

| ETERNUS SF Storage Cruiser Install Guide 13.2 - Solaris (TM) Operating System / Linux / Microsoft(R) Windows(R) - |
|
Contents
|
Admin servers in cluster systems ensure high-availability and maximize uptime.
A cluster system provides high-availability by operating two or more servers as one virtual server.
If a system is run with only one server machine, and the server machine or the server application fails, all operations would stop until it is rebooted.
In a cluster system where two or more server machines are linked together, if the primary server machine becomes unusable due to an error on the server machine or the application being run, the secondary server machine can restart the application that was running on the failed server machine to resume the operation, reducing the operation stop time. The switchover from a failed server to another server is called failover.
These two or more linked server machines are referred to as a cluster of server machines and clustering server machines are referred to as nodes in the cluster system.
Clusters of server machines are classified into one of the following types.
Standby class
This is a cluster of standby nodes that stand ready to take over from operating nodes. The mode can be one of the following four modes.
1:1 standby
A cluster system consist one operating node and one standby node. The operating node is operational and the standby node stands ready to take over if needed. This operation mode ensures the continuous availability of cluster applications even after failover.
n:1 standby
A cluster consists of n operating nodes and one standby node. The n operating nodes run different operations and the standby node stands ready to take over from all of the operating nodes. This operation mode ensures the availability of cluster applications even after failover. It is also cost-effective because only one node serves as the standby node for cluster applications.
Mutual standby
A cluster consists of two nodes with both operating and standby applications. The two nodes run different operations and stand ready to take over from each other. If one of these nodes fails, the other node runs both of the operations. In this operation mode, two or more cluster applications will be operating on the failover node in the event of a node failure.
Cascade
A cluster consist three or more nodes. One of the nodes is the operating node and the others are the standby nodes. If the operating node fails, cluster applications are switched to one of the standby nodes. Even if a failover fails, cluster applications are moved to another standby node. When one node is stopped in the event of node failure or scheduled downtime such as system maintenance or upgrading, the redundant configuration can be maintained. This operation mode ensures the continuous availability of cluster applications.
Scalable class
This is a cluster that allows multiple server machines to operate concurrently for performance improvement and degradation. The difference from the standby class is that this class does not divide the nodes into the operating type and the standby type. If one of the nodes in the cluster fails, the operation is degraded to the other servers.

For details, refer to the version of "PRIMECLUSTER Installation and Administration Guide" for the respective operating System.
The following pieces of ETERNUS SF Storage Cruiser's software are supported:
manager [Solaris OS]
manager [Linux]
This section describes the procedure for manager installation on a cluster system.

To distinguish two physical nodes, one is called the primary node and the other is called the secondary node. The primary node indicates an operating node on which the cluster service (cluster application) runs at initial boot time, and the secondary node indicates a standby node on which the cluster service (cluster application) stands ready at initial boot time.
To operate managers as cluster services (cluster applications) in a cluster system, install and configure manager software on each node. Be sure to check the device names and the mount point names when configuring the shared disks.

Operations that are run where the manager is set up as cluster service (cluster application) is referred to as manager operations is respectively. Collectively, these operations are called Manager operations.
For details about PRIMECLUSTER, refer to the version of "PRIMECLUSTER Installation and Administration Guide" for the respective operating System.
Manager installation on a cluster system requires the following resources.
Resources used in the cluster system
Takeover IP addresses for the admin servers
Allocate new unique IP addresses in the network that are used for the admin servers in the cluster system with PRIMECLUSTER Ipaddress resource creation. This step can be skipped if the IP addresses for the existing cluster services (cluster applications) are used.
Shared disks for the admin servers
Configure PRIMECLUSTER GDS volumes that will store shared data for the admin servers. The number of required volumes is as follows.
|
Name |
Number |
Content |
|
Shared data disk for the server |
1 (Note 1) |
Shared data storage destination for the server |
Note1: When a server operates as the server, both the admin servers use one shared disk.
Note2: Necessary when Interstage Application Server Smart Repository is installed
Resources used outside the cluster system
Port numbers for the admin servers
Allocate the port numbers for the admin servers, which are set as described in "4.1.4.1 /etc/services configuration" (in Solaris operating system) or "4.2.4.1 /etc/services configuration" (in Linux).
