ここでは、レプリケーションの運用を監視する方法について説明します。
レプリケーション業務の監視
抽出定義の一覧と差分ログの取得状態の表示
DBサービスの監視
ログファイルの監視
レプリケーション業務の運用状態は、Linkexpressクライアントの“業務監視ウィンドウ”を使用して監視することができます。
“業務監視ウィンドウ”の詳細については、“Linkexpress 運用ガイド”を参照してください。
“業務監視ウィンドウ”によりレプリケーション業務が異常完了したことが判明した場合、異常完了した原因について調査した後、以下に示す手順で業務を再開してください。なお、原因の調査方法については、“Linkexpress 運用ガイド”を参照してください。
異常の発生により業務が異常完了している場合は、その原因を取り除いた後、“業務の再開”の操作を行って、業務を再開します。
異常原因の対処が容易に行えない場合は、“異常完了したレプリケーション業務の取消し”の操作を行って、業務を取り消すこともできます。
“業務の中止”の操作により、業務が異常完了している場合は、“業務の開始”の操作を行って、業務を再開します。
各操作の詳細については、以下の参照項目を参照してください。
説明
定義されている抽出定義またはレプリケーショングループの一覧と、それぞれについて差分ログの取得が開始されているかどうか、差分ログの取得がいつ有効になったかの状態を表示します。
操作方法
lxrepprt [ { -d データベース名
| -s データベース名.スキーマ名
| -t データベース名.スキーマ名.表名
| -l [ -r 抽出定義名 ] } ]
[ -e TIME ]参照
“コマンドリファレンス”の“lxrepprtコマンド(抽出定義の一覧の表示)”
DBサービスを監視するために、DBサービスの状態表示機能があります。また、グループ単位のレプリケーションでの異常時の対処として、DBサービス管理情報のリセット機能があります。
ここでは、これらの機能について説明します。
DBサービスの状態監視
DBサービス管理情報のリセット
DBサービスの状態は、DBサービス状態表示コマンド(lxdspsvコマンド)で表示することができます。
ここでは、グループ単位のレプリケーションでのDBサービスの状態表示について説明します。詳細は、“コマンドリファレンス”の“lxdspsvコマンド”を参照してください。
なお、表単位のレプリケーションでのDBサービスの状態表示については、“Linkexpress コマンドリファレンス”を参照してください。
説明
DBサービスの状態を表示します。
操作方法
lxdspsv [ -s DBサービスグループ名 ]
[ { -d | -r [ レプリケーショングループ名 ] } ]参照
“コマンドリファレンス”の“lxdspsvコマンド”
DBサービスの管理情報をリセットします。
説明
グループ単位のレプリケーションでは、レプリケーション業務の格納処理中に異常が発生した場合、すでに格納が完了しているトランザクションを引き継いで業務を再開することができます。
すなわち、異常完了した格納処理のイベントから業務を再開すると、自動的に異常が発生したトランザクションから再開することができます。
しかし、異常の発生原因によっては、先頭のトランザクションから再開する必要があります。この場合は、DBサービス管理情報復旧コマンド(lxrstsvコマンド)を実行して、DBサービスの管理情報をリセットすることにより、先頭のトランザクションから再開することができます。
操作方法
lxrstsv -s DBサービスグループ名
[ -r レプリケーショングループ名 ]
[ -f ]参照
“コマンドリファレンス”の“lxrstsvコマンド”
レプリケーションの運用では、レプリケーションを自動化しておくだけではなく、以下のログファイルが容量不足を起こさないように、監視を行うことが必要です。
トランザクションログテーブル
差分ログファイル
これらのログファイルの状態は、以下の図のように遷移します。
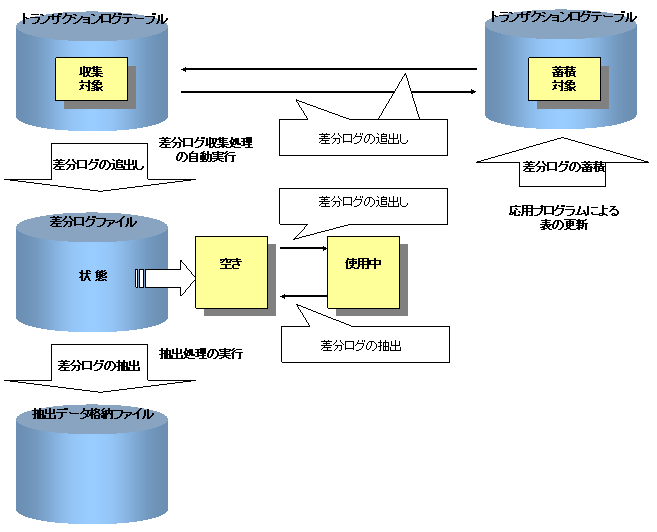
トランザクションログテーブルが満杯になり、差分ログが出力できなくなると、複写元データベースを更新する利用者プログラムがエラーとなります。
