モニタデーモンは、両ノード間で互いに確認データの送受信を繰り返すことで正本のデータベースの監視を行います。
以下の事象を検知した場合、通信環境、または、相手ノードに異常が発生したと認識します。
副系ノードのモニタデーモンにおいて、正系ノードからの確認データを受信したあとに指定されたタイムアウト時間を超えても次の確認データが到着しない場合
正系ノード、または、副系ノードにて通信環境の異常を検知した場合
異常発生を認識したあとの動作は、ノード間の監視設定の自動ノード切替えの指定により異なります。
自動ノード切替えを行う場合
両ノードの動作状態により、正系ノードでの運用継続、または、ノードの自動切替えを行います。
自動ノード切替えを行わない場合
正系ノードは、データベースの更新が待ち状態になります。
ユーザ判断により、正系ノードでの運用継続、または、ノードの強制切替えを行ってください。
異常を認識したときの動作を、以下に示します。
異常の種類 | 自動ノード切替えを行う(注1) | 自動ノード切替えを行わない |
|---|---|---|
通信環境の異常 | 以下のいずれかとなります。
| データベースへの更新が待ち状態になります。 |
正系ノードのダウン | 自動ノード切替えを行います。 | 以下のいずれかの対処を行ってください。
|
副系ノードのダウン | 正系ノードを継続して使用します。 | データベースへの更新が待ち状態になります。 |
注1) GCMが停止している場合は、自動ノード切替えを行わない場合と同じ対処を行ってください。
注2) 正系ノードで行ったデータベースの更新は、副系ノードに反映されません。
設計の方針
モニタデーモンによるノード間の監視を正しく動作させるために、各パラメタを業務要件に合わせて、誤検知や検知の遅延がないように設計する必要があります。
本設計は、「どの程度で異常と判断するか」などを考慮して設計してください。
以下に設計の方針または推奨値を説明します。特に理由がない場合、以下を基準に設計および実機確認することを推奨します。
POLL_TIME(送受信間隔時間):1000ミリ秒(省略値と同じ)
POLL_WAITOUT(タイムアウト時間):5秒(省略値と同じ)
一時的な負荷などで誤検知しない時間を指定します。例えば、専用の強固なネットワークで接続している場合は、5秒を設定します。
CONNECT_RETRY(リトライ回数、再接続タイムアウト時間、リトライ間隔):5回、1秒、1秒(省略値と同じ)
GCM_FAILOVER:YES(省略値はNO)
ノード間の通信環境に異常が発生した場合に、正系ノードを使用するか、副系ノードに切替えるかを自動で判断します。運用を継続できるようにYESを設定することを推奨します。この場合、GCMが必要となります。
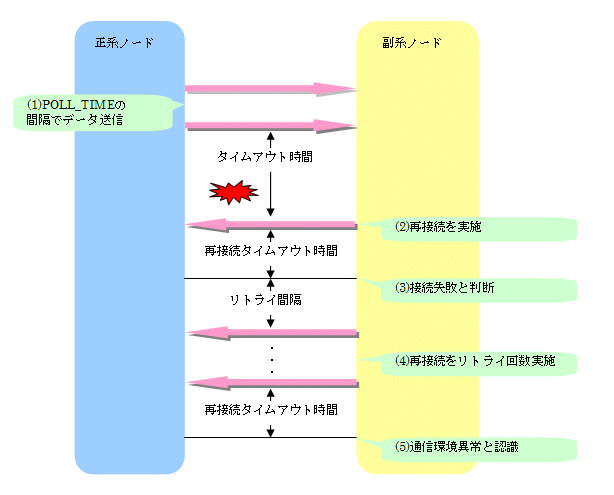
(1) DBミラーリング動作環境ファイルに指定した間隔で、データを送信します。
(2) 次のデータがDBミラーリング動作環境ファイルに指定したタイムアウト時間を超えても届かない場合は、正系ノードに対して再接続を行います。
(3) DBミラーリング動作環境ファイルに指定した、再接続タイムアウト時間を経過しても接続完了しない場合は、接続失敗と判断します。
(4) DBミラーリング動作環境ファイルに指定したリトライ間隔経過後、再度接続を行います。再接続はリトライ回数だけ繰り返します。
(5) 再接続をリトライ回数実行しても接続できない場合、通信環境異常と認識します。