The ETERNUS SF Storage Cruiser shared disks include the following directories that are used with ETERNUS SF Storage Cruiser.
For the admin server
Required disk space is calculated from the sum of static disk space and dynamic disk space. For details, please refer to "4.1.1.2.5 Static disk space" and "4.1.1.2.6 Dynamic disk space" (in Solaris operating system) or "4.2.1.2.5 Static disk space" and "4.2.1.2.6 Dynamic disk space" (in Linux).
|
Section number |
Directory |
Required disk space (Unit : MB) |
|---|---|---|
|
1 |
/etc |
6 |
|
2 |
/var |
552 + Repository for storage resource manager Note 1) |
Note 1: For how to calculate the "repository for storage resource manager", please refer to "1. Repository for manager" in "4.1.1.2.6 Dynamic disk space" (in Solaris operating system) or "1. Repository for manager" in "4.2.1.2.6 Dynamic disk space" (in Linux).
Install manager.
Using similar steps on the primary node and the secondary node, perform the procedure from the beginning of "4.1.3 Installation procedure" (in Solaris OS) or "4.2.3 Installation procedure" (in Linux) for manager.
Please do not install software on the shared disks.
Please do not perform the procedure described in "4.1.4 Post-installation setup" (in Solaris operating system) or "4.2.4 post-installation setup" (in Linux) for manager at this point.
This section describes the procedure for setting up managers as cluster services (cluster applications) in a cluster system.
Prior to setup, decide whether to add the manager operations to existing cluster services (cluster applications) or as new cluster services (cluster applications).
Check that the manager installation is complete. For the admin server, check that the procedure from the beginning of "4.1.3 Installation procedure" (in Solaris operating system) or "4.2.3 Installation procedure" (in Linux) is complete.
Use the cluster setup command for configuring "LOGICAL_MANAGER_IP" in "/etc/opt/FJSVssmgr/current/sanma.conf".
Set up managers on the admin servers.
The following figure shows the setup flow.
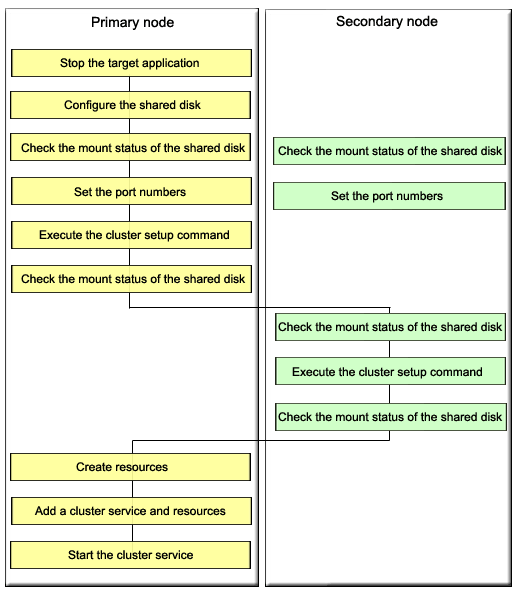
Set up managers as cluster services (cluster applications) using the following steps. Only a user with system administrator privileges can conduct the following procedures.
When rebooting the system after installing managers, stop the managers before performing the following procedure.
When adding a manager to an existing cluster service (cluster application), stop the cluster service (cluster application) using the cluster admin of the cluster system.
Configure the shared disk using PRIMECLUSTER GDS.
For details, refer to "PRIMECLUSTER Global Disk Services Guide (Solaris(TM) operating system version)" of the respective operating system.
Mount the shared data disk for the server on the primary node.
Specify the port numbers for the server in "/etc/services" on both the primary node and the secondary node.
Perform the procedure described in "4.1.4.2 Administrator login account creation" (in Solaris operating system) or "4.2.4.2 Administrator login account creation" (in Linux) only on the primary node. The created login account information will be set on the shared data disk when the cluster setup command is executed.
Execute the cluster setup command on the primary node.
After preventing access by other users to the shared data disk for the server, execute the following cluster setup command on the primary node.
|
# /opt/FJSVssmgr/cluster/esc_clsetup -k Primary -m Mount_point_on_the_shared_data_disk_for_the_ server -i Server_takeover_IP_address <RETURN> |
Check the configurations.
