PRIMECLUSTERシャットダウン機構 (PRIMECLUSTER SF) は、クラスタシステム内でユーザ資産に対する競合が発生するような異常処理時に、他のノードを停止させることを保証する機能を提供します。
注意
CF によりクラスタノードの再起動が確認され、ノードが停止状態にあったことが保証できる場合は、PRIMECLUSTER SF によるノードの停止は行いません。
PRIMECLUSTER SF は主に以下のコンポーネントで構成されます。
シャットダウンエージェントはリモートクラスタノードの確実な停止を保証します。シャットダウンエージェントは、クラスタノードのアーキテクチャによって異なります。
シャットダウンエージェントは以下の機能を提供します。
ノードの強制停止
異常が発生したノードの強制停止を保証します。
接続確認(シャットダウンエージェントのテスト)
ノードの強制停止で使用するオプションハードウェアや仮想マシン機能への接続が正しく行えるかを定期的 (10分間隔) に確認します。
PRIMECLUSTER SFでは、以下のシャットダウンエージェントを提供します。
RCI (SA_pprcip, SA_pprcir)
Remote Cabinet Interface
SPARC Enterprise Mシリーズに搭載されるハードウェアの1つ、RCIを利用して、他ノードを意図的にパニックまたはリセットさせることで、確実なノード停止を実現します。
XSCF (SA_xscfp, SA_xscfr, SA_rccu, SA_rccux)
eXtended System Control Facility
SPARC Enterprise Mシリーズに搭載されるハードウェアの1つ、XSCFを利用して、他ノードを意図的にパニックまたはリセットさせることで、確実なノード停止を実現します。
また、コンソールにXSCFを使用している場合は、他ノードにbreak信号を送信して確実なノード停止を実現します。
XSCF SNMP (SA_xscfsnmpg0p, SA_xscfsnmpg1p, SA_xscfsnmpg0r, SA_xscfsnmpg1r, SA_xscfsnmp0r, SA_xscfsnmp1r)
eXtended System Control Facility Simple Network Management Protocol
SPARC M10、M12 に搭載されるハードウェアの1つ、XSCF を利用して、他ノードを意図的にパニックまたはリセットさせることで、確実なノード停止を実現します。
ALOM (SA_sunF)
Advanced Lights Out Management
SPARC Enterprise T1000、T2000 の ALOM を利用して、他ノードに break 信号を送信して確実なノード停止を実現します。
ILOM (SA_ilomp, SA_ilomr)
Integrated Lights Out Manager
SPARC Enterprise T5120、T5220、T5140、T5240、T5440、SPARC T3、T4、T5、T7、S7シリーズのILOM を利用して、他ノードを意図的にパニックまたはリセットさせることで、確実なノード停止を実現します。
KZONE(SA_kzonep, SA_kzoner, SA_kzchkhost)
Oracle Solaris カーネルゾーン
SPARC M10、M12、SPARC T4、T5、T7、S7シリーズでOracle Solaris カーネルゾーンを使用している場合、他ノード(カーネルゾーン)を意図的にパニックまたはリセットさせることで、確実なノード停止を実現します。
また、グローバルゾーンホストの状態を確認し、グローバルゾーンホストが停止した場合に他ノード(カーネルゾーン)が停止状態であると判断します。グローバルゾーンホストの強制停止は行いません。
IPMI (SA_ipmi)
Intelligent Platform Management Interface
PRIMERGY に搭載されるハードウェアの1つであるiRMC (integrated Remote Management Controller)をIPMIで操作して、他ノードをシャットダウンさせることで、確実なノード停止を実現します。
kdump (SA_lkcd)
PRIMERGYで kdump を使用して、他ノードをパニックさせることで、確実なノード停止を実現します。
