Java APIでは、以下に示す操作ができます。
検索条件に一致するXML文書の件数を取得する
検索条件に一致するXML文書を指定した形式で取得する
特定のXML文書をすべて取得する
検索条件に一致するXML文書をソートして取得する
検索条件に一致するXML文書を連続して取得する
検索条件に一致するXML文書の値を集計して取得する
これらの操作を組み合わせることによって、さまざまなアプリケーションを作成することができます。
参考
ダイレクトアクセスキーを使ったデータ検索も可能です。
ダイレクトアクセスキー機能の詳細については、“第6章 ダイレクトアクセス機能”を参照してください。
データを検索するサンプルプログラムは、“F.1 データの検索”を参照してください。
以降に、データの検索を行うアプリケーションの作成方法について説明します。
条件に一致するデータを取り出す前に、件数のみ取得したい場合があります。
このような場合、setRequestメソッドの返信要求件数(requestCount)に0を指定し、件数のみを取得します。
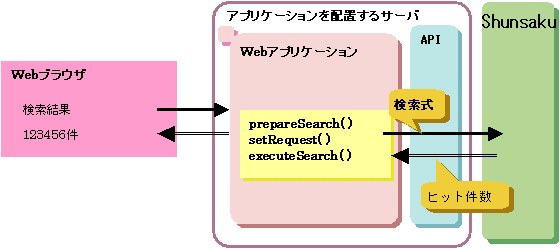
条件に一致するXML文書の件数を取得する場合の流れについて、以下の図に示します。
図11.1 条件に一致するXML文書の件数を取得する場合の流れ
記述例
ShunConnection con = new ShunConnection(); String queryExpression = "/document/base/prefecture == '大阪'"; String returnExpression = "/"; ShunPreparedStatement pstmt = con.prepareSearch(queryExpression, returnExpression); (1) |
ShunPreparedStatementオブジェクトは、prepareSearchメソッドのパラメタに検索式とリターン式を指定して作成します。
検索式およびリターン式の詳細は、“付録B 検索式、リターン式およびソート式の書式”を参照してください。
setRequestメソッドに返信開始番号と返信要求件数を指定します。返信要求件数に0を指定して、件数のみ取得します。
検索の実行はexecuteSearchメソッドを使用します。検索した結果としてShunResultSetオブジェクトが作成されます。
getHitCountメソッドで、検索条件に一致するXML文書の件数を取得します。
ShunResultSetオブジェクトとShunPreparedStatementオブジェクトは、使用後にそれぞれのcloseメソッドで必ず解放します。
Webアプリケーションでは、画面にすべての検索結果を表示するのではなく、任意の件数ごとにページを制御することが一般的です。
このような場合、setRequestメソッドに返信開始番号(position)と返信要求件数(requestCount)を指定して、取得するデータの件数を制御します。
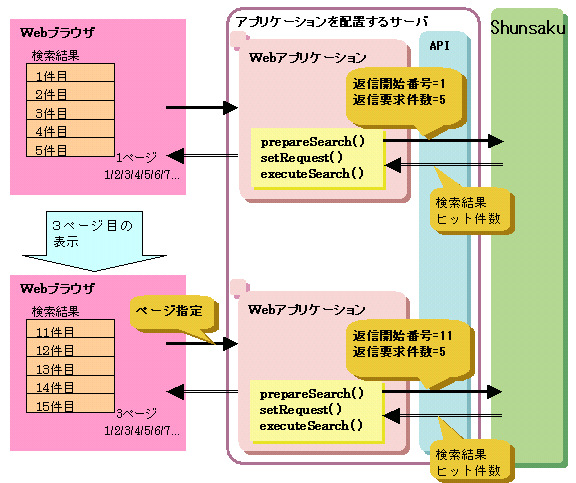
件数に応じて検索した結果を取得する場合の流れについて、以下の図に示します。
図11.2 件数に応じて検索した結果を取得する場合の流れ
記述例
ShunConnection con = new ShunConnection(); String queryExpression = "/document/base/prefecture == '大阪'"; String returnExpression = "/document/base/name, /document/base/price"; ShunPreparedStatement pstmt = con.prepareSearch(queryExpression, returnExpression); (1) |
ShunPreparedStatementオブジェクトは、prepareSearchメソッドのパラメタに検索式とリターン式を指定して作成します。
検索式およびリターン式の詳細は、“付録B 検索式、リターン式およびソート式の書式”を参照してください。
setRequestメソッドに返信開始番号と返信要求件数を指定します。setRequestメソッドを省略した場合、返信要求件数はconductor用動作環境ファイルまたはdirector用動作環境ファイルのAnsMaxに設定された値が指定されます。