Information specified with the command is output. Check the output information and enter "y". To cancel setup at this point, enter "n".
# /opt/FJSVssmgr/cluster/esc_clsetup -k Primary -m /zzz -i 10.10.10.10 <RETURN>
ETERNUS SF Storage Cruiser settings are as follows.
Cluster system : PRIMECLUSTER
Node type : Primary
Mount point : /zzz
IP Address : 10.10.10.10
Manager cluster setup : Are you sure? [y,n,?] |
Setup on the primary node is executed.
|
FJSVrcx:INFO:27700:esc_clsetup:primary node setup completed |
The command execution runs cluster setup and sets the "LOGICAL_MANAGER_IP" configuration of /etc/opt/FJSVssmgr/current/sanma.conf on the shared disk into sanma.conf.
|
LOGICAL_MANAGER_IP="10.10.10.10"; |
Unmount the shared data disk for the server from the primary node.
Mount the shared data disk for the server on the secondary node.
Execute the cluster setup command on the secondary node.
After preventing access by other users to the shared data disk for the server, execute the following cluster setup command on the secondary node.
|
# /opt/FJSVssmgr/cluster/esc_clsetup -k Secondary -m Mount_point_on_the_shared_data_disk_for_the _server <RETURN> |
Check the configurations.
Information specified with the command is output. Check the output information and enter "y". To cancel setup at this point, enter "n".
# /opt/FJSVssmgr/cluster/esc_clsetup -k Secondary -m /zzz <RETURN>
Systemwalker Resource Coordinator settings are as follows.
Cluster system : PRIMECLUSTER
Node type : Secondary
Mount point : /zzz
IP Address : 10.10.10.10
Manager cluster setup : Are you sure? [y,n,?] |
Setup on the secondary node is executed.
|
FJSVrcx:INFO:27701:esc_clsetup:secondary node setup completed |
Unmount the shared data disk for the server from the secondary node.
Create a cluster service (cluster application).
For details, refer to "PRIMECLUSTER Installation and Administration Guide" for the respective operating system.
For Solaris OS:
Use userApplication Configuration Wizard for cluster system to create the following required PRIMECLUSTER resources on the cluster service (cluster application).
After creating the resources a. to d. described below, create the cluster service (cluster application) as follows.
Select "Standby" for the admin server configuration.
For attribute values, set AutoStartUp to "yes", AutoSwitchOver to "HostFailure|ResourceFailure|ShutDown", and HaltFlag to "yes".
When using Interstage Application Server Smart Repository, or creating a hot standby configuration, set StandbyTransitions to "ClearFaultRequest|StartUp|SwitchRequest".
Then create the following resources on the created cluster service (cluster application).
Cmdline resource (Create the Cmdline resources for ESC.)
Select "Cmdline" for Resource creation in the userApplication Configuration Wizard to create the resources through path input, and make the following configurations.
Start script:
/opt/FJSVssmgrcluster/cmd/rcxclstartcmd
Stop script:
/opt/FJSVssmgr/cluster/cmd/rcxclstopcmd
Check script:
/opt/FJSVssmgr/cluster/cmd/rcxclcheckcmd
Flag (attribute value) settings: When a value other than "NO" is specified for the cluster service (cluster application) attribute value "StandbyTransitions", set ALLEXITCODES to "yes" and STANDBYCAPABLE to "yes".
When using Interstage Application Server Smart Repository, manager must start after Interstage Application Server Smart Repository starts.
Ipaddress resource (Configure the takeover logical IP address for the cluster system.)
Select Ipaddress for Resource creation in the userApplication Configuration Wizard and configure the takeover logical IP address. Configure the takeover logical IP address for the NIC of clients. For the takeover network type, select "IP address takeover".
Fsystem resource (Configure the mount point of the shared data disk for the server.)
Select Fsystem for Resource creation in the userApplication Configuration Wizard and configure the file system. If no mount point definition exists, please refer to the "PRIMECLUSTER Installation and Administration Guide" and define the mount point.
Gds resource (Specify the configuration created for the shared data disk for the server.)
