This section describes the setup procedure for the PRIMEQUEST shutdown facility.
The setup procedure for the shutdown facility is different depending on the model/configuration. Check the hardware model/configuration to set up the appropriate shutdown agent.
The following shows the shutdown agents required for each hardware model/configuration.

See
For details on the shutdown facility, see the following manuals:
"3.3.1.8 PRIMECLUSTER SF" in the "PRIMECLUSTER Concepts Guide"
"8 Shutdown Facility" in the "PRIMECLUSTER Cluster Foundation (CF) Configuration and Administration Guide"
Note
After setting up the shutdown agent, conduct a test for forced shutdown of cluster nodes to check that the correct nodes can be forcibly stopped. For details of the test for forced shutdown of cluster nodes, see "1.4 Test".
When creating a redundant administrative LAN used in the shutdown facility by using GLS, use the logical IP address takeover function of the NIC switching mode, and for the administrative LAN used in the shutdown facility, set a physical IP address.
Check the information of the shutdown agent to be used.
Note
Check the shutdown agent information before cluster initialization.
MMB check items
If an MMB is being used, check the following settings:
The "Privilege" setting of the user is set to "Admin" so that the user can control the MMB with RMCP.
The "Status" setting of the user is set to "Enabled" so that the user can control the MMB with RMCP.
Check the settings for the user who uses RMCP to control the MMB. Log in to MMB Web-UI, and check the settings from the "Remote Server Management" window of the "Network Configuration" menu.
If the above settings have not been set, set up the MMB so that the above settings are set.
Jot down the following information related to the MMB:
User's name for controlling the MMB with RMCP (*1)
User's password for controlling the MMB with RMCP.
*1) The user must be granted the Admin privilege.
Note
The MMB units have two types of users:
User who controls all MMB units
User who uses RMCP to control the MMB
The user to be checked here is the user who uses RMCP to control the MMB. Be sure to check the correct type of user.
See
For information on how to set up the MMB and check the settings, refer to the "PRIMEQUEST 500/400 Reference Manual: Basic Operation /GUI/Commands".
Virtual machine check items
If you want to use VMGuest (the shutdown agent in the virtual machine function), log in to the host OS using SSH in order to force stop the guest OS. To do this, you need to set up the following information.
Host OS IP address
User name for logging in to the host OS (FJSVvmSP)
User password for logging in to the host OS
For the information about User name and password for logging in to the host OS, record it you have set up in "3.2.1 Host OS setup".
Even if a cluster partition occurs due to a failure in the cluster interconnect, all the nodes will still be able to access the user resources. For details on the cluster partition, see "2.2.2.1 Protecting data integrity" in the "PRIMECLUSTER Concepts Guide".
To guarantee the consistency of the data constituting user resources, you have to determine the node groups to survive and those that are to be forcibly stopped.
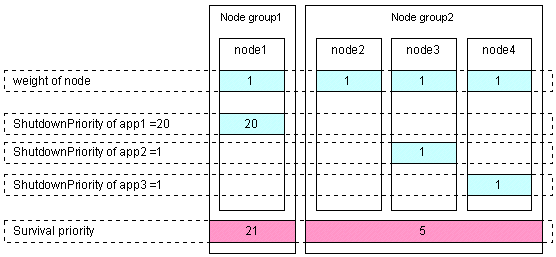
The weight assigned to each node group is referred to as a "Survival priority" under PRIMECLUSTER.
The greater the weight of the node, the higher the survival priority. Conversely, the less the weight of the node, the lower the survival priority. If multiple node groups have the same survival priority, the node group that includes a node with the name that is first in alphabetical order will survive.
Survival priority can be found in the following calculation:
Survival priority = SF node weight + ShutdownPriority of userApplication
Weight of node. Default value = 1. Set this value while configuring the shutdown facility.
Set this attribute when userApplication is created. For details on how to change the settings, see "8.5 Changing the Operation Attributes of a userApplication".
See
For details on the ShutdownPriority attribute of userApplication, see "11.1 Attributes available to the user" in the "PRIMECLUSTER Reliant Monitor Services (RMS) with Wizard Tools Configuration and Administration Guide".
Survival scenarios
The typical scenarios that are implemented are shown below:
Set the weight of all nodes to 1 (default).
Set the attribute of ShutdownPriority of all user applications to 0 (default).
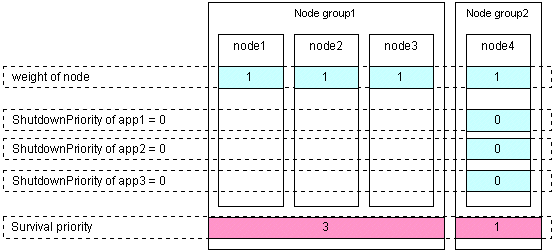
Set the "weight" of the node to survive to a value more than double the total weight of the other nodes.