ポイント
返信要求件数には、1画面に表示する件数を指定します。
検索の実行はexecuteSearchメソッドを使用します。検索した結果としてShunResultSetオブジェクトが作成されます。
ポイント
検索条件に一致するXML文書のヒット件数は、getHitCountメソッドで取得できます。この値を使用して、検索した結果のページ数などを求めることができます。
検索した結果を取り出す前には、必ずnextメソッドを使用します。nextメソッドは、次のデータが存在する場合はtrueを返し、それ以上データがない場合はfalseを返します。
XML文書を取り出すには、目的に応じて以下のメソッドを使用します。使用可能なメソッドについては以下の表を参照してください。
メソッド名 | 機能説明 |
|---|---|
getString | XML文書をStringオブジェクトで取り出します。 |
getStringArray | XML文書をStringオブジェクトの2次元配列で取り出します。 |
getStream | XML文書をInputStreamオブジェクトで取り出します。 |
備考.getStringArrayメソッドは、検索した結果をテキスト形式で取り出す場合に有効です。
ポイント
検索した結果とともにデータを一意に識別するレコードIDをgetRecordIDメソッドで取得できます。レコードIDは、対応するXML文書の全体を取り出したり、削除、更新する場合に使用します。
ShunResultSetオブジェクトとShunPreparedStatementオブジェクトは、使用後にそれぞれのcloseメソッドで必ず解放します。
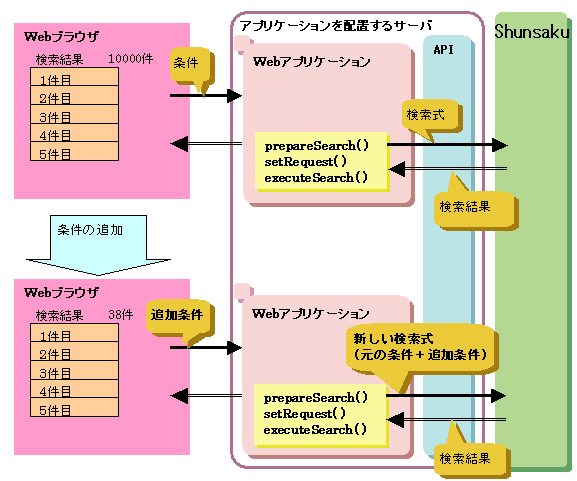
検索した結果の件数が非常に多いとき、さらに条件を追加して件数を絞りたい場合があります。
このような場合、prepareSerachメソッドに指定する検索式に条件を追加して新しい検索式を作成し、再度検索する処理を行います。この操作を繰り返すことで、画面に表示された検索結果を参照しながら検索結果を絞り込むことができます。
条件を追加しながら検索した結果を取得する場合の流れについて、以下の図に示します。
図11.3 条件を追加しながら検索した結果を取得する場合の流れ
記述例
条件を追加しながら検索した結果を取得する場合の記述例については、“11.2.2.2 件数に応じて検索した結果を取得する”を参照してください。
条件を追加する場合には、prepareSearchメソッドに指定する検索式に条件を追加してください。
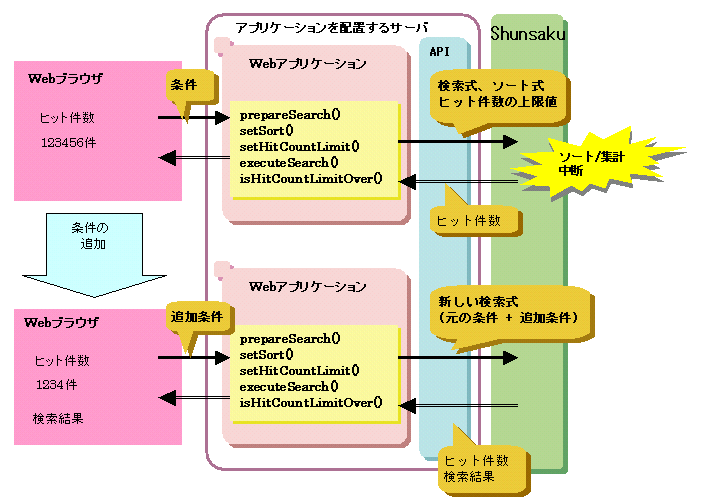
ヒット件数の上限値を設定することで、ソートまたは集計の応答性能を安定させることができます。ヒット件数が上限値を超えた場合には、ソートまたは集計を中断し検索条件に一致したヒット件数を通知します。
ヒット件数が上限値を超えないように検索式に条件を追加し、ソートまたは集計の検索範囲を絞り込みます。
ヒット件数の上限値を設定するには、setHitCountLimitメソッドを使用します。
ヒット件数の上限値を設定する場合の流れについて、以下の図に示します。
図11.4 ヒット件数の上限値を設定する場合の流れ
記述例
ShunConnection con = new ShunConnection(); String queryExpression = "/document/base/prefecture == '大阪'"; String returnExpression = "/document/base/name, /document/base/price"; String sortExpression = "val(/document/base/price/text()) DESC"; ShunPreparedStatement pstmt = con.prepareSearch(queryExpression, returnExpression); pstmt.setSort(sortExpression); /* ヒット件数の上限値を設定 */ pstmt.setHitCountLimit(10000); (1) ShunResultSet