ここでは、PRIMEQUESTのシャットダウン機構の設定手順について説明します。
シャットダウン機構の設定手順は、機種/構成により異なります。ハードウェアの機種/構成を確認して適切なシャットダウンエージェントを設定してください。
以下に機種/構成により必要なシャットダウンエージェントを示します。
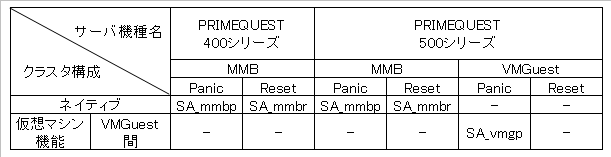
参照
シャットダウン機構についての詳細は、以下のマニュアルを参照してください。
“PRIMECLUSTER コンセプトガイド”の“3.3.1.8 PRIMECLUSTER SF”
“PRIMECLUSTER Cluster Foundation 導入運用手引書”の“8 シャットダウン機構(SF)”
注意
シャットダウンエージェント設定後は、正しいノードが強制停止できることを確認するため、クラスタノード強制停止テストを実施してください。クラスタノード強制停止テストの詳細については、“1.4 テスト”を参照してください。
シャットダウン機構に使用する管理LANをGLSで二重化する場合は、NIC切替方式の論理IPアドレス引継ぎ機能を使用し、シャットダウン機構の管理LANには物理IPアドレスを設定してください。
使用するシャットダウンエージェントについて、情報を確認します。
注意
シャットダウンエージェントの情報確認は、クラスタの初期設定前に実施してください。
■MMBの確認
MMBを使用している場合は、以下の設定を確認してください。
RMCPでMMBを制御するためのユーザの[Privilege]が「Admin」になっているか。
RMCPでMMBを制御するためのユーザの[Status]が「Enabled」になっているか。
RMCPでMMBを制御するためのユーザの設定を確認するには、MMB Web-UIにログインし、“Network Configuration”メニューの“Remote Server Management”画面から確認します。
上記のとおりに設定されていない場合は、上記のようにMMBを設定してください。
また、MMBに関する以下の情報をメモしてください。
RMCPでMMBを制御するためのユーザ名 (*1)
RMCPでMMBを制御するためのユーザのパスワード
*1) Adminの権限を付加されたユーザでなければなりません。
注意
MMBには以下の2種類のユーザが存在します。
MMB全体を制御するためのユーザ
RMCPでMMBを制御するためのユーザ
ここで確認するユーザはRMCPでMMBを制御するためのユーザです。誤らないようにしてください。
参照
MMBの設定方法、確認方法については、“PRIMEQUEST 500/400シリーズ リファレンスマニュアル: 基本操作/GUI/コマンド”を参照してください。
■仮想マシンの確認
VMGuest(仮想マシン機能におけるシャットダウンエージェント)を使用する場合、ゲストOSを強制停止するために、SSH で管理OSにログインします。そのため、以下の情報を設定する必要があります。
管理OSのIPアドレス
管理OSにログインするためのユーザ名(FJSVvmSP)
管理OSにログインするためのユーザのパスワード
管理OSにログインするためのユーザ名とパスワードについては、“3.2.1 管理OSの設定”で設定した情報をメモしてください。
クラスタインタコネクトの障害によりクラスタパーティションが発生した場合、まだ全ノードがユーザ資産にアクセスできる状態にあります。クラスタパーティションについては、“PRIMECLUSTER コンセプトガイド”の“2.2.2.1 データ整合性の保証”を参照してください。
ユーザ資産であるデータの整合性を保証するために、生存させるノード群と強制停止させるノード群を決定する必要があります。
PRIMECLUSTERでは、それぞれのノード群に対する重み付けを「生存優先度」と呼んでいます。
ノードの重みが大きいほど生存優先度は高くなり、小さくなるにつれて生存優先度は低くなります。ノード群の生存優先度が同じ場合は、ノード名がアルファベット順で最も早いノードを含むノード群が生存します。
生存優先度は、以下の計算で求められます。
生存優先度=SFのノードの重み(weight)+userApplicationの ShutdownPriority
ノードの重み。デフォルト値=1。シャットダウン機能の設定の際に指定します。
設定はuserApplication作成時の属性設定で行ってください。設定値の変更方法については、“8.5 userApplicationの運用属性の変更”を参照してください。
参照
