shunselectコマンドの動作環境を記述します。
以下に、select用動作環境ファイルの実行パラメタを示します。
注意
select用動作環境ファイルの内容は、システムロケールの文字コードで記述してください。
パラメタ名は行の先頭から記述してください。
パラメタ名 | 省略 | 説明 |
|---|---|---|
可 | 検索対象となる文字列の文字コードを指定します。 | |
可 | 入力ファイルタイプを指定します。 | |
可 | 入力ファイルの見出し行の扱いを指定します。 | |
可 | パターンの文字列検索を行う場合に検索対象外として取り扱う文字列(スキップキャラクタ)を指定します。 | |
可 | パターンのワード検索を行う場合のワード区切り文字(セパレートキャラクタ)を指定します。 | |
可 | 検索対象文字列の半角英字について大文字・小文字の取扱いを指定します。 | |
可 | 検索対象文字列の全角英字について大文字・小文字の取扱いを指定します。 | |
LogFile | 可 | ログファイルを指定します。(注) |
可 | 複数の入力ファイルを同時に処理するための並列数を指定します。 | |
可 | 出力データの中の文字列値を、二重引用符(")で括るかどうかを指定します。 | |
可 | 入力ファイルタイプがCSVの場合、項目間の区切り文字を二重引用符(")で囲んで指定します。 | |
可 | 入力ファイルタイプがCSVの場合、2つ以上の連続した区切り文字の扱いを指定します。 | |
可 | 入力ファイル中にエラーデータを検出したときの、エラーデータ出力ファイルを指定します。(注) | |
OutLineFeedCode | 可 | 出力データにおける、レコード終端の改行コードの取り扱いを指定します。 LF : Lf(0x0A) CRLF : Cr(0x0D)Lf(0x0A) 本パラメタを省略した場合、Windows では“CRLF”、 Linux/Solaris では “LF”が指定されたとみなします。 |
注) ファイル名に特殊な文字を指定した場合の扱いについては、 “パス名に指定する特殊な文字の扱い”を参照してください。
入力ファイルタイプがCSVの場合、入力ファイルの見出し行の扱いを指定します。
0: 見出し行を読み飛ばさない。
1: 見出し行を読み飛ばす。
本パラメタを省略した場合、0が指定されたものとみなします。
注意
本パラメタは、入力ファイルタイプがCSVの場合だけ有効です。
本パラメタは、入力定義ファイルにスキーマ情報ファイルが指定されている場合だけ有効です。指定されていない場合、先頭行は読み飛ばしません。
本パラメタは、すべての入力ファイルに対して有効になります。そのため、見出し行のある入力ファイルと、見出し行のない入力ファイルが混在している場合には使用できません。見出し行のない入力ファイルを指定した場合、先頭行を見出し行とみなして読み飛ばします。
パターン検索(文字列)を行う場合は、検索対象外として取り扱う文字列(スキップキャラクタ)を二重引用符(")で囲んで指定します。
SkipCharには、制御文字を除く文字、改行および水平タブを指定します。
本パラメタを省略した場合、または空文字("")を指定した場合は、すべての文字が検索対象となります。
SkipCharに指定する文字は複数指定可能です。複数指定する場合は、個々の文字列をカンマ(,)で区切って指定します。
注意
本パラメタは、パターン検索(文字列)および文字列検索の完全一致で有効です。項目間比較では、無効となります。
下記の文字以外をSkipCharに指定する場合は、CharacterCodeで定義した文字コードでSkipCharを表現してください。なお、大文字と小文字は区別されます。
文字 | 指定方法 |
|---|---|
半角空白 | \s |
全角空白 | \S |
改行 | \n |
水平タブ | \t |
以下の文字をSkipCharに指定する場合の例を示します。
指定する文字:半角空白、全角空白、水平タブ、@(半角文字)、@(全角文字)および改行
CharacterCodeで定義した文字コード | UTF-8 | SHIFT-JIS | EUC |
|---|---|---|---|
半角空白 | \s | \s | \s |
全角空白 | \S | \S | \S |
水平タブ | \t | \t | \t |
@(全角文字) | \EF \BC \A0 | \81 \97 | \A1 \F7 |
@(半角文字) | \40 | \40 | \40 |
改行 | \n | \n | \n |
記述例は以下のようになります。
CharacterCodeで定義した | 記述例 |
|---|---|
UTF-8 | \s,\S,\t,\EF \BC \A0,\40,\n |
SHIFT-JIS | \s,\S,\t,\81 \97,\40,\n |
EUC | \s,\S,\t,\A1 \F7,\40,\n |
注意
入力ファイルタイプ(InFileType)の指定によってSkipCharに以下の文字は指定できません。
