本節では、Storage Cluster機能に必要な、以下の操作および概念について説明します。
TFOV
TFOVとは、フェイルオーバの対象となるボリュームです。
Primary/Secondaryストレージの両方に作成されたTFOVのうち、それぞれのHLU番号と容量が一致するTFOV同士が、データの同期対象ボリュームになります。また、データの同期と併せて、Secondaryストレージのボリューム情報が「表9.1 データ同期前後のSecondaryストレージのボリューム情報の変化」のとおりに変更されます。
変更されるボリューム情報 | データ同期前 | データ同期後 |
|---|---|---|
UID | Secondaryストレージのボリューム独自のUID | ペアとなるPrimaryストレージのボリュームのUID |
Product ID | Secondaryストレージ独自のProduct ID | ペアとなるPrimaryストレージのProduct ID |
注意
Secondaryストレージのボリュームは、データ同期後にTFOグループ削除などの操作により同期対象ボリュームから外れても、データ同期後のボリューム情報が引き継がれます。そのため、Secondaryストレージのボリュームを継続して利用する場合は、ETERNUS CLIを利用してボリューム情報をデータ同期前の状態に戻してください。
利用するETERNUS CLIのコマンド名および書式は、ETERNUS ディスクアレイ付属のマニュアルを参照してください。
装置あたりの全TFOVの総容量には上限があります。装置あたりのTFOV総容量を拡張する方法は、「TFOV総容量の拡張」を参照してください。
ポイント
TFOVの容量は拡張可能です。詳細は、「9.4.2.4 業務ボリュームの容量拡張」を参照してください。
RECパス
TFOVのデータは、RECパスを使用して同期モードで転送します。
ETERNUS ディスクアレイは、Storage Cluster機能で使用するコピーセッションとアドバンスト・コピーのセッションを別に管理しています。ETERNUS ディスクアレイが自動的にStorage Cluster機能で使用するコピーセッションを制御するため、本製品でのコピーセッションおよびコピーグループの設定は不要です。
ポイント
REC経路のテンポラリ故障(通信途絶)が発生した場合は、REC経路が復旧すると差分コピーが行われて、自動的にデータが等価状態に戻ります。REC経路が復旧するまでの間はフェイルオーバされないので、REC経路の二重化を推奨します。
Failoverモード
Failoverモードとは、PrimaryストレージからSecondaryストレージへフェイルオーバする方法に関するモードです。以下のどちらかを指定できます。
モード | 説明 |
|---|---|
Auto | Primaryストレージの障害を検知したときに、自動的にフェイルオーバするモードです。 |
Manual | 手動でフェイルオーバするモードです。 |
注意
RECパスのインターフェースタイプが"iSCSI"であっても、PrimaryストレージとSecondaryストレージがiSCSIポートのRECパスによる自動Failoverを未サポートの場合は、"Manual"を指定してください。
Failbackモード
SecondaryストレージからPrimaryストレージへフェイルバックする方法に関するモードです。以下のどちらかを指定できます。
モード | 説明 |
|---|---|
Auto | Primaryストレージの障害の復旧を検知したときに、自動的にフェイルバックするモードです。 |
Manual | 手動でフェイルバックするモードです。 |
スプリットモード
スプリットモードは、REC経路が切断された際のPrimaryストレージのボリュームに対して、業務の継続を優先し書込みを継続するか、またはPrimaryストレージとSecondaryストレージのデータの等価状態を保証するかを指定します。
以下のどちらかを指定します。
"Read/Write"(デフォルト値)