userApplicationのShutdownPriority属性については、“PRIMECLUSTER RMS 導入運用手引書”の“11.1 ユーザ設定属性”を参照してください。
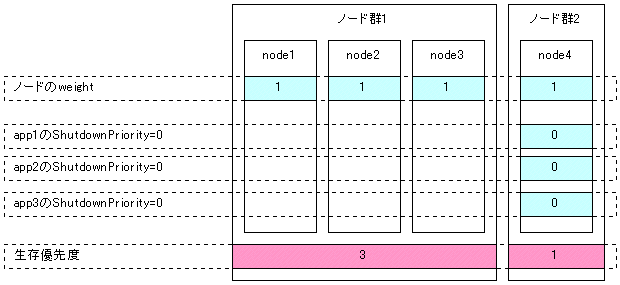
以下に、代表的なケースをもとに、生存優先度の設計指針を示します。
全てのノードのweightを1(デフォルト)に設定
全てのユーザアプリケーションのShutdownPriority属性を0(デフォルト)に設定
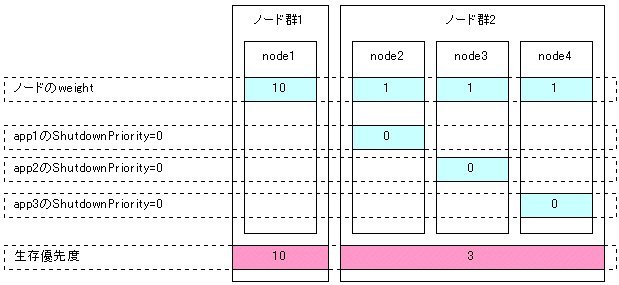
生存させるノードのweightをその他ノードのweightの合計の2倍以上の値に設定
全てのユーザアプリケーションのShutdownPriority属性を0(デフォルト)に設定
以下は、node1を生存させる場合の例です。
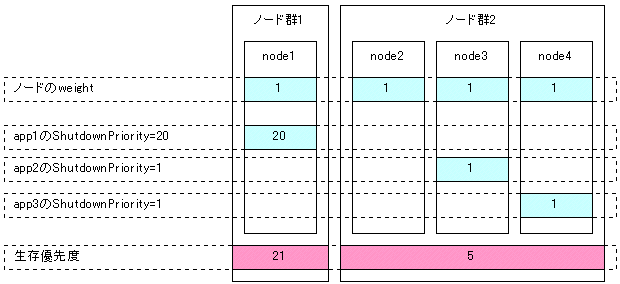
全てのノードのweightを1(デフォルト)に設定
動作を続けさせるユーザアプリケーションのShutdownPriority属性をその他のユーザアプリケーションのShutdownPriority属性と全てのノードのweightの合計の2倍以上の値に設定
以下は、app1が動作しているノードを生存させる場合の例です。
ここでは、MMBをシャットダウン機構に設定する手順について説明します。
シャットダウン機構を設定する前にシャットダウンエージェントの情報確認を行ってください。
■ MMB情報の登録
注意
ここで説明するMMB情報の登録は、“5.1.1 CF、CIPの設定” の後、また、後述の“■シャットダウンデーモンの設定”の前に実施してください。
全ノードでclmmbsetup -a コマンドを実行し、MMB情報を登録します。
clmmbsetupコマンドの使用法については、clmmbsetupのマニュアルページを参照してください。
# /etc/opt/FJSVcluster/bin/clmmbsetup -a mmb-user Enter User's Password: Re-enter User's Password:
mmb-userとUser's Passwordには、“5.1.2.1 シャットダウンエージェントの情報確認”で確認した以下の内容を入力します。
RMCPでMMBを制御するためのユーザ名
RMCPでMMBを制御するためのユーザのパスワード
注意
ユーザのパスワードに使用可能な文字は英数字のみです。記号は使用できません。
全ノードでclmmbsetup -l コマンドを実行し、登録されたMMB情報を確認します。
手順1.で登録したMMB情報が全ノードで出力されない場合、再度手順1.からやり直してください。
# /etc/opt/FJSVcluster/bin/clmmbsetup -l
cluster-host-name user-name
-----------------------------------
node1 mmb-user
node2 mmb-user
#■ シャットダウンデーモンの設定
全ノードで/etc/opt/SMAW/SMAWsf/rcsd.cfgを以下のような内容で作成します。
CFNameX,weight=weight,admIP=myadmIP: agent=SA_xxx,timeout=20 CFNameX,weight=weight,admIP=myadmIP: agent=SA_xxx,timeout=20
CFNameX : クラスタホストのCFノード名を指定します。 weight : SFのノードの重みを指定します。 myadmIP : 自ノードの管理LANのIPアドレスを指定します。 SA_xxx : シャットダウンエージェントの名前を指定します。 MMB経由でノードをパニックさせる場合 SA_mmbp を指定します。 MMB経由でノードをリセットさせる場合 SA_mmbr を指定します。
例)2ノード構成の設定例を以下に記載します。
# cat /etc/opt/SMAW/SMAWsf/rcsd.cfg
node1,weight=2,admIP=fuji2:agent=SA_mmbp,timeout=20:agent=SA_mmbr,timeout=20 node2,weight=2,admIP=fuji3:agent=SA_mmbp,timeout=20:agent=SA_mmbr,timeout=20
注意
rcsd.cfgファイルで設定するシャットダウンエージェントは、SA_mmbp、SA_mmbrの順番で両方のシャットダウンエージェントを設定してください。
rcsd.cfgファイルの内容は全ノードで同一にしてください。同一でない場合、誤動作することがあります。