また、差分ログの追出しの結果、差分ログファイルが満杯になると、差分ログが出力できなくなりコンソールにエラーメッセージを出力しますが、自動で差分ログを破棄するため、利用者プログラムはエラーにはなりません。
ここでは、これらのログファイルの監視手段と容量不足の防止方法について説明します。あわせて、差分ログファイルへの書出し処理で異常が発生した場合の対処方法について説明します。
ログファイルの監視手段
トランザクションテーブルの容量不足の防止
差分ログファイルの容量不足の防止
差分ログファイルの異常発生時の対処
トランザクションログテーブルの異常発生時の対処
Linkexpress Replication optionでは、差分ログファイルの容量監視を行うために以下の機能を提供しています。レプリケーションの運用にあたっては、これらの機能を使って、ログファイルの容量不足を未然に防ぐことが必要です。
機能 | 内容 | 対象ログファイル | 方法 |
|---|---|---|---|
警告メッセージ | ログファイル内での使用率が警告サイズを超えた場合に、コンソール(注)に警告メッセージを出力します。 | 差分ログファイル | 抽出定義時に、警告サイズをlxrepcreコマンドで指定します。詳細は、 |
状態表示 | ログファイルの状態(例えばファイルの使用サイズなど)を標準出力に対して出力します。 | 差分ログファイル | lxreplogコマンドで状態を表示することができます。詳細は、“コマンドリファレンス”の“lxreplogコマンド(差分ログファイルの状態表示)”を参照してください。 |
注)コンソールについては、“読み方”を参照してください。
警告メッセージのメッセージ番号とメッセージ内容を以下に示します。
対象ログファイル | メッセージ番号 | メッセージ |
|---|---|---|
差分ログファイル | RP13033 | 差分ログファイルの使用量が警告サイズを超えました 抽出定義名=s* 警告サイズ=d*メガバイト |
RP13034 | 差分ログファイルの使用量が警告サイズを超えました 抽出定義名=s* 警告サイズ=d*ギガバイト | |
RP13035 | 差分ログファイルの使用量が警告サイズを超えました レプリケーショングループ名=s* 警告サイズ=d*メガバイト | |
RP13036 | 差分ログファイルの使用量が警告サイズを超えました レプリケーショングループ名=s* 警告サイズ=d*ギガバイト |
トランザクションログテーブルは、Symfoware ServerまたはEnterprise Postgresの表であるために、Symfoware ServerまたはEnterprise Postgresの機能を利用した容量監視を実施してください。
以下に例を示します。
容量監視を行うためにOSコマンドやSymfoware ServerまたはEnterprise Postgresのシステム関数を使います。トランザクションログテーブルを作成しているテーブル空間が使用しているディレクトリの容量を、OSコマンドを使って監視することで実現できます。また、Symfoware ServerまたはEnterprise Postgresのシステム関数であるデータベースオブジェクト容量関数により、テーブル空間で使用されるディスク容量を監視することで実現できます。
方法例 | 内容 | 対象ログファイル | 方法 |
|---|---|---|---|
例1 | テーブル空間が使用しているディレクトリのディスク容量に余裕があることを確認します。 | トランザクションログテーブル | dfコマンドなどを使用して、テーブル空間に使用しているディレクトリのディスクの使用率を監視します。 |
例2 | テーブル空間で使用しているディレクトリのサイズが想定範囲であることを確認します。 | テーブル空間で使用しているディレクトリの容量は、Symfoware ServerまたはEnterprise Postgresのpqslコマンドなどで、データベースオブジェクト容量関数を使用することで確認することができます。 |
トランザクションログテーブルが容量不足になる可能性があると判断した場合の対処方法を以下に示します。
原因 | 対処方法 |
|---|---|
利用者プログラムによる更新量が多いため、トランザクションログテーブルを圧迫している。 | 差分ログ収集間隔を以下の手順で短くするように変更します。 1. レプリケーションサービスを停止します。 2. 動作環境ファイル内のCOLLECTION_NAPTIMEパラメタを変更します。 3. レプリケーションサービスを開始します。 |