iRMC (SA_irmcp, SA_irmcr, SA_irmcf)
PRIMEQUEST 3000に搭載されるハードウェアのiRMC/MMBを利用して、他ノードを意図的にパニック、リセット、または電源切断させることで、確実なノード停止を実現します。
注意
PRIMERGYのiRMCでは本シャットダウンエージェントは使用できません。
ICMP (SA_icmp)
ネットワーク経路を使用して他ノードの状態を確認し、他ノードから応答がない場合に停止状態であると判断します。
他ノードの強制停止は行いません。
また、他ノードの状態の確認に使用するネットワークインタフェースがすべて停止していた場合、ノードの状態を確認できないため、SA_icmpはノードを運用状態とみなします。
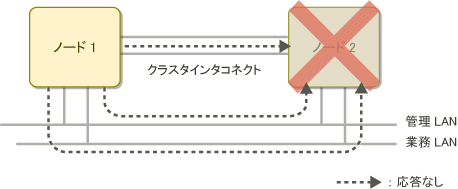
以下の図は、 2ノードのクラスタシステムにおいて、1つのノード(ノード2)が停止した場合のSA_icmp による状態確認の例です。
指定されたすべてのネットワーク経路でノード2から応答がなかった場合、SA_icmpはノード2が停止状態であると判断します。
図2.3 他ノードが停止している場合の SA_icmp による状態確認
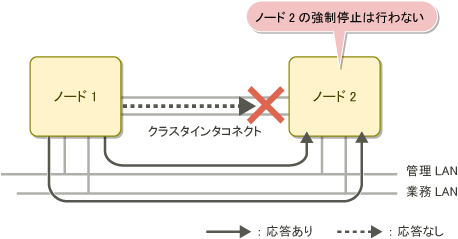
以下の図は、 2ノードのクラスタシステムにおいて、クラスタインタコネクトが故障した場合のSA_icmp による状態確認の例です。
指定されたネットワーク経路のいずれかで、ノード2からノード1に応答があった場合、SA_icmp はノード2が運用状態であると判断します。
この場合、SA_icmp はノード2の強制停止を行いません。
図2.4 クラスタインタコネクトが故障している場合の SA_icmp による状態確認
VMCHKHOST (SA_vmchkhost)
KVM 仮想マシン機能で管理OSにクラスタシステムを導入している場合、管理OSのクラスタシステムと連携してゲストOSの状態を確認します。
他ノードの強制停止は行いません。
libvirt (SA_libvirtgp, SA_libvirtgr)
PRIMERGY、PRIMEQUEST 3000 シリーズで KVM 仮想マシン機能を使用している場合、他ノード(ゲストOS)を意図的にパニックまたはリセットさせることで、確実なノード停止を実現します。
VMware vCenter Server連携 (SA_vwvmr)
VMware vCenter Serverと連携し、他ノード(ゲストOS)を意図的に電源断させることで、確実なノード停止を実現します。
FUJITSU Hybrid IT Service FJcloud-O / FJcloud-ベアメタル API (SA_vmk5r)
FUJITSU Hybrid IT Service FJcloud-O / FJcloud-ベアメタル APIを利用して、他ノード(仮想サーバ/ベアメタルサーバ)を意図的にシャットダウンまたは電源断させることで、確実なノード停止を実現します。
OpenStack API (SA_vmosr)
OpenStack APIを利用して、他ノード(インスタンス)を意図的に再起動させることで、確実なノード停止を実現します。
AWS CLI (SA_vmawsAsyncReset)
AWS CLIを利用して、他ノード(インスタンス)を意図的にシャットダウンさせることで、確実なノード停止を実現します。
Azure CLI (SA_vmazureReset)
Azure CLIを利用して、他ノード(仮想マシン)を意図的に電源断、または再起動させることで、確実なノード停止を実現します。
ニフクラ API (SA_vmnifclAsyncReset)
ニフクラ APIを利用して、他ノード(サーバ)を意図的に電源断させることで、確実なノード停止を実現します。
非同期監視は、ハードウェア特性を活かしてノードの状態を監視し、ノードダウンを即時に検出します。PRIMECLUSTERシステムは、クラスタインタコネクトを利用した、ハートビートの送信と応答によるノードの状態監視を定周期間隔で行っていますが、非同期監視を利用することにより、より即時的なノードのダウン検出を実現します。
非同期監視は以下の機能を提供します。
ノードの状態監視