Set the ShutdownPriority attribute of all user applications to 0 (default).
In the following example, node1 is to survive:
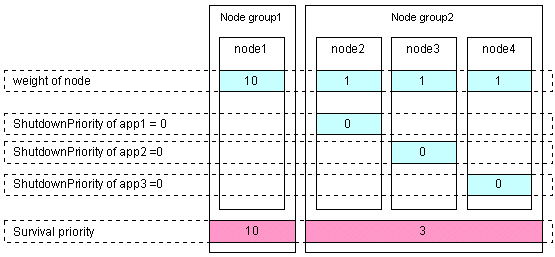
Set the "weight" of all nodes to 1 (default).
Set the ShutdownPriority attribute of the user application whose operation is to continue to a value more than double the total of the ShutdownPriority attributes of the other user applications and the weights of all nodes.
In the following example, the node for which app1 is operating is to survive:
This section describes the procedure for setting up the MMB in the shutdown facility.
Check the information of the shutdown agent before setting up the shutdown facility.
Registering MMB information
Note
Carry out the MMB information registration described here after "5.1.1 Setting Up CF and CIP" and before "Setting Up the Shutdown Daemon" which is described later.
Execute the "clmmbsetup -a" command on all nodes, and register the MMB information.
For instructions on using the "clmmbsetup" command, see the "clmmbsetup" manual page.
# /etc/opt/FJSVcluster/bin/clmmbsetup -a mmb-user |
For mmb-user and User's Password, enter the following values that were checked in "5.1.2.1 Checking the Shutdown Agent Information".
User's name for controlling the MMB with RMCP
User's password for controlling the MMB with RMCP.
Note
Only alphanumeric characters can be used for User's Password, but not symbols.
Execute the "clmmbsetup -l" command on all nodes, and check the registered MMB information.
If the registered MMB information was not output on all nodes in Step 1, start over from Step 1.
# /etc/opt/FJSVcluster/bin/clmmbsetup -l |
Setting up the shutdown daemon
On all nodes, create /etc/opt/SMAW/SMAWsf/rcsd.cfg with the following information:
CFNameX,weight=weight,admIP=myadmIP: agent=SA_xxx,timeout=20 CFNameX,weight=weight,admIP=myadmIP: agent=SA_xxx,timeout=20 |
CFNameX : Specify the CF node name of the cluster host. weight : Specify the weight of the SF node. myadmIP : Specify the IP address of the administration LAN for the local node. SA_xxx : Specify the name of the shutdown agent. To set the node to panic status through the MMB Specify "SA_mmbp". To reset the node through the MMB Specify "SA_mmbr".
Example) Shown below is a setup example for a 2-node configuration.
# cat /etc/opt/SMAW/SMAWsf/rcsd.cfg |
Note
For the shutdown agents to be specified in the rcsd.cfg file, set both the SA_mmbp and SA_mmbr shutdown agents in that order.
Set the same contents in the rcsd.cfg file on all nodes. Otherwise, a malfunction may occur.
Information
When creating the /etc/opt/SMAW/SMAWsf/rcsd.cfg file, you can use the /etc/opt/SMAW/SMAWsf/rcsd.cfg.mmb.template file as a template.
Starting the MMB asynchronous monitoring daemon
Starting the MMB asynchronous monitoring daemon
Check that the MMB asynchronous monitoring daemon has been started on all nodes.
# /etc/opt/FJSVcluster/bin/clmmbmonctl |
If "The devmmbd daemon exists." is displayed, the MMB asynchronous monitoring daemon has been started.
If "The devmmbd daemon does not exist." is displayed, the MMB asynchronous monitoring daemon has not been started. Execute the following command to start the MMB asynchronous monitoring daemon.
# /etc/opt/FJSVcluster/bin/clmmbmonctl start |
Starting the shutdown facility.
Check that the shutdown facility has been started on all nodes.
# sdtool -s |
If the shutdown facility has already been started, execute the following command to restart the shutdown facility on all nodes.
# sdtool -e |
If the shutdown facility has not been started, execute the following command to start the shutdown facility on all nodes.
# sdtool -b |
Checking the status of the shutdown facility
Check the status of the shutdown facility on all nodes.
# sdtool -s |
Information
Display results of the sdtool -s command
If "InitFailed" is displayed as the initial status, it means that a problem occurred during initialization of that shutdown agent.
If "TestFailed" is displayed as the test status, it means that a problem occurred while the agent was testing whether or not the node displayed in the cluster host field could be stopped. Some sort of problem probably occurred in the software, hardware, or network resources being used by that agent.