rs = pstmt.executeSearch(); /* ヒット件数が上限値を超えているかの確認 */ if (rs.isHitCountLimitOver() ) { (2) System.out.println("ヒット件数が上限値を超えました"); System.out.println("[ヒット件数] = " + rs.getHitCount()); (3) } else { System.out.println("[ヒット件数] = " + rs.getHitCount()); while(rs.next()) { System.out.println("[検索結果] = " + rs.getString()); } } rs.close(); pstmt.close(); con.close(); |
setHitCountLimitメソッドのパラメタにヒット件数の上限値を設定します。
注意
ソート式が設定されていない場合には、executeSearchメソッド実行時にエラーとなります。
isHitCountLimitOverメソッドでヒット件数が上限値を超えているかの確認をします。
ヒット件数が上限値を超えている場合は、ヒット件数のみ取出し可能です。
レコードIDはXML文書全体の取得、データの削除、更新をする場合に使用します。レコードIDの取得はgetRecordIDメソッドを使用します。
レコードIDの取出し方法について、以下の図に示します。
図11.5 レコードIDの取出し方法
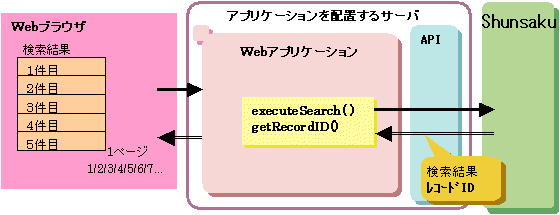
記述例
ShunConnection con = new ShunConnection(); String queryExpression = "/document/base/prefecture == '大阪'"; String returnExpression = "/document/base/name, /document/base/price"; ShunPreparedStatement pstmt = con.prepareSearch(queryExpression, returnExpression); (1) } |
ShunPreparedStatementオブジェクトは、prepareSearchメソッドのパラメタに検索式とリターン式を指定して作成します。
検索式およびリターン式の詳細は、“付録B 検索式、リターン式およびソート式の書式”を参照してください。
setRequestメソッドに返信開始番号と返信要求件数を指定します。setRequestメソッドを省略した場合、返信要求件数はconductor用動作環境ファイルまたはdirector用動作環境ファイルのAnsMaxに設定された値が指定されます。
ポイント
返信要求件数には、1画面に表示する件数を指定します。
検索の実行はexecuteSearchメソッドを使用します。検索した結果としてShunResultSetオブジェクトが作成されます。
検索した結果を取り出すのと同様にレコードIDを取り出す前にも、必ずnextメソッドを使用します。nextメソッドは、次のデータが存在する場合はtrueを返し、それ以上データがない場合はfalseを返します。
ShunResultSetオブジェクトとShunPreparedStatementオブジェクトは、使用後にそれぞれのcloseメソッドで必ず解放します。
XML文書の中から必要なXML文書を検索する場合、はじめからXML文書の全体を取得するのではなく、XML文書を識別するのに有効な部分情報を取得します。利用者は、これらの部分情報から詳細情報を取得したいXML文書を特定します。
XML文書の全体を取り出すには、部分情報を取り出したときに一緒に返却されるレコードIDを使用します。レコードIDを利用することで目的のXML文書の全体を取り出すことができます。
レコードIDを利用してXML文書全体を取得する場合の流れについて、以下の図に示します。
図11.6 レコードIDを利用してXML文書全体を取得する場合の流れ
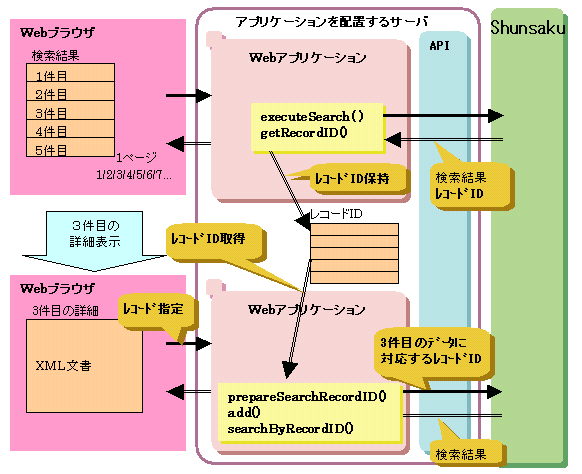
記述例
ShunConnection con = new ShunConnection(); ShunPreparedRecordID prid = con.prepareSearchRecordID(); (1) |