参考
/etc/opt/SMAW/SMAWsf/rcsd.cfgファイルを作成する場合、/etc/opt/SMAW/SMAWsf/rcsd.cfg.mmb.templateファイルを雛型として使用することができます。
■ MMB非同期監視デーモンの起動
MMB非同期監視デーモンの起動
全ノードでMMB非同期監視デーモンが起動済か確認してください。
# /etc/opt/FJSVcluster/bin/clmmbmonctl“The devmmbd daemon exists.”が表示された場合、MMB非同期監視デーモンは起動済です。
“The devmmbd daemon does not exist.”が表示された場合、MMB非同期監視デーモンは起動していません。以下を実行し、MMB非同期監視デーモンを起動してください。
# /etc/opt/FJSVcluster/bin/clmmbmonctl startシャットダウン機構の起動
全ノードでシャットダウン機構が起動済か確認してください。
# sdtool -sシャットダウン機構が起動済の場合、以下を実行して全ノードでシャットダウン機構を再起動してください。
# sdtool -e # sdtool -b
シャットダウン機構が起動していない場合、以下を実行して全ノードでシャットダウン機構を起動してください。
# sdtool -bシャットダウン機構の状態確認
全ノードでシャットダウン機構の状態を確認してください。
# sdtool -s参考
初期状態がInitFailed と表示された場合は、そのシャットダウンエージェントの初期化で問題が発生したことを示しています。
テスト状態にTestFailed と表示された場合は、クラスタホスト欄に表示されたノードを停止できるかどうかをエージェントがテストしている間に問題が発生したことを示しています。 このような場合には、そのエージェントが使用しているソフトェア、ハードウェア、ネットワーク資源に何らかの問題が生じていることが考えられます。
停止状態または初期状態にUnknown と表示された場合は、SF がノードの停止、経路のテスト、SA の初期化をまだ行っていないことを表しています。 テスト状態および初期状態には、実際の状態が確認されるまで一時的にUnknown が表示されます。
TestFailed またはInitFailed が表示された場合は、SA ログファイルまたは、/var/log/messages を確認してください。ログファイルには、SA のテストまたは初期化に失敗した理由が記録されています。失敗した問題が解決されSF が再起動されると、状態の表示がInitWorked またはTestWorked に変わります。
注意
OS起動直後に“sdtool -s”を実行すると、自ノードのテスト状態にTestFailedと表示される場合がありますが、これはsnmptrapdデーモンが起動中のため表示されるもので、正しい動作です。シャットダウン機構が起動した10分後に“sdtool -s”を実行すると、テスト状態にTestWorkedが表示されます。
以下の例では、自ノード(node1)のテスト状態にTestFailedが表示されています。
# sdtool -s
Cluster Host Agent SA State Shut State Test State Init State
------------ ----- -------- ---------- ---------- ----------
node1 SA_mmbp.so Idle Unknown TestFailed InitWorked
node1 SA_mmbr.so Idle Unknown TestFailed InitWorked
node2 SA_mmbp.so Idle Unknown TestWorked InitWorked
node2 SA_mmbr.so Idle Unknown TestWorked InitWorkedまた、同じ理由により、OS起動直後に以下のメッセージが出力される場合があります。
3084: Monitoring another node has been stopped. SA SA_mmbp.so to test host nodename failed SA SA_mmbr.so to test host nodename failed
これも、snmptrapdデーモンが起動中のため出力されるもので、正しい動作です。シャットダウン機構が起動した10分後に以下
のメッセージが出力されます。
3083: Monitoring another node has been started.
