CMP2.0の複数件検索時の高速化機能とは
CMP2.0の複数件検索時の高速化機能とは、以下のメソッド実行時にPrimary Keyだけでなく、すべてのカラムデータを一括で検索するSQL文を実行し、SQL文の発行回数を削減するオプションのことです。
CMP2.0 Entity Beanの複数件finderメソッド
1:多 relationshipのCMRに対するgetアクセッサメソッド
多:多 relationshipのCMRに対するgetアクセッサメソッド
V7.0以前と8.0での、複数件検索処理の処理イメージは以下のとおりです。
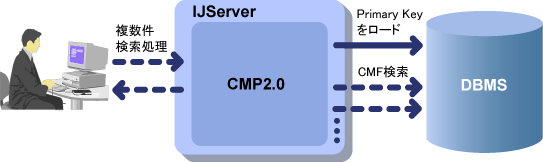
V7.0以前でCMP2.0 Entity Beanの複数件finderメソッドを実行すると、Primary Keyだけをデータベースからロードして、Primary Keyに対応するEJB objectをクライアントに返却しています。
Primary Key以外のデータ(CMF)については、各EJB objectに対して、CMFの初回アクセス時にデータベースからデータをロードしていました。この処理は、特定のPrimary Keyのデータだけにアクセスする場合には、余分なデータをロードすることがないため、効率よく処理することができますが、すべてのデータをデータベースからロードするような場合には、データベースへのアクセス回数が多くなります。
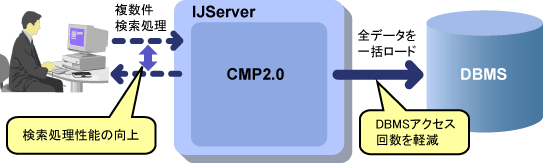
8.0でCMP2.0 Entity Beanの複数件finderメソッドを実行した場合は、レコードのデータを1度にすべてロードする「CMP2.0の複数件検索時の高速化機能」を使用することで、すべてのデータをデータベースからロードするような処理の場合にも、高速にデータベースからデータをロードすることができます。
この機能は1:多、または多:多のrelationshipを持つEntity Beanに対してCMRのgetアクセッサメソッドを実行する場合に、relationshipを持つ複数のEntity Beanのデータをロードする時にも有効です。
設定方法
設定は、Interstage管理コンソール、またはコマンドを使用します。
Interstage管理コンソールについては、Interstage管理コンソールヘルプを参照してください。
コマンドについて詳細は、“リファレンスマニュアル(コマンド編)”を参照してください。
すべてのCMP2.0 Entity Beanとrelationshipの複数件検索を高速化する場合、[システム] > [環境設定]タブで、「CMP2.0の複数件検索高速化」に“全Bean、全relationshipに適用する”を設定してください。
デフォルトは“Bean、relationshipごとに設定する”です。この場合、CMP2.0 Entity Bean、relationshipごとの設定ができます。
isj2eeadminコマンドを使用します。
CMP2.0 Entity Bean単位で複数件検索を高速化するかを設定する場合は、[システム] > [ワークユニット] > “ワークユニット名” > “モジュール名” > “Bean名” > [アプリケーション環境定義] > [Interstage拡張情報]で行います。
ejbdefimportを使用します。
CMP2.0 Entity Bean単位で複数件検索を高速化するかを設定する場合は、[システム] > [ワークユニット] > “ワークユニット名” > “モジュール名” > “Bean名” > [アプリケーション環境定義] > [CMRマッピング定義]で行います。
ejbdefimportを使用します。
効果
SQL文の発行回数を削減することによって、データベースとの通信回数が削減されるため、検索処理性能が向上します。
CMP2.0 Entity Beanの複数件finderメソッド
1:多 relationshipのCMRに対するgetアクセッサメソッド
多:多 relationshipのCMRに対するgetアクセッサメソッド
以下に、複数件検索の高速化オプションを使用しない場合と使用した場合に、発行されるSQL文の違いについて説明します。