ShunPreparedRecordIDオブジェクトの作成は、prepareSearchRecordIDメソッドを使用します。
レコードIDの設定は、addメソッドを使用します。レコードIDはgetRecordIDメソッドで取得します。
addメソッドで複数のレコードIDを設定できます。すでに同一のレコードIDが設定されている場合は上書きします。
ポイント
addメソッドで複数のレコードIDを指定することで、一度に複数のXML文書を取得することができます。
検索の実行はsearchByRecordIDメソッドを使用します。検索した結果としてShunResultSetオブジェクトが作成されます。
検索した結果を取り出す前には、必ずnextメソッドを使用します。nextメソッドは、次のデータが存在する場合はtrueを返し、それ以上データがない場合はfalseを返します。
XML文書を取り出すには、目的に応じて以下のメソッドを使用します。使用可能なメソッドについては以下の表を参照してください。
メソッド名 | 機能説明 |
|---|---|
getString | XML文書をStringオブジェクトで取り出します。 |
getStream | XML文書をInputStreamオブジェクトで取り出します。 |
ShunResultSetオブジェクトとShunPreparedRecordIDオブジェクトは、使用後にそれぞれのcloseメソッドで必ず解放します。
検索した結果をある特定の要素をキーとしてソートして取得したい場合があります。
データの部分情報をソートして取得するには、setSortメソッドを使用します。
データをソートして取得する場合の流れについて、以下の図に示します。
図11.7 データをソートして取得する場合の流れ
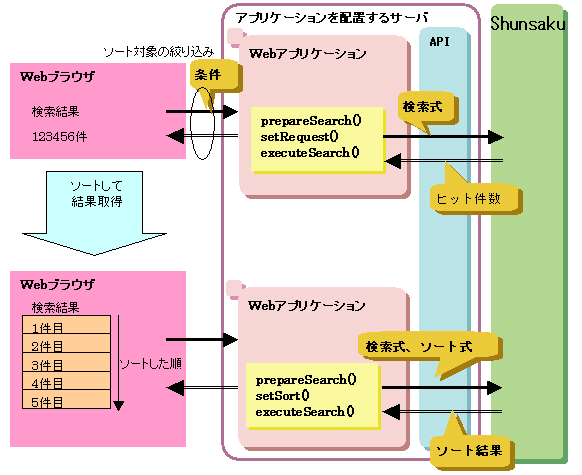
ポイント
ソートを行う場合には、検索条件に一致したすべてのXML文書を参照してソート処理を行います。検索式には、結果件数が適正な値となるような条件を指定し、ソート対象のデータを絞ることが応答性能をよくするポイントです。ソートを実施する前に検索条件に一致したXML文書の件数を調べるには、setRequestメソッドの返信要求件数に0を指定します。
記述例
ShunConnection con = new ShunConnection(); String queryExpression = "/document/base/prefecture == '大阪'"; String returnExpression = "/document/base/name, /document/base/price"; String sortExpression = "val(/document/base/price/text()) DESC"; (1) ShunPreparedStatement pstmt = con.prepareSearch(queryExpression, returnExpression); (2) |
ソート式を作成します。
ソート式の詳細は、“B.5 ソート式”を参照してください。
ShunPreparedStatementオブジェクトの作成は、検索式とリターン式を指定し、prepareSearchメソッドを使用します。
検索式およびリターン式の詳細は、“付録B 検索式、リターン式およびソート式の書式”を参照してください。
ソート式の設定は、setSortメソッドを使用します。
注意
ソート式に指定したキーの長さによって返却できる件数が決まります。最大件数は1000件です。返信開始番号や返信要求件数に返却可能な最大件数を超える値を指定しても、それ以上のデータは返却することができません。返却可能なデータの最大件数は、getReturnableCountメソッドで取得できます。
キーの長さと返却可能なデータ件数の目安については、“付録C 定量値”を参照してください。
参考
取得開始位置を指定することにより、続きのデータを取り出すことができます。これにより1000件以上のデータを取り出すことができます。詳細については、“11.2.2.8 条件に一致するXML文書を連続して取得する”を参照してください。
