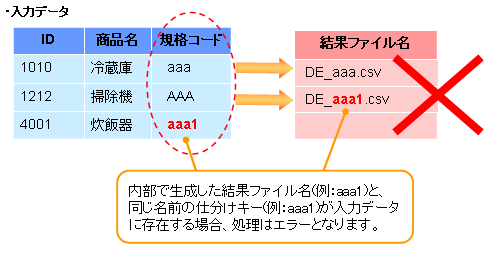
仕分けキーに英字が含まれており、かつ、その英字が大文字と小文字だけ異なっている場合も、仕分けキーから作成されるファイル名は同じと見なされ、キーの後に1~の通番が設定されます。イメージを以下に示します。
内部で生成した結果ファイル名(仕分けキー+通番)と、同じ名前の仕分けキーが入力データに存在する場合、処理はエラーとなります。
ファイル名の対象となった仕分けキーに以下のいずれかの文字が存在する場合は、ファイル名は「DE_###+(通番1~)」となります。
ASCII文字以外の文字
ファイル名に指定不可能な文字(「\」,「/」,「<」,「>」,「?」,「*」,「:」,「”」,「|」,「 (半角空白)」など)
ファイル名として使用した場合に可視できない文字
例)制御コード(0x00~0x1F、0x7fなど)
例)ファイル名の例(入力ファイルタイプがCSVのとき)
「DE_###.csv」、「DE_###1.csv」、「DE_###2.csv」・・・
同じファイル名のファイルがすでに存在する場合には、エラーとなります。
本機能を使用した場合、仕分けキーの数のファイルが作成されるため、領域不足などに注意してください。
ParallelNumパラメタを指定した場合に、以下の内容が同じにならない場合があります。
結果ファイル内のデータの順番
同一ファイル名の通番の番号
結果ファイルの見出し行を出力したくない場合には、以下と指定します。
セミコロン(;)+振分け結果出力フォルダ
# キー仕分け結果ファイルのフォルダ ResultFolder ;/home/shunsaku/data/output |
ただし、フォルダ名に空白が含まれる場合は、「セミコロン(;)+振分け結果出力フォルダ」の全体を二重引用符(")で囲う必要があります。