業務の継続を優先し、Primaryストレージのボリュームに対して、データの書込みを継続します。
この場合、Primaryストレージのボリュームだけにデータを書き込むので、Secondaryストレージのデータと等価でない状態になります。
"Read"
データの等価状態の維持を優先し、Primaryストレージのボリュームに対して、データの書込みを禁止します。
TFOグループ
TFOグループとは、1つの装置上でのフェイルオーバの動作単位であり、フェイルオーバするための接続構成、ポリシー、状態、および保守を一元管理するグループです。TFOグループは、1つ以上のCAポートと、そのCAポートにアクセスが許可されたボリュームを含みます。TFOグループの例は、「図9.2 TFOグループ例」のとおりです。
図9.2 TFOグループ例
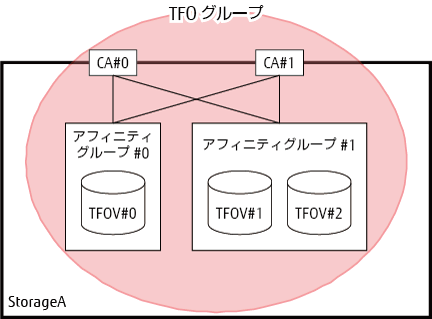
TFOグループは、以下のTFOステータスを持ちます。フェイルオーバまたはフェイルバックを実行することによって、TFOステータスが変わります。
ポイント
TFOグループ名の入力条件は、以下のとおりです。
1~16文字の、半角英数字「A~Z、a~z、0~9」および特殊文字です。ただし、「, ? " ' \ * %」は使用できません。
TFOステータス | 意味 |
|---|---|
Active | 運用側を意味します。管理対象サーバからアクセス可能な状態です。 |
Standby | 待機側を意味します。管理対象サーバからアクセス不可能な状態です。 |
環境構築時の初期の、TFOステータスがActiveのTFOグループを“Primary TFOグループ”、StandbyのTFOグループを“Secondary TFOグループ”と呼びます。
CAポートのペア化
Storage Cluster機能は、2台のETERNUS ディスクアレイのCAポートでポートパラメーターを共有して、各CAポートのLink状態を制御してフェイルオーバを実現します。
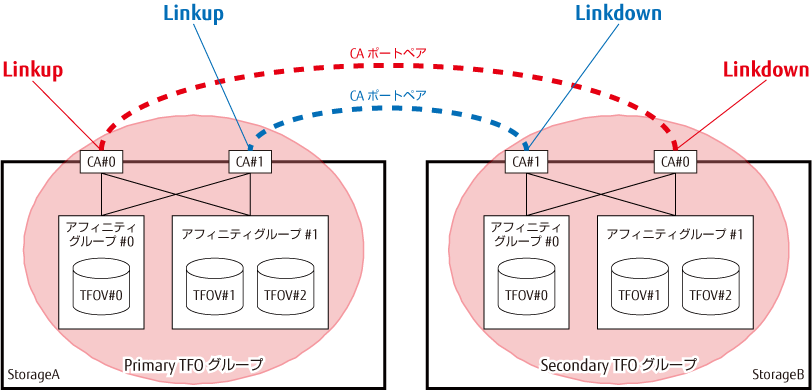
TFOグループに含まれるCAポートは、別のTFOグループに含まれるCAポートと、1つのポートパラメーターを筐体間で共有します。この共有を行う操作を“CAポートのペア化”と呼びます。また、ポートパラメーターを共有したCAポートの1組を“CAポートペア”と呼びます。
FC構成の場合は、WWPN/WWNNを共有します。CAポートのペア化を行うことで、SecondaryストレージのCAポートに論理WWPN/WWNNとして、PrimaryストレージのCAポートのWWPN/WWNNが自動設定され、SecondaryストレージのCAポートがLinkdownします。
iSCSI構成の場合は、iSCSIネームおよびiSCSI IPアドレスを共有します。CAポートのペア化を行うことで、SecondaryストレージのCAポートがLinkdownします。そのあと、SecondaryストレージのCAポートに、PrimaryストレージのCAポートのiSCSIネームとiSCSI IPアドレスを手動設定することで共有できます。
CAポートペアのイメージは、「図9.3 CAポートペア例」のとおりです。
図9.3 CAポートペア例
自動Failover
自動Failoverとは、Primary TFOグループがあるETERNUS ディスクアレイの障害を検知したときに、Secondary TFOグループが自動的にActiveになる機能です。自動Failoverを行うには、管理LANで接続されたStorage Clusterコントローラーが必要です。
「図9.4 ストレージ装置ダウン時の自動Failoverの動作(FC構成の場合)」は、StorageA(Primaryストレージ)とStorageB(Secondaryストレージ)で運用している場合に、StorageAがダウンして、StorageBにフェイルオーバする動作イメージを示しています。