検索の実行はexecuteSearchメソッドを使用します。検索した結果としてShunResultSetオブジェクトが作成されます。
検索した結果を取り出す前には、必ずnextメソッドを使用します。nextメソッドは、次のデータが存在する場合はtrueを返し、それ以上データがない場合はfalseを返します。
XML文書を取り出すには、目的に応じて以下のメソッドを使用します。使用可能なメソッドについては以下の表を参照してください。
メソッド名 | 機能説明 |
|---|---|
getString | XML文書をStringオブジェクトで取り出します。 |
getStringArray | XML文書をStringオブジェクトの2次元配列で取り出します。 |
getStream | XML文書をInputStreamオブジェクトで取り出します。 |
備考.getStringArrayメソッドは、検索した結果をテキスト形式で取り出す場合に有効です。
ポイント
検索した結果とともにデータを一意に識別するレコードIDをgetRecordIDメソッドで取得できます。レコードIDは、対応するXML文書の全体を取り出したり、削除したりする場合に使用します。
ShunResultSetオブジェクトとShunPreparedStatementオブジェクトは、使用後にそれぞれのcloseメソッドで必ず解放します。
Webアプリケーションでは、検索した結果を一定件数ごとに区切って、前後に連続したデータを取得したい場合があります。
このような場合、setRequestメソッドのパラメタである取得開始位置、または、取得終了位置に、その直前の検索処理によって取得した最終位置情報、または、先頭位置情報を指定してXML文書を連続して取得します。
条件に一致するXML文書を連続して取得する場合の流れについて、以下の図に示します。
図11.8 条件に一致するXML文書を連続して取得する場合の流れ
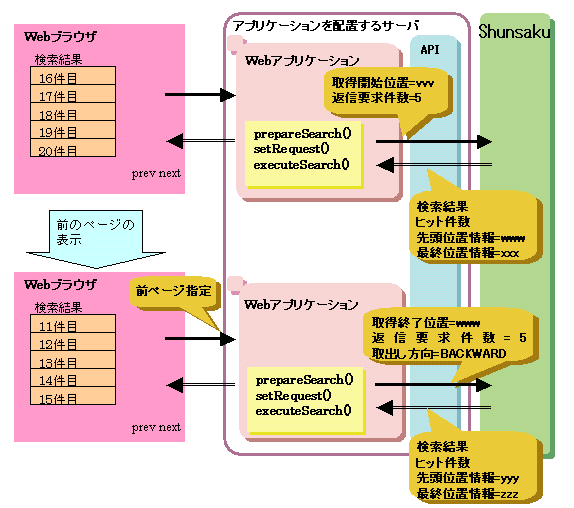
記述例
String queryExpression = "/document/base/prefecture == '大阪'";
String returnExpression = "/document/base/name, /document/base/price";
String sortExpression = "val(/document/base/price/text()) DESC";
ShunConnection con = new ShunConnection();
ShunPreparedStatement pstmt = con.prepareSearch(queryExpression, returnExpression);
pstmt.setSort(sortExpression);
//取出し方向
int direction = 0;
// 先頭位置情報
String sFirstPos = null;
// 最終位置情報
String sLastPos = null;
// どのページを表示するかによってsetRequestの設定を変更
// 次のページを表示する場合は directionがNEXT、前のページを表示する場合は directionがPREVとする
if(direction == NEXT) {
// 次のページを表示する場合 (2) |
setRequestメソッドにデータの取得位置と返信要求件数を指定します。 最初のページを表示する検索処理では、最初のデータから取出しを行うため、データの取得位置(取得開始位置または取得終了位置)にはnullを指定します。取得位置にnullを指定すると、1件目からデータを取り出します。
setRequestメソッドにデータの取得位置、返信要求件数および取出し方向を指定します。 次のページを表示する検索処理では、前回検索時の最終位置情報をgetLastPositionメソッドで取得しておき、データの取得位置(取得開始位置)に指定します。この指定により前回取得したデータの続きのデータを取得します。
setRequestメソッドにデータの取得位置、返信要求件数および取出し方向を指定します。 前のページを表示する検索処理では、前回検索時の先頭位置情報をgetFirstPositionメソッドで取得しておき、データの取得位置(取得終了位置)に指定します。この指定により前回取得したデータの前の部分のデータを取得します。