Select Gds for Resource creation in the userApplication Configuration Wizard and configure the shared disk. Specify the configuration created for the shared data disk for the server.
For Linux:
Use RMS Wizard for cluster system to create the following PRIMECLUSTER resources on the cluster service (cluster application).
To create a new cluster service (cluster application), select "Application-Create" to specify a primary node for Machines[0] and a secondary node for Machines[1] to create. For settings of "Machines+Basics", set "yes" to AutoStartUp, "HostFailure|ResourceFailure|ShutDown" to a value of AutoSwitchOver and "yes" to HaltFlag.
Then, create the following resources a) through d) on the created cluster service (cluster application).
Perform settings by means of the RMS Wizard to any of the nodes configured in a cluster
Cmdline resources (Create Cmdline resources for ESC)
Select "CommandLines" with the RMS Wizard to perform the following settings.
Start script :
/opt/FJSVssmgr/cluster/cmd/rcxclstartcmd
Stop script :
/opt/FJSVssmgr/cluster/cmd/rcxclstopcmd
Check script :
/opt/FJSVssmgr/cluster/cmd/rcxclcheckcmd
Flag settings (attribute value): If anything other than "without value" is specified for attribute value StandbyTransitions of the cluster service (cluster application), set the Flags ALLEXITCODES(E) and STANDBYCAPABLE(O) to "Enabled".

If shared with the operations management server or division management server for Systemwalker Centric Manager, make settings so that they are started after Centric Manager.
Gls resources (Set a takeover logical IP address to be used for cluster system.)
Select "Gls:Global-Link-Sevices" with the RMS Wizard to set a takeover logical IP address The takeover logical IP address is set to the client NIC. If the configuration information for takeover logical IP address has not been created, refer to "PRIMECLUSTER Global Link Services Instruction Manual (Redundancy function in transmission lines) (Linux)" to create it.
Fsystem resources (Set mount points of management server-shared disks.)
Select "LocalFileSystems" with the RMS Wizard to set file systems. If mount points have not been defined, refer to "PRIMECLUSTER Installation Guide (Linux)" to define.
Gds resources (Specify the settings for management server shared disks.)
Select "Gds:Global-Disk-Sevices" with the RMS Wizard to set shared disks. Specify the settings created for management server-shared disks.
Perform the procedure as instructed in "4.1.4.3 Rebooting the system" (In Solaris operating system) or " 4.2.4.3 Rebooting the system" (In Linux) on both the primary node and the secondary node.
After cluster setup, the following daemons become resources of the cluster services (cluster applications) as the manager operations.
Operation control daemon
Execute the following command in a command line.
| # ps -ef | grep -v grep | grep /opt/FJSVssmgr/jre/bin/java | grep cruiser=daemon <RETURN> |
If a line containing the following character strings is output, the manager monitoring daemon is active.
| /opt/FJSVssmgr/jre/bin/java -Dcruiser=daemon |
This section provides advisory notes on admin server operation in cluster systems.
/etc/opt/FJSVssmgr/current/sanma.conf configuration
Specify a logical IP address as the takeover IP address for the LOGICAL_MANAGER_IP parameter in /etc/opt/FJSVssmgr/current/sanma.conf. However, the cluster setup command usually configures the takeover IP address automatically.
Cluster service (cluster application) switchover
An event that occurred during cluster service switchover cannot be output.
Troubleshooting material
To collect troubleshooting material, refer to "E.1 Troubleshooting information" of the "ETERNUS SF Storage Cruiser User's Guide".
Commands
For the command execution methods, there is no difference between regular operation and cluster operation.
Messages
Please refer to "Appendix J Messages and corrective actions" of the "ETERNUS SF Storage Cruiser User's Guide" and "A.8 Cluster-related messages".
This section describes how to delete cluster environments for the manager operations.
The following figure shows the manager operation cluster environment deletion flow.