「図9.5 CAポートLinkdown時の自動Failoverの動作(FC構成の場合)」は、StorageA(Primaryストレージ)とStorageB(Secondaryストレージ)で運用している場合に、StorageAのCAポートの故障または結線異常によってPrimary TFOグループに属しているすべてのCAポートがLinkdownして、StorageBにフェイルオーバする動作イメージを示しています。
これらの例は、FC構成の場合です。iSCSI構成の場合は、CAポートにiSCSIネームとiSCSI IPアドレスが設定されており、スイッチはネットワークスイッチとなります。
図9.4 ストレージ装置ダウン時の自動Failoverの動作(FC構成の場合)
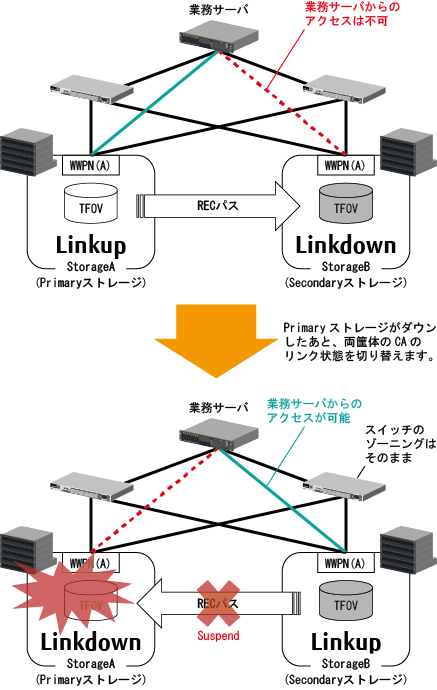
図9.5 CAポートLinkdown時の自動Failoverの動作(FC構成の場合)
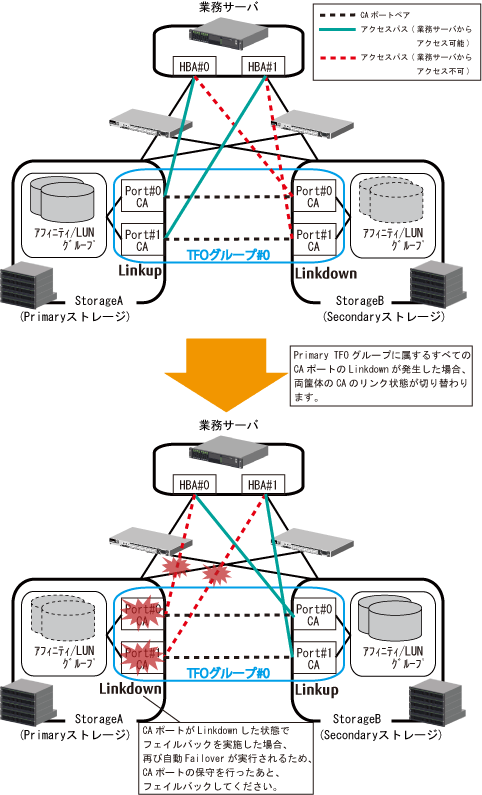
各CAポートのLink状態の切替えに合わせて、自動的にTFOグループの状態も切り替えられ、Secondary TFOグループのボリュームへのアクセスが可能になります。
注意
スイッチの二重故障などによってPrimaryストレージとSecondaryストレージ間のRECパスのLinkDownと業務サーバ接続用CA ポートLinkDownが同時に発生した場合、CAポートLinkDown時の自動Failoverは動作しません。RECパス用スイッチと業務サーバ接続用スイッチを分けるなど、LinkDownが同時に発生しないシステム構成にしてください。
自動Failback
自動Failbackとは、Primary TFOグループがあるETERNUS ディスクアレイの障害からの復旧を検知したときに、Primary TFOグループが自動的にActiveになる機能です。
TFOペアの解除/復旧
RAID故障、RAID閉塞、または不良セクタが発生した場合の保守手順において実施する操作です。
操作では、Storage Clusterのボリュームペアの一覧から、操作対象ボリュームのペアを選択します。
ポイント
TFOペアを解除する場合
RAIDグループを保守できる状態にするため、問題が発生したRAIDグループに属するすべてのTFOVのTFOペアを解除してください。
TFOペアを復旧する場合
問題が発生したRAIDグループに属するすべてのTFOVのTFOペアを復旧してください。TFOペアを復旧することで、ペアとなっているボリューム間においてイニシャルコピーによる同期が行われます。イニシャルコピーの所要時間は、「表9.6 イニシャルコピーの所要時間(物理容量が1TBのボリュームにおける目安値)」を目安にしてください。
Storage Cluster環境の解体
装置交換が必要な故障が発生してETERNUS ディスクアレイを入れ替える場合などは、一旦、Storage Cluster環境を解体します。
TFOグループを削除することで、構築したStorage Clusterの環境を解体します。
FC構成の場合は、TFOグループを削除するときに、SecondaryストレージのCAポートのWWPN/WWNNの扱いについて以下のどちらかを選択できます。
SecondaryストレージのCAポートを本来のWWPN/WWNNに戻す
SecondaryストレージのCAポートを本来のWWPN/WWNNに戻さずに、論理WWPN/WWNNを継続して利用
手順aを選択した場合は、PrimaryストレージのCAポートのWWPN/WWNNとは競合しません。
手順bを選択した場合は、管理対象サーバからSecondaryストレージへのアクセスが可能なまま、Primaryストレージとして運用していた装置を交換できます。
注意
FC構成の場合
PrimaryストレージのCAポートとSecondaryストレージのCAポートの両方がActiveになると、WWPN/WWNNが競合してデータ破壊などが発生する可能性があります。このため、手順bを選択する場合は、以下のことを遵守してください。
PrimaryストレージのCAポートがSANから物理的に切断されていることを確認してから、TFOグループを削除する
Primary TFOグループを削除したETERNUS ディスクアレイをSANに接続しない