If "Unknown" is displayed as the stop or initial status, it means that the SF has still not executed node stop, path testing, or SA initialization. "Unknown" is displayed temporarily until the actual status can be confirmed.
If TestFailed or InitFailed is displayed, check the SA log file or /var/log/messages. The log file records the reason why SA testing or initialization failed. After the failure-causing problem is resolved and SF is restarted, the status display changes to InitWorked or TestWorked.
Note
If "sdtool -s" is executed immediately after the OS is started, "TestFailed" may be displayed as the test status in the local node. However, this status is displayed because the snmptrapd daemon is still being activated and does not indicate a malfunction. If "sdtool -s" is executed 10 minutes after the shutdown facility is started, TestWorked is displayed as the test status.
In the following example, TestFailed is displayed test status for the local node (node1).
# sdtool -s
Cluster Host Agent SA State Shut State Test State Init State
------------ ----- -------- ---------- ---------- ----------
node1 SA_mmbp.so Idle Unknown TestFailed InitWorked
node1 SA_mmbr.so Idle Unknown TestFailed InitWorked
node2 SA_mmbp.so Idle Unknown TestWorked InitWorked
node2 SA_mmbr.so Idle Unknown TestWorked InitWorked |
The following messages may be displayed right after the OS is started by same reason as previously described.
3084: Monitoring another node has been stopped. SA SA_mmbp.so to test host nodename failed SA SA_mmbr.so to test host nodename failed |
These messages are also displayed because the snmptrapd daemon is being activated and does not indicate a malfunction.
The following message is displayed 10 minutes after the shutdown facility is started.
3083: Monitoring another node has been started. |
If a node is forcibly shut down by the SA_mmbr shutdown agent, the following message may be output. This message indicates that it takes time to shut down the node, not a malfunction.
Fork SA_mmbp.so(PID pid) to shutdown host nodename : SA SA_mmbp.so to shutdown host nodename failed : Fork SA_mmbr.so(PID pid) to shutdown host nodename : SA SA_mmbr.so to shutdown host nodename failed : MA SA_mmbp.so reported host nodename leftcluster, state MA_paniced_fsnotflushed : MA SA_mmbr.so reported host nodename leftcluster, state MA_paniced_fsnotflushed : Fork SA_mmbp.so(PID pid) to shutdown host nodename : SA SA_mmbp.so to shutdown host nodename succeeded
If "sdtool -s" is executed immediately after the message above was output, KillWorked is displayed in Shut State of SA_mmbp.so. Then, KillFailed is displayed in Shut State of SA_mmbr.so.
The following indicates the example when shutting down nodes from node1 to node2 and executing “sdtool -s” after the message above.
# sdtool -s
Cluster Host Agent SA State Shut State Test State Init State
------------ ----- -------- ---------- ---------- ----------
node1 SA_mmbp.so Idle Unknown TestWorked InitWorked
node1 SA_mmbr.so Idle Unknown TestWorked InitWorked
node2 SA_mmbp.so Idle KillWorked TestWorked InitWorked
node2 SA_mmbr.so Idle KillFailed TestWorked InitWorkedTo restore KillFailed that was displayed by "sdtool -s," follow the procedure below.
# sdtool -e # sdtool -b # sdtool -s Cluster Host Agent SA State Shut State Test State Init State ------------ ----- -------- ---------- ---------- ---------- node1 SA_mmbp.so Idle Unknown TestWorked InitWorked node1 SA_mmbr.so Idle Unknown TestWorked InitWorked node2 SA_mmbp.so Idle Unknown TestWorked InitWorked node2 SA_mmbr.so Idle Unknown TestWorked InitWorked
Set the wait time until I/O completion (WaitForIOComp) during failover triggered by a node failure (panic, etc.) according to the procedure described below.
Prechecking the shared disk
The standard setting for the I/O completion wait time during failover triggered by a node failure (for example, if a panic occurs during MMB asynchronous monitoring) is 0 seconds. However, if a shared disk that requires an I/O completion wait time is being used, this setting must be set to an appropriate value.
Information
ETERNUS Disk storage systems do not require an I/O completion wait time. Therefore, this setting is not required.
Note
If an I/O completion wait time is set, the failover time when a node failure (panic, etc.) occurs increases by that amount of time.
Setting the I/O completion wait time
Execute the following command, and set the wait time until I/O completion (WaitForIOComp) during failover triggered by a node failure (panic, etc.). For details about the "cldevparam" command, see the "cldevparam" manual page.
Execute the command in any node that is part of the cluster system.
# /etc/opt/FJSVcluster/bin/cldevparam -p WaitForIOComp value |
Alternatively, execute the following command and check the setting of the wait time until I/O processing is completed (WaitForIOComp).