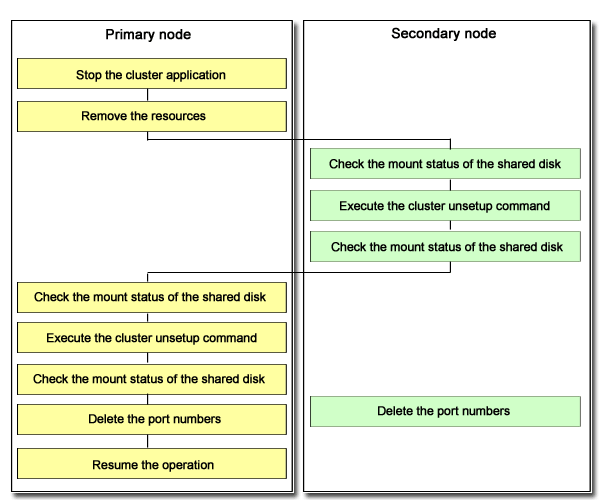
Delete cluster environments using the following steps. Perform the deletion procedures on the server admin server in the cluster system respectively. Only a user with system administrator privileges can conduct the following procedures.
Stop the cluster service (cluster application) configured for the manager operation using the cluster admin of the cluster system.
Delete resources for management tasks registered to the target cluster service (cluster application).
For details, refer to the "PRIMECLUSTER Installation and Administration Guide" for the respective operating system version.
For Solaris:
Remove the following resources with the userApplication Configuration Wizard:
Cmdline resource (For ESC)
Ipaddress resource (if not used at all)
Gds resource (if not used at all)
Fsystem resource (mount point of the shared data disk for the admin server)
For Linux:
Using the RMS Wizard for cluster system delete the resources for management tasks registered to the target cluster service (cluster application). If the cluster service consists of only the resources for management server, delete also the cluster service (cluster application).
Delete the following resources with the RMS Wizard.
Cmdline resources (for ESC)
Gls resources (if not used for other purpose
Gds resources (not available for other purposes)
Fsystem fdxouf resources (mount points of shared data disks for operations management server)
Deletion with the RMS Wizard is performed with respect to any of the nodes in a cluster.
Check that the shared data disk for the server is unmounted on the primary node and the secondary node.
Mount the shared data disk for the server on the secondary node.
Execute the cluster unsetup command on the secondary node.
After preventing access by other users to the shared data disk for the server, execute the following cluster unsetup command on the secondary node.
|
# /opt/FJSVssmgr/cluster/esc_clunsetup <RETURN> |
Option specification is not required under normal conditions, but specify the -l option if local free disk space on the secondary node is insufficient.
Check the configurations (no option in this example).
Check the configurations and enter "y". To cancel unsetup at this point, enter "n".
ETERNUS SF Storage cruiser settings were as follows.
Cluster system : PRIMECLUSTER
Node type : Secondary
Mount point : /zzz
IP Address : 10.10.10.10
Mode : Normal (restore from Shared Disk)
Manager cluster deletion : Are you sure? [y,n,?] |
Deletion on the secondary node is executed.
|
FJSVrcx:INFO:27703:esc_clunsetup:secondary node deletion completed |
Unmount the shared data disk for the admin server from the secondary node.
Mount the shared data disk for the admin server on the primary node.
Execute the cluster unsetup command on the primary node.
After preventing access by other users to the shared data disk for the server, execute the following cluster unsetup command on the primary node.
|
# /opt/FJSVssmgr/cluster/esc_clunsetup <RETURN> |
Option specification is not required under normal conditions, but specify the -l option if local free disk space on the primary node is insufficient.
Check the configurations (no option in this example).
Check the configurations and enter "y". To cancel unsetup at this point, enter "n".
ETERNUS SF Storage Cruiser settings were as follows.
Cluster system : PRIMECLUSTER
Node type : Primary
Mount point : /zzz
IP Address : 10.10.10.10
Mode : Normal (restore from Shared Disk)
Manager cluster deletion : Are you sure? [y,n,?] |
Deletion on the primary node is executed.
|
FJSVrcx:INFO:27702:esc_clunsetup:primary node deletion completed |
Unmount the shared data disk for the server from the primary node.
Delete the port numbers for the server from /etc/services on both the primary node and the secondary node.
Start the cluster service (cluster application) using the cluster admin of the cluster system. If the cluster service (cluster application) was deleted in step 2, this step is not required.