iSCSI構成の場合
iSCSIネームおよびiSCSI IPアドレスは設定した値のままとなります。このため、以下のことを遵守してください。
iSCSI IPアドレスが同一SAN内で重複していないか確認し、iSCSI IPアドレスが同一SAN内で重複している場合は、iSCSI IPアドレスを変更したあと、TFOグループを削除する
Standby側のストレージがSANから物理的に切断されていることを確認してから、TFOグループを削除する
Primary/SecondaryストレージのCAのLink状態制御
CAポートのペア化やフェイルオーバにより、CAポートのポートパラメーターの値およびLink状態が推移します。Link状態がLinkupの装置に対して、管理対象サーバからアクセスが可能です。
FC構成の場合は、CAポートのペア化によってWWPN/WWNNの値が推移します。
iSCSI構成の場合は、CAポートをペア化したあとに手動でSecondaryストレージのiSCSI CAポートのパラメーターをPrimaryストレージと同じ設定にしておくことで、Link状態が制御されます。
CAポートのペア化やフェイルオーバ/フェイルバックの動作時の、それぞれのCAポートのLink状態の遷移を「表9.3 CAポートのLink状態の遷移(FC構成の場合)」および「表9.4 CAポートのLink状態の遷移(iSCSI構成の場合)」に示します。
Primaryストレージ | タイミング | Secondaryストレージ | ||
|---|---|---|---|---|
WWPN/WWNN | Link状態 | Link状態 | WWPN/WWNN | |
Primaryストレージ側の | Linkup | CAポートのペア化前 | Linkup | Secondaryストレージ側の |
CAポートのペア化後 | Linkdown | Primaryストレージ側の | ||
Linkdown | Primaryストレージが停止 | |||
フェイルオーバ実施中 | ||||
フェイルオーバ完了後 | Linkup | |||
Primaryストレージ復旧 | ||||
フェイルバック起動 | ||||
フェイルバック実施中 | Linkdown | |||
Linkup | フェイルバック完了後 | |||
Storage Cluster解体 (注) | Linkup | Secondaryストレージ側の | ||
注: SecondaryストレージのCAポートのWWPN/WWNNを元に戻す場合
Primaryストレージ | タイミング | Secondaryストレージ | ||
|---|---|---|---|---|
iSCSI情報 | Link状態 | Link状態 | iSCSI情報 | |
Primaryストレージ側の | Linkup | CAポートのペア化前 | Linkup | Secondaryストレージ側の |
CAポートのペア化後 | Linkdown | |||
Secondary側のiSCSI CAポートのパラメーター設定 | Primaryストレージ側の | |||
Linkdown | Primaryストレージが停止 | |||
フェイルオーバ実施中 | ||||
フェイルオーバ完了後 | Linkup | |||
Primaryストレージ復旧 | ||||
フェイルバック起動 | ||||
フェイルバック実施中 | Linkdown | |||
Linkup | フェイルバック完了後 | |||
Secondary側のiSCSI CAポートのパラメーター設定 | Secondaryストレージ側の | |||
Storage Cluster解体 | Linkup | |||
Storage Clusterコントローラー
自動Failoverを行うには、管理LANに接続されたStorage Clusterコントローラーが必要です。