複数件検索finderメソッド実行時
ここでは、以下の場合を例にして説明します。
複数件finderメソッドがfindAll
CMFがidとname
CMFに対応するカラムがidとname
DBMSのテーブル名がEMPLOYEE
複数件検索の高速化オプションを使用しない場合
SQL文は、以下のタイミングで発行されます。
複数件finderメソッド(findAll)の使用例 | SQL文発行のタイミング |
|---|---|
Collection employees = employeeHome.findAll(); | SELECT id FROM EMPLOYEE |
Iterator iter = employees.iterator(); |
|
| |
while (iter.hasNext()) { | |
EmployeeLocal e = (EmployeeLocal)iter.next(); | |
System.out.println("Id: " + e.getId()); | SELECT name,age,・・・FROM EMPLOYEE WHERE id = ? |
System.out.println("Name: " + e.getName()); |
|
} |
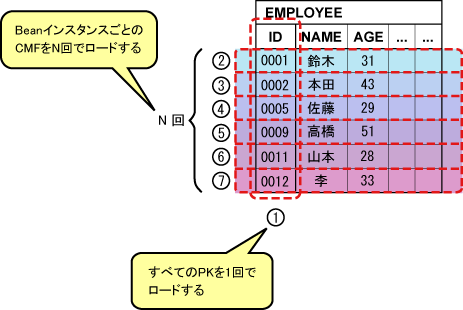
複数件finderメソッド(findAll)の実行時に、Primary Keyフィールド(id)をロードします。
各Beanインスタンスの最初のCMFアクセス時(getIdメソッド実行時)に、CMFフィールドをすべてロードします。
SQL文発行数の総計は、以下の図に示すようにN+1回になります(「+1」は(1)の検索が必要なため)。
複数件検索の高速化オプションを使用する場合
SQL文は、以下のタイミングで発行されます。
複数件finderの使用例 | SQL文発行のタイミング |
|---|---|
Collection employees = employeeHome.findAll(); | SELECT id,name,age,・・・FROM EMPLOYEE |
Iterator iter = employees.iterator(); |
|
| |
while (iter.hasNext()) { | |
EmployeeLocal e = (EmployeeLocal)iter.next(); | |
System.out.println("Id: " + e.getId()); | |
System.out.println("Name: " + e.getName()); | |
} |
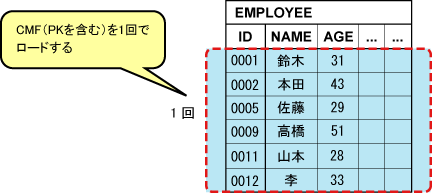
複数件finderメソッド(findAll)の実行時に、すべてのカラムデータを取得するSQL文を発行します。
コンテナは、ResultSetからレコードをすべて取得しメモリ上にキャッシュします。CMFアクセス時には、値をキャッシュから取得します。
複数件finderメソッドを呼び出すと、CMF(PKフィールドを含む)をすべてロードするので、SQL文発行数の総計は、以下の図に示すように1回となります。
1:多、多:多relationshipのgetアクセッサメソッド実行時
ここでは、以下の場合を例にして説明します。
getアクセッサメソッドがgetEmployeesメソッド
データベースのテーブル名がEMPLOYEE
複数件検索の高速化オプションを使用しない場合
SQL文は、以下のタイミングで発行されます。
1:多、多:多 relationshipのアクセッサ使用例 | SQL文発行のタイミング |
|---|---|
CompanyLocal fj = companyHome.findByPrimaryKey("FJ"); | SELECT name FROM COMPANY WHERE name = ? |
Collection employees = fj.getEmployees(); | SELECT fk_employee_id FROM COMPANY_EMPLOYEE WHERE fk_company_name = ? |
Iterator iter = employees.iterator(); |