非同期監視は、ハードウェアが提供する機能を利用したノードの状態監視を行います。突然のシステムパニックや電源切断など、万が一他のノードに異常が発生した場合、SFにその異常を通知します。また、システム負荷 (System Load) が著しく高いことが原因で、クラスタノード間でのハートビート要求の送信と応答が一時的に途切れた場合でも、非同期監視がオプションハードウェアを経由してノードの状態を正確に判断します。
ノードの強制停止
SA (シャットダウンエージェント) としての機能を提供し、異常が発生したノードの強制停止を保証します。
接続確認(シャットダウンエージェントのテスト)
SA ( シャットダウンエージェント) としての機能を提供し、ノードの状態監視やノードの強制停止で使用するオプションハードウェアへの接続が正しく行えるかを定期的 (10分間隔) に確認します。
PRIMECLUSTER SFでは、以下の非同期監視を提供します。
SPARC Enterprise Mシリーズに搭載されるハードウェアの1つ、RCIを利用してノードの状態を監視する機能です。ハードウェア本体に標準で実装されているシステム監視機構(System Control Facility: SCFと略する)がハードウェアの状態を監視し、その状態をソフトウェアに通知することでノードダウンを判断することができます。
また、他ノードを意図的にパニックまたはリセットさせることで確実な強制停止を実現し、ユーザ資産への競合を防ぎます。
XSCF/ILOMを使用して、クラスタシステムを構成する各ノードのコンソールに表示されるメッセージを監視する機能です。パニック発生時等のコンソールメッセージを他ノードが検出し、メッセージ出力ノードのノードダウンを判断します。コンソール非同期監視は通常、数珠状に1対1の関係で他ノードの状態を監視しており、異常が発生してノードがダウンした場合、ダウンノードが監視していたノードを監視する役目を、その他のノードに引き継ぎます。また、ノードに対してbreak 信号を送信して確実なノード停止を行います。
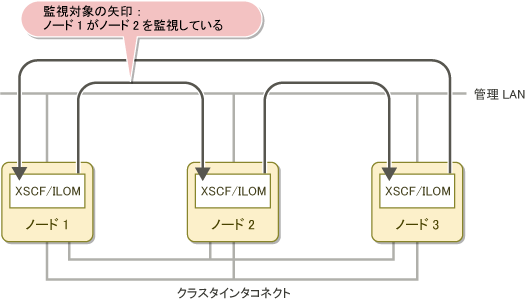
ノードがダウンした場合の監視の引き継ぎについて、3 ノードで構成されるクラスタシステムを例に示します。
以下の図は、 3ノードのクラスタシステムにおいて、1つのノードが停止した場合に監視機能がどのように引き継がれるかを示しています。矢印は、どのノードがどのノードを監視しているかを表します。
図2.5 正常稼動時のコンソール非同期監視の処理
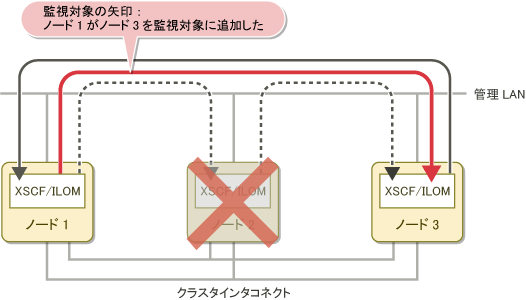
ノード2に異常が発生してダウンすると、以下の処理が実行されます。
ノード1はノード3の状態監視を開始します。
以下のメッセージがノード1の/var/adm/messagesファイルに出力されます。
FJSVcluster: INFO: DEV: 3044: The console monitoring agent took over monitoring (node: targetnode)FJSVcluster: 情報: DEV: 3044: コンソール非同期監視機能の監視対象にノードtargetnodeを追加しました。以下の図は、ノード2が停止した場合に、ノード1がノード3を監視対象ノードとして追加する様子を示しています。
図2.6 ノード異常発生時のコンソール非同期監視の処理
注意
コンソール非同期監視が停止していたときに監視機能の引き継ぎが行われた場合、停止していたコンソール非同期監視が再開されます。
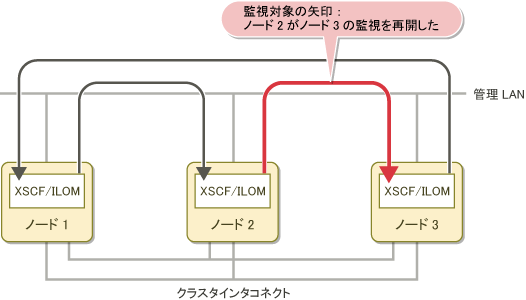
ノード2が異常から復旧後に起動してくると、以下の処理が実行されます。
従来の正常起動時の監視形態に戻ります。
以下のメッセージがノード1の/var/adm/messages ファイルに出力されます。
FJSVcluster: INFO: DEV: 3045: The console monitoring agent cancelled to monitor (node: targetnode)FJSVcluster: 情報: DEV: 3045: コンソール非同期監視機能の監視対象からノードtargetnodeを削除しました。以下の図は、クラスタに復旧したノード2がノード3の監視を再開する様子を示しています。
図2.7 ノード復旧時のコンソール非同期監視の処理
注意