SA_mmbr シャットダウンエージェントによるノードの強制停止を行うと、以下のメッセージが出力される場合がありますが、これはノードの強制停止に時間がかかっているもので、正しい動作です。
Fork SA_mmbp.so(PID pid) to shutdown host nodename : SA SA_mmbp.so to shutdown host nodename failed : Fork SA_mmbr.so(PID pid) to shutdown host nodename : SA SA_mmbr.so to shutdown host nodename failed : MA SA_mmbp.so reported host nodename leftcluster, state MA_paniced_fsnotflushed : MA SA_mmbr.so reported host nodename leftcluster, state MA_paniced_fsnotflushed : Fork SA_mmbp.so(PID pid) to shutdown host nodename : SA SA_mmbp.so to shutdown host nodename succeeded
上記メッセージが出力された後に“sdtool -s”を実行すると、SA_mmbp.so の停止状態に KillWorked が表示され、SA_mmbr.so の停止状態に KillFailed が表示されます。
以下は、node1 から node2 の強制停止を行い、上記メッセージが出力された後に“sdtool -s”を実行した場合の表示例です。
# sdtool -s
Cluster Host Agent SA State Shut State Test State Init State
------------ ----- -------- ---------- ---------- ----------
node1 SA_mmbp.so Idle Unknown TestWorked InitWorked
node1 SA_mmbr.so Idle Unknown TestWorked InitWorked
node2 SA_mmbp.so Idle KillWorked TestWorked InitWorked
node2 SA_mmbr.so Idle KillFailed TestWorked InitWorked“sdtool -s”で表示された KillFailed を復旧する場合は、以下の手順で復旧してください。
# sdtool -e # sdtool -b # sdtool -s Cluster Host Agent SA State Shut State Test State Init State ------------ ----- -------- ---------- ---------- ---------- node1 SA_mmbp.so Idle Unknown TestWorked InitWorked node1 SA_mmbr.so Idle Unknown TestWorked InitWorked node2 SA_mmbp.so Idle Unknown TestWorked InitWorked node2 SA_mmbr.so Idle Unknown TestWorked InitWorked
パニックなどのノードダウンによる切替え時、I/Oが完了するまでの待ち時間 (WaitForIOComp)の設定は、以下の手順で実施してください。
共用ディスクの事前確認
MMB非同期監視のパニックなどのノードダウンによる切替え時のI/O完了待ち時間は標準で0秒を設定していますが、I/O完了待ち時間が必要な共用ディスクを使用する場合、この値を適切な値に設定する必要があります。
参考
ETERNUS ディスクアレイの場合、I/O完了待ち時間は不要ですので、本設定を行う必要はありません。
注意
I/O完了待ち時間を設定した場合、パニックなどのノードダウン時の切替え時間がその時間分増加します。
I/O完了待ち時間の設定
以下のコマンドを実行し、パニックなどのノードダウンによる切替え時のI/Oが完了するまでの待ち時間(WaitForIOComp)を設定してください。cldevparamコマンドについて、詳しくはcldevparamのマニュアルページを参照してください。
なお、クラスタシステムを構成する任意の1ノードで実行してください。
# /etc/opt/FJSVcluster/bin/cldevparam -p WaitForIOComp value
また、以下のコマンドを実行し、I/Oが完了するまでの待ち時間(WaitForIOComp)の設定を確認してください。
# /etc/opt/FJSVcluster/bin/cldevparam -p WaitForIOComp value
シャットダウン機構の起動
全ノードでシャットダウン機構が起動済か確認してください。
# sdtool -sシャットダウン機構が起動済の場合、以下を実行して全ノードでシャットダウン機構を再起動してください。
# sdtool -rシャットダウン機構が起動していない場合、以下を実行して全ノードでシャットダウン機構を起動してください。
# sdtool -bシャットダウン機構の状態確認
全ノードでシャットダウン機構の状態を確認してください。