executeSearchメソッドで検索を実行します。検索した結果としてShunResultSetオブジェクトが作成されます。
検索した結果を取り出す前には、必ずnextメソッドを使用します。nextメソッドは、次のデータが存在する場合はtrueを返し、それ以上データがない場合はfalseを返します。
XML文書を取り出すために、getStringメソッドを使用します。
getFirstPositionメソッドを使用して先頭位置情報を格納します。
getLastPositionメソッドを使用して最終位置情報を格納します。
ShunResultSetオブジェクトとShunPreparedStatementオブジェクトは、使用後にそれぞれのcloseメソッドで必ず解放します。
検索した結果をある特定の要素の値で集計して取得したい場合があります。
データの内容を集計するには、setSortメソッドを使用します。prepareSearchメソッドのパラメタであるリターン式に集合関数指定を指定すると、検索した結果が集計されて返却されます。集計処理では、合計値、平均値、最大値、最小値または件数を求めることができます。
条件に一致するデータの内容を集計する場合の流れについて、以下の図に示します。
図11.9 条件に一致するデータの内容を集計する場合の流れ
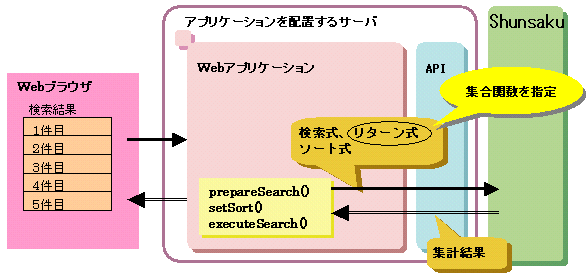
記述例
ShunConnection con = new ShunConnection(); String queryExpression = "/document/base/prefecture == '大阪'"; String returnExpression = "max(/document/base/price/text())"; (1) |
リターン式を作成します。集計を行う場合は、リターン式に集合関数指定を指定します。
リターン式および集合関数指定の詳細については、“B.4 リターン式”を参照してください。
ソート式を作成します。
ソート式の詳細については、“B.5 ソート式”を参照してください。
ShunPreparedStatementオブジェクトの作成は、検索式とリターン式を指定し、prepareSearchメソッドを使用します。
検索式およびリターン式の詳細は、“付録B 検索式、リターン式およびソート式の書式”を参照してください。
ソート式の設定は、setSortメソッドを使用します。
注意
ソート式に指定したキーの長さによって返却できるグループの数が決まります。最大グループ数は1000グループです。返信開始番号や返信要求件数に返却可能な最大グループ数を超える値を指定しても、それ以上のデータは返却することができません。返却可能なデータの最大件数は、getReturnableCountメソッドで取得できます。
キーの長さと返却可能なグループ数の目安については、“付録C 定量値”を参照してください。
参考
取得開始位置を指定することにより、続きのデータを取り出すことができます。これにより1000グループ以上のデータを取り出すことができます。詳細については、“11.2.2.8 条件に一致するXML文書を連続して取得する”を参照してください。
検索の実行はexecuteSearchメソッドを使用します。検索した結果としてShunResultSetオブジェクトが作成されます。
検索した結果を取り出す前には、必ずnextメソッドを使用します。nextメソッドは、次のデータが存在する場合はtrueを返し、それ以上データがない場合はfalseを返します。
XML文書を取り出すには、目的に応じて以下のメソッドを使用します。使用可能なメソッドについては以下の表を参照してください。
メソッド名 | 機能説明 |
|---|---|
getString | XML文書をStringオブジェクトで取り出します。 |
getStringArray | XML文書をStringオブジェクトの2次元配列で取り出します。 |
getStream | XML文書をInputStreamオブジェクトで取り出します。 |
ShunResultSetオブジェクトとShunPreparedStatementオブジェクトは、使用後にそれぞれのcloseメソッドで必ず解放します。