コンソール非同期監視では、コンソールのメッセージを監視しているため、突然の電源切断の状態を判断できずLEFTCLUSTER状態が発生します。本現象が発生した場合は、ノードにDOWNマークを付ける必要があります。DOWNマークの付けかたについては、“PRIMECLUSTER Cluster Foundation 導入運用手引書”を参照してください。
SPARC M10、M12 に搭載されるシステム監視機構(eXtended System Control Facility: XSCFと略する)を利用して、ノードの状態を監視する機能です。
XSCFがハードウェアの状態を監視し、その状態をSNMP(Simple Network Management Protocol)を使用して、ソフトウェアに通知することで、ノードダウンを判断することができます。
また、他ノードを意図的にパニックまたはリセットさせることで、確実な強制停止を実現し、ユーザ資産への競合を防ぎます。
PRIMEQUEST 3000に搭載されるハードウェアのiRMCとMMBを利用して、ノードの状態を監視する機能です。ハードウェア本体に標準で実装されているiRMCとMMBがハードウェアの状態を監視し、その状態をソフトウェアに通知することでノードダウンを判断することができます。
また、他ノードを意図的にパニック、リセット、または電源切断させることで確実な強制停止を実現し、ユーザ資産への競合を防ぎます。
注意
PRIMERGYのiRMCでは本非同期監視は使用できません。
注意
RCI 非同期監視のノード状態の監視は、/var/adm/messages ファイルに以下のメッセージ(a) が出力されてから、(b) が出力されるまでの間機能しています。
コンソール非同期監視の場合は、それぞれ(c) と(d) に該当します。
SNMP非同期監視の場合は、それぞれ(e) と(f) に該当します。
iRMC非同期監視の場合は、それぞれ (g) と (h) に該当します。
ノード状態の監視が機能していない状態では、ノードを強制的に停止する機能が正常に動作しないことがあります。
(a) FJSVcluster: INFO: DEV: 3042: The RCI monitoring agent has been started
FJSVcluster: 情報: DEV: 3042: RCI非同期監視機能を開始しました。
(b) FJSVcluster: INFO: DEV: 3043: The RCI monitoring agent has been stopped
FJSVcluster: 情報: DEV: 3043: RCI非同期監視機能を停止しました。
(c) FJSVcluster: INFO: DEV: 3040: The console monitoring agent has been started (node:monitored node name) FJSVcluster: 情報: DEV: 3040: コンソール非同期監視機能を開始しました。
(node:監視対象ノード名)(d) FJSVcluster: INFO: DEV: 3041: The console monitoring agent has been stopped (node:monitored node name) FJSVcluster: 情報: DEV: 3041: コンソール非同期監視機能を停止しました。
(node:監視対象ノード名)(e) FJSVcluster: INFO: DEV: 3110: The SNMP monitoring agent has been started.
FJSVcluster: 情報: DEV: 3110: SNMP 非同期監視を開始しました。
(f) FJSVcluster: INFO: DEV: 3111: The SNMP monitoring agent has been stopped.
FJSVcluster: 情報: DEV: 3111: SNMP 非同期監視を停止しました。
(g) FJSVcluster: INFO: DEV: 3120: The iRMC asynchronous monitoring agent has been started.
FJSVcluster: 情報: DEV: 3120: iRMC 非同期監視を開始しました。
(h) FJSVcluster: INFO: DEV: 3121: The iRMC asynchronous monitoring agent has been stopped.
FJSVcluster: 情報: DEV: 3121: iRMC 非同期監視を停止しました。