差分ログ収集間隔が長すぎる。 | |
テーブル空間が使用しているディレクトリのディスク容量が小さい。 | “1.2.5.1.1 トランザクションログテーブルの再作成”を参照して、ディスク容量が大きいディレクトリを使用しているテーブル空間を使用するように、トランザクションログテーブルを再作成します。 |
参照
レプリケーションサービスの開始および停止については、“1.2.2.3 レプリケーションサービスの開始と停止”を参照してください。
動作環境ファイルについての詳細は、“1.1.2.3.3 動作環境ファイルの作成”を参照してください。
差分ログファイルの使用量が警告サイズを超過するか、または状態表示によって容量不足になる可能性があると判断した場合の対処方法を以下に示します。
原因 | 対処方法 |
|---|---|
一括差分複写業務の業務スケジュールの間隔が長いため、差分ログが差分ログファイルに蓄積され続けている。 | 業務スケジュールの変更を行って、スケジュール間隔を短くしてください。抽出処理で差分ログを抽出することによって使用率は下がります。詳細は、“1.2.4.1.5 レプリケーション業務の変更”を参照してください。 |
一時的に差分ログ量が増えてしまった。 | 差分ログファイル内の差分ログを複写先データベースに反映し、差分ログファイル内の空きを作成してください。詳細は、“1.2.1.4 手動による同期操作”を参照してください。 |
なお、差分ログファイルは、以下のサイズまで自動的に容量が拡張されます。なお、拡張された領域は、抽出処理で差分ログが抽出されると自動的に返却されます。
ディスクの空き容量が4Tバイト未満の場合は、空き容量に達するまで拡張
ディスクの空き容量が4Tバイト以上の場合は、4Tバイトまで拡張
レプリケーションの運用中に差分ログファイルへの書出し処理で異常が発生した場合、コンソールにエラーメッセージが出力されます。なお、コンソールについては、“読み方”を参照してください。
この場合、出力されたメッセージIDを基に、以下の対処方法に従ってください。
メッセージID | 現象 | 対処方法 |
|---|---|---|
RP04086 | 差分ログファイルの容量不足を検出しました。 | 以下の手順で差分ログを破棄してください。
|
RP04071 | 差分ログファイルの書出し中に入出力障害を検出しました。 | “1.2.5.1.3 差分ログファイルの再作成(容量不足、閉塞からのリカバリ)”で示す手順で差分ログファイルを再作成してください。 |
RP13004 | 差分ログファイルの内容が破壊されています。 | |
RP04089 | 差分ログファイルがアクセス禁止になっています。 |
注1)手順6.で初期複写業務を利用する場合には、差分ログの取得開始および利用者プログラムを停止する必要はありません。
注2)“業務の中止”の操作により、一括差分複写業務を中止します。これにより、当日分のスケジュールを停止します。
注3)完了状態にない一括差分複写業務に対し、“業務の中止”を行うと、未反映の差分ログ(抽出データ格納ファイル)が残ります。このため、業務確定コマンド(lxcmtdbコマンド)を実行して、未反映の差分ログ(抽出データ格納ファイル)を削除します。
なお、エラーメッセージのパラメタには、差分ログファイル名が設定されているものがあります。“システム設計ガイド”の“ファイル構成について”の“差分ログファイル”を参照し、該当する抽出定義を特定してください。
レプリケーションの運用中にトランザクションログテーブルへの入出力処理で異常が発生した場合、以下の対処を実施してください。
利用者プログラムを停止 (注1)
全レプリケーション業務の停止
すべての抽出定義の削除
レプリケーションオブジェクトスキーマの削除
異常原因の対処(DISK交換など)
レプリケーションオブジェクトスキーマの作成
すべての抽出定義の作成
全複写業務または初期複写業務の実行
すべての差分ログの取得開始 (注1)
すべてのレプリケーション業務の開始
利用者プログラムを開始 (注1)
注1)手順8.で初期複写業務を利用する場合には、差分ログの取得開始および利用者プログラムを停止する必要はありません。