# sdtool -sここでは、VmGuest(仮想マシン機能におけるシャットダウンエージェント)をシャットダウン機構に設定する手順について説明します。
シャットダウン機構を設定する前に“5.1.2.1 シャットダウンエージェントの情報確認”を行ってください。
注意
下記の操作はすべてのゲストOS(ノード)で実行してください。
●シャットダウンデーモンの設定
ノードがゲストOSである場合、clvmgsetup -a コマンドを実行し、ゲストOSの情報を登録します。全ゲストOS(ノード)上で実行してください。
clvmgsetupコマンドの使用法については、clvmgsetupのマニュアルページを参照してください。
# /etc/opt/FJSVcluster/bin/clvmgsetup -a host-user-name host-IPaddress Enter User's Password: |
host-user-name と host-IPaddress と User's Password には、“5.1.2.1 シャットダウンエージェントの情報確認”で確認した以下の内容を入力します。
ゲストOSが属する仮想マシンシステムの管理OSにログインするためのユーザ名
ユーザ名には、FJSVvmSP を指定してください。
ゲストOSが属する仮想マシンシステムの管理OSで、MMBに接続された管理LANのIPアドレス
ゲストOSが属する仮想マシンシステムの管理OSにログインするためのユーザのパスワード
全ゲストOS(ノード)上でclvmgsetup -l コマンドを実行し、登録されたゲストOS情報を確認します。
手順1.で登録したゲストOSの情報が全ノードで出力されない場合、再度手順1.からやり直してください。
#/etc/opt/FJSVcluster/bin/clvmgsetup -l |
管理OSへのログイン
シャットダウン機構は、対象ノードへSSHでアクセスするため、SSH初回時のユーザ問い合わせ( RSA 鍵の生成)を済ませておく必要があります。
全ゲストOS(ノード)上で、1. で登録した管理OS の IP アドレス (host-IPaddress) に対して、1. で登録した管理OSのユーザ名 (host-user-name) でログインを実行してください。
# ssh -l FJSVvmSP XXX.XXX.XXX.XXX |
シャットダウンデーモンの設定
全ゲストOS (ノード)で /etc/opt/SMAW/SMAWsf/rcsd.cfgを以下のような内容で作成します。
CFNameX,weight=weight,admIP=myadmIP:agent=SA_xxxx,timeout=20
CFNameX :クラスタホストのCFノード名を指定します。 weight :SFのノードの重みを指定します。 myadmIP :自ゲストOS(ノード)の管理LANのIPアドレスを指定します。 SA_xxxx :シャットダウンエージェントの名前を指定します。 ここでは、“SA_vmgp” を指定します。
例)設定例を以下に示します。
# cat /etc/opt/SMAW/SMAWsf/rcsd.cfg
node1,weight=2,admIP=fuji2:agent=SA_vmgp,timeout=20
node2,weight=2,admIP=fuji3:agent=SA_vmgp,timeout=20注意
rcsd.cfgファイルの内容は全ノードで同一にしてください。同一でない場合誤動作します。
シャットダウン機構の起動
全ゲストOS(ノード)でシャットダウン機構が起動済か確認してください。
# sdtool -s
シャットダウン機構が起動済の場合、以下を実行して全ゲストOS(ノード)でシャットダウン機構を再起動してください。
# sdtool -e # sdtool -b
シャットダウン機構が起動していない場合、以下を実行して全ゲストOS(ノード)でシャットダウン機構を起動してください。
# sdtool -b
シャットダウン機構の状態確認
全ゲストOS(ノード)でシャットダウン機構の状態を確認してください。
# sdtool -s参考
初期状態がInitFailed と表示された場合は、そのシャットダウンエージェントの初期化で問題が発生したことを示しています。
テスト状態にTestFailed と表示された場合は、クラスタホスト欄に表示されたノードを停止できるかどうかをエージェントがテストしている間に問題が発生したことを示しています。 このような場合には、そのエージェントが使用しているソフトェア、ハードウェア、ネットワーク資源に何らかの問題が生じていることが考えられます。
SSHの最大同時接続数が"クラスタ構成ノード数"以下の場合、シャットダウン機構の状態が InitFailed または TestFailed で表示されることがあります。SSHの最大同時接続数が"クラスタ構成ノード数+1"以上となるように設定を変更してください。
停止状態または初期状態にUnknown と表示された場合は、SF がノードの停止、経路のテスト、SA の初期化をまだ行っていないことを表しています。 テスト状態および初期状態には、実際の状態が確認されるまで一時的にUnknown が表示されます。
TestFailed またはInitFailed が表示された場合は、SA ログファイルまたは、/var/log/messages を確認してください。ログファイルには、SA のテストまたは初期化に失敗した理由が記録されています。失敗した問題が解決されSF が再起動されると、状態の表示がInitWorked またはTestWorked に変わります。