|
| |
while (iter.hasNext()) { | |
EmployeeLocal e = (EmployeeLocal)iter.next(); | |
System.out.println("Id: " + e.getId()); | SELECT name,age,・・・FROM EMPLOYEE WHERE id = ? |
System.out.println("Name: " + e.getName()); |
|
} |
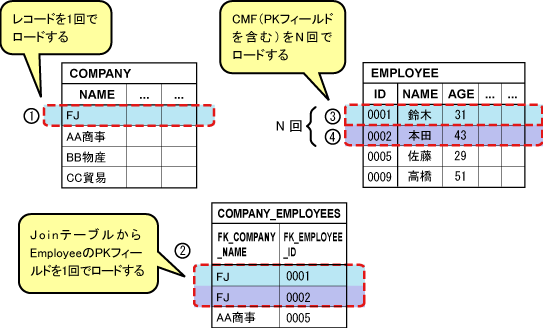
1:多、多:多relationshipのCMRのgetアクセッサメソッドを呼び出すと、JoinテーブルからPrimary Keyフィールドをロードします。
各Beanインスタンスの、最初のCMFアクセス時に、CMFをすべてロードします。
テーブルへのSQL文発行数の総計は、以下の図に示すようにN+2回になります(「+2」は(1)と(2)の検索が必要なため)。
複数件検索の高速化オプションを使用する場合
SQL文は、以下のタイミングで発行されます。
1:多、多:多 relationshipのアクセッサの使用例 | SQL文発行のタイミング |
|---|---|
CompanyLocal fj = companyHome.findByPrimaryKey("FJ"); | SELECT name FROM COMPANY WHERE name = ? |
Collection employees = fj.getEmployees(); | SELECT e.id,e.name,e.age, ・・・ FROM EMPLOYEE e LEFT OUTER JOIN COMPANY_EMPLOYEE ce ON e.id = ce.fk_employee_id WHERE ce.fk_company_name = ? |
Iterator iter = employees.iterator(); |
|
| |
while (iter.hasNext()) { | |
EmployeeLocal e = (EmployeeLocal)iter.next(); | |
System.out.println("Id: " + e.getId()); | |
System.out.println("Name: " + e.getName()); | |
} |
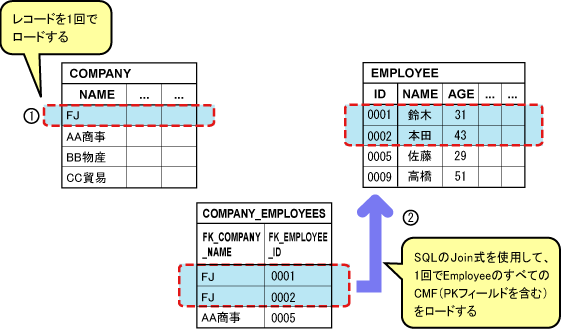
1:多、多:多relationshipのアクセッサメソッドの実行時に、すべてのカラムデータを取得するSQL文を発行します。
コンテナは、ResultSetからレコードをすべて取得しキャッシュします。CMFアクセス時には、値をキャッシュから取得します。
relationshipのアクセッサメソッドを呼び出すと、CMF(PKフィールドを含む)をすべてロードするので、SQL文発行数の総計は、以下の図に示すように2回となります。
注意
インスタンス管理モードがReadOnlyの場合、プロセス内で一度アクセスしたレコードデータはキャッシュされます。同じレコードにアクセスした場合には、プライマリキーが分かればキャッシュされているデータが使用されます。
このため、複数件検索時にプライマリキーだけを検索するデフォルトの設定より、本オプションを設定した場合に、性能が劣化する可能性があるため、本オプションの設定は無効となります。
EJB QLクエリでDISTINCT句(検索結果の重複している行を取り除いて結果を返す)を設定しているfinderメソッドに本機能を設定した場合、設定は有効になりません。
これは、DISTINCT句が設定されているfinderメソッドに本機能を適用した場合、Primary Keyフィールドだけでなく、CMFフィールドの重複確認も行ってしまい、本機能を適用せずにPrimary Keyフィールドのみ重複確認を行った場合の方が性能が良い場合があるためです。
データベースによっては、DISTINCT句との併用がサポートされていないデータ型が存在する場合もあります。
DISTINCT句が使用されたEJB QLに本機能を適用しようとした場合には、起動時に警告が出力されます。