2台のETERNUS ディスクアレイ間では、RECパスを利用して生存確認を実施します。RECパスが断線した場合、2台のETERNUS ディスクアレイが動作中にもかかわらず、誤判断で切り替える可能性があります。この誤判断を防ぐには、Primary/Secondaryストレージの両方のETERNUS ディスクアレイのそれぞれに管理LANで通信するStorage Clusterコントローラーを設置します。
Primary/Secondaryストレージの両方のETERNUS ディスクアレイとStorage Clusterコントローラー間の構成例は、「図9.6 Storage Clusterコントローラーを介した生存確認の構成例」のとおりです。この構成例で、通信と装置の状態と、自動Failoverを実行する契機は、「表9.5 自動Failoverが動作する契機」のとおりです。
図9.6 Storage Clusterコントローラーを介した生存確認の構成例
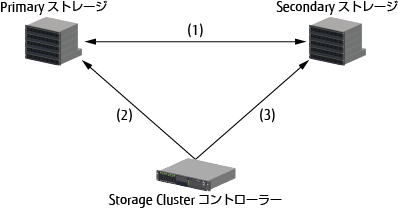
項番 | 通信状態 | 装置状態 | 自動Failoverが動作する契機と状態遷移 | |||
|---|---|---|---|---|---|---|
(1) | (2) | (3) | Primary | Secondary | ||
1 | ○ | ○ | ○ | 生存 | 生存 | なし |
2 | × | ○ | ○ | |||
3 | ○ | × | ○ | |||
4 | ○ | ○ | × | |||
5 | × | × | ○ | ダウン | あり Primaryストレージ: Active → Standby | |
6 | × | ○ | × | 生存 | ダウン | なし |
7 | ○ | × | × | 生存 | ||
8 | × | × | × | ダウン | ダウン | なし(全閉塞) (注) |
○: 通信可、×: 通信不可
注: 被災した際にStorage Clusterコントローラーの通信を含むネットワーク環境を再構築する構成の場合、一時的にStorage Clusterコントローラーからの通信が不可となり、全閉塞の状態になることがあります。
注意
以下のケースでは、自動Failoverが動作しません。
FC構成の場合
「PrimaryストレージとStorage Clusterコントローラー間の経路(2)」が故障してから10秒経過したあとに、「PrimaryストレージとSecondaryストレージ間の経路(1)」が故障した
「PrimaryストレージとSecondaryストレージ間の経路(1)」が故障してから3秒経過したあとに、「PrimaryストレージとStorage Clusterコントローラー間の経路(2)」が故障した
iSCSI構成の場合
「PrimaryストレージとStorage Clusterコントローラー間の経路(2)」が故障してから20秒経過したあとに、「PrimaryストレージとSecondaryストレージ間の経路(1)」が故障した
「PrimaryストレージとSecondaryストレージ間の経路(1)」が故障してから7秒経過したあとに、「PrimaryストレージとStorage Clusterコントローラー間の経路(2)」が故障した
Storage Clusterコントローラーと監視対象の各ETERNUS ディスクアレイは、相互に監視を行います。そのため、Storage Clusterコントローラーと監視対象のETERNUS ディスクアレイが同じ建屋内に配置された場合、以下の問題が発生する可能性があります。
建屋が被災した場合、すべての経路が閉塞し、フェイルオーバできなくなる
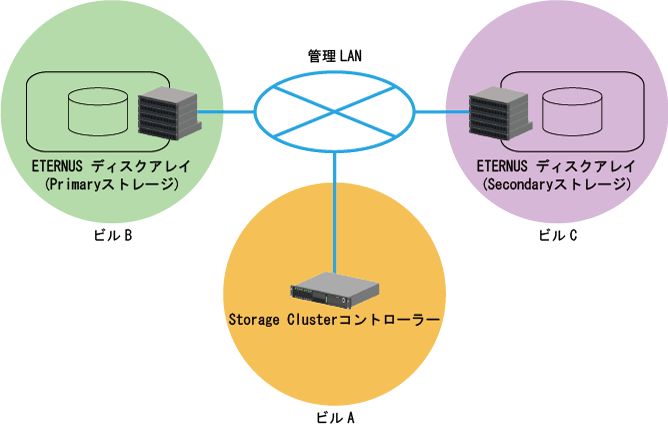
上記の問題の発生を防止するため、Storage Clusterコントローラーと監視対象の各ETERNUS ディスクアレイの建屋を分離して配置することを推奨します。配置例は「図9.7 Storage Clusterコントローラーと監視対象のETERNUS ディスクアレイの配置例」のとおりです。
なお、Storage Clusterコントローラーは、運用管理サーバと同じサーバ上に配置することも可能です。
図9.7 Storage Clusterコントローラーと監視対象のETERNUS ディスクアレイの配置例