Execute the following command on both the primary node and the secondary node to stop nwsnmp-trapd.
|
# /opt/FJSVswstt/bin/mpnm-trapd stop <RETURN> |
Uninstall managers from both the primary node and the secondary node using the procedure as described in "9.1 [Solaris OS] Manager uninstallation" (In Solaris operating system) or "9.2 [Linux] Manager Uninstallation.
This section describes messages output at the time of cluster environment setup and unsetup.
The cluster setup on the primary node ended normally.
Proceed to the next operation according to the cluster environment configuration procedure.
The cluster setup on the secondary node ended normally.
Proceed to the next operation according to the cluster environment configuration procedure.
The cluster deletion on the primary node ended normally.
Proceed to the next operation according to the cluster environment configuration procedure.
The cluster deletion on the secondary node ended normally.
Proceed to the next operation according to the cluster environment configuration procedure.
The command was canceled.
No specific action is required.
The shared disk data deletion is completed.
If any node where the cluster environment is not deleted exists, delete the cluster environment in force mode (using -f when executing esc_clunsetup). After the deletion is completed, uninstall the manager.
The cluster unsetup in force mode was completed.
Uninstall the manager.
Except for shared disk data deletion, the cluster unsetup in force mode is completed.
Check that the shared disk is accessible, and delete shared disk data (using esc_clunsetup with -e MountPoint).
The option is incorrect. Usage will be output.
Check the command then re-execute.
The IP address format is incorrect.
Check the IP address.
The cluster setup command or the cluster unsetup command is already active.
Check whether the cluster setup command or the cluster unsetup command is running somewhere else.
The command was activated by a non-OS administrator (non-root user).
Execute the command as an OS administrator (root user).
The shared disk has not been mounted on mount point mountpoint.
Check the mount status of the shared disk for admin server shared data.
If the mount destination mountpoint contains "/" at the end, delete the last "/" and re-execute.
Cluster software software has not been installed.
Check whether the cluster setup command or the cluster unsetup command is running.
The cluster environment of node type nodetype has been configured on the current node.
Check the cluster environment status on the current node.
The cluster environment of the node type specified with the cluster setup command has been configured on another node.
Check whether the node type specified with the executed command is correct.
Check whether the cluster environment of the node type specified with the executed command has already been configured on another node.
The cluster environment has not been configured on the primary node.
Check whether the shared disk for mounted admin server shared data is correct.
Configure the cluster environment on the primary node.
Data different from the previous one was specified.
Check the argument values of the command.
The option is incorrect. Usage will be output.
Check the command then re-execute.
The cluster environment on the secondary node is not deleted.
Check whether the shared disk for mounted admin server shared data is correct.
Delete the cluster environment then re-execute the command.
The cluster environment has not been configured.
Check whether the admin server cluster environment has been configured.
The cluster setup failed. The cluster environment configurations are invalid.
Delete the cluster environment in force mode then uninstall the manager.
The module for cluster setup has not been installed.
Check whether the manager installation is valid.
An inconsistency was found in the cluster environment configurations.
Collect the following files and contact Fujitsu technical staff.
The file indicated by file
For manager: All files under /opt/FJSVssmgr/cluster/env
The cluster environment configurations are invalid.
Delete the cluster environment in force mode (using -f when executing esc_clunsetup). After the deletion is completed, uninstall the manager.
Data on the shared disk is invalid.
Delete the cluster environment in force mode (using -f when executing esc_clunsetup). After the deletion is completed, uninstall the manager.
The property value property of the cluster setup command does not match the configuration value value on the admin server manager for which cluster setup is done.
Specify the same configuration value to perform setup.
The cluster setup failed.
Check the execution environment then re-execute the command. If the situation is not improved, contact Fujitsu technical staff.
The cluster setup is in normal condition. The unsetup command cannot be executed specifying shared disk data deletion.
Shared disk data deletion (using esc_clunsetup with -e MountPoint) cannot be performed.
Delete the cluster environment following the procedure given in "A.7.2 Cluster environment deletion procedure (details)".
The cluster unsetup failed.
Delete the cluster environment in force mode (using -f when executing esc_clunsetup). After the deletion is completed, uninstall the manager.
The shared disk data deletion failed.
Check the execution environment then re-execute the command. If the situation is not improved, contact Fujitsu technical staff.
|
Contents
|