# /etc/opt/FJSVcluster/bin/cldevparam -p WaitForIOComp value |
Starting the shutdown facility
Check that the shutdown facility has been started on all nodes.
# sdtool -s |
If the shutdown facility has already been started, execute the following command to restart the shutdown facility on all nodes:
# sdtool -r |
If the shutdown facility has not been started, execute the following command to start the shutdown facility on all nodes.
# sdtool -b |
Checking the status of the shutdown facility
Check the status of the shutdown facility on all nodes.
# sdtool -s |
This section describes the procedure for setting VmGuest (the shutdown agent in the virtual machine function) as the shutdown facility.
Be sure to perform "5.1.2.1 Checking the Shutdown Agent Information" before setting up the shutdown agent.
Note
Be sure to perform the following operations on the guest OS (node).
Setting up the shutdown daemon
If the node is a guest OS, execute the "clvmgsetup -a" command to register the guest OS information. Perform this on all guest OSes (nodes).
For details on how to use the "clvmgsetup" command, see the clvmgsetup man page.
# /etc/opt/FJSVcluster/bin/clvmgsetup -a host-user-name host-IPaddress |
Enter the host-user-name and host-IPaddress and User's Password that you verified in "5.1.2.1 Checking the Shutdown Agent Information".
The user name for logging in to the host OS on the virtual machine system that the guest OS belongs to.
Use FJSVvmSP for the user name.
The IP address of the host OS's administrative LAN with MMB, and the host OS is on the virtual machine system that the guest OS belongs to.
A user password for logging in to the host OS on the virtual machine system that the guest OS belongs to.
Execute the "clvmgsetup -l" command on all guest OSes (nodes) to check the registered guest OS information.
When information of the guest OS registered in the step 1 is not displayed, retry from the step 1.
# /etc/opt/FJSVcluster/bin/clvmgsetup -l
cluster-host-name host-IPaddress host-user-name domain-name
------------------------------------------------------------
node1 10.10.10.2 user1 node1 |
Log in to the host OS
The shutdown facility accesses the target node with SSH. Therefore, you need to authenticate yourself (create the RSA key) in advance, which is required when using SSH for the first time.
On all guest OSes (nodes), log in to the host OS IP address (host-IPaddress) using the host OS user name (host-user-name) that you registered in 1.
# ssh -l FJSVvmSP XXX.XXX.XXX.XXX The authenticity of host 'XXX.XXX.XXX.XXX (XXX.XXX.XXX.XXX)' can't be established. RSA key fingerprint is xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx. Are you sure you want to continue connecting (yes/no)? yes <- enter yes |
Setup the shutdown daemon
On all guest OSes (nodes), create /etc/opt/SMAW/SMAWsf/rcsd.cfg as below.
CFNameX,weight=weight,admIP=myadmIP:agent=SA_xxxx,timeout=20 |
CFNameX: Specify the CF node name of the cluster host weight: Specify the weight of the CF node myadmIP: Specify the IP address of the administrative LAN for your guest OS (node) SA_xxxx: Specify the name of the shutdown agent Here, "SA_vmgp" is specified.
Example) The following is a setup example
# cat /etc/opt/SMAW/SMAWsf/rcsd.cfg |
Note
The contents of the rcsd.cfg file of all nodes should be identical. If not, a malfunction will occur.
Start the shutdown facility
Check that the shutdown facility has already been started on all guest OSes (nodes).
# sdtool -s |
If the shutdown facility has already been started, execute the following to restart it on all guest OSes (nodes).
# sdtool -e |
If the shutdown facility has not been started, execute the following to start it on all guest OSes (nodes).
# sdtool -b |
Check the state of the shutdown facility
Check the state of the shutdown facility on all guest OSes (nodes).
# sdtool -s |
Note
If "InitFailed" is displayed as the initial status, it means that a problem occurred during initialization of that shutdown agent.
If "TestFailed" is displayed as the test status, it means that a problem occurred while the agent was testing whether or not the node displayed in the cluster host field could be stopped. Some sort of problem probably occurred in the software, hardware, or network resources being used by that agent.
When the maximum concurrent connections for SSH are "the number of cluster nodes" or less, the status of the shutdown facility may be displayed as InitFailed or TestFailed. Change the configuration to set up the maximum concurrent connections for SSH to be "the number of cluster nodes + 1"or more.
If "Unknown" is displayed as the stop or initial status, it means that the SF has still not executed node stop, path testing, or SA initialization. "Unknown" will be displayed temporarily until the actual status can be confirmed.
If TestFailed or InitFailed is displayed, check the SA log file or /var/log/messages. The log file records the reason why SA testing or initialization failed. After the failure-causing problem is resolved and SF is restarted, the status display changes to InitWorked or TestWorked.