入力ファイルタイプ | SkipCharに |
|---|---|
CSVの場合 | " |
,(注) | |
\n | |
XMLの場合 | < |
> | |
] | |
" | |
' |
注)FieldSeparatorパラメタに指定した区切り文字に対応します。
例えば、FieldSeparatorパラメタに、カンマ(,)と水平タブを指定した場合、SkipCharパラメタにカンマ(,)と水平タブは指定できません。
検索式にパターン検索(ワード)を指定する場合に、区切り文字全体を二重引用符(")で囲んで指定します。
SeparateCharに指定する文字は複数指定可能です。複数指定する場合は、個々の文字列をカンマ(,)で区切って指定します。
SeparateCharには、制御文字以外のASCII文字、改行および水平タブを指定します。
注意
下記の文字をSeparateCharに指定する場合は、エスケープ文字を付加してSeparateCharを表現してください。エスケープ文字は“\”です。
区切り文字 | 指定方法 |
|---|---|
半角空白 | \s |
改行 | \n |
水平タブ | \t |
カンマ | \, |
二重引用符 | \" |
\マーク | \\ |
本パラメタを省略した場合、または""と記述し区切り文字を1つも指定しなかった場合は、入力ファイルタイプ(InFileType)によって以下の“区切り文字”が指定されたとみなします。
CSVの場合
\t(注) |
| \s(注) |
| ! | $ |
% | & | ' | ( | ) | * |
+ | \,(注) | - | . | / | : |
; | < | = | > | ? | @ |
[ | \\ | ] | ^ | _ | ` |
{ | | | } | ~ |
|
|
注) FildSeparatorに指定された区切り文字は除外されます。
XMLの場合
\t | \n | \s | \" | ! | $ |
% | & | ' | ( | ) | * |
+ | \, | - | . | / | : |
; |
| = |
| ? | @ |
[ | \\ |
| ^ | _ | ` |
{ | | | } | ~ |
|
|
注意
入力ファイルタイプ(InFileType)の指定によってSeparateCharに以下の文字は指定できません。
入力ファイルタイプ | SeparateCharに |
|---|---|
CSVの場合 | " |
,(注) | |
\n | |
XMLの場合 | < |
> | |
] |
注)FieldSeparatorパラメタに指定した区切り文字に対応します。
例えば、FieldSeparatorパラメタに、カンマ(,)と水平タブを指定した場合、SeparateCharパラメタにカンマ(,)と水平タブは指定できません。
検索対象文字列の半角英字について大文字・小文字の取扱いを指定します。
0:区別する
1:区別しない
本パラメタを省略した場合、0が指定されたとみなします。
検索キーワード | 検索対象文字 | 0:区別する | 1:区別しない |
|---|---|---|---|
ab | ab | ○ | ○ |
AB | × | ○ | |
aB | × | ○ | |
Ab | × | ○ | |
AB | ab | × | ○ |
AB | ○ | ○ | |
aB | × | ○ | |
Ab | × | ○ |
○:ヒットする
×:ヒットしない
注意
本パラメタは、条件式の項目間比較では無効です。
検索対象文字列の全角英字について大文字・小文字の取扱いを指定します。
0:区別する
1:区別しない
本パラメタを省略した場合、0が指定されたとみなします。
検索キーワード | 検索対象文字 | 0:区別する | 1:区別しない |
|---|---|---|---|
ab | ab | ○ | ○ |
AB | × | ○ | |
aB | × | ○ | |
Ab | × | ○ | |
AB | ab | × | ○ |
AB | ○ | ○ | |
aB | × | ○ | |
Ab | × | ○ |
○:ヒットする
×:ヒットしない
注意
本パラメタは、条件式の項目間比較では無効です。
入力ファイルを2つ以上指定した場合、複数の入力ファイルから同時に抽出を行う並列数を指定します。
ParallelNumパラメタに指定できる値は、1から128までです。
ParallelNumパラメタで指定した並列数が入力ファイルの数よりも小さい場合、並列数以上の入力ファイルは、並列数以内の入力ファイルの抽出が終わった後に順次、実行されます。
ParallelNumパラメタで指定した並列数が入力ファイルの数よりも大きい場合、入力ファイルの数が同時に抽出を行う並列数となります。
注意
ParallelNumパラメタに2以上を指定した場合、入力定義ファイルのDataFileパラメタに指定した順に並列に抽出します。そのため、出力定義ファイルに指定した出力ファイルには、複数の入力ファイルからの抽出結果が混在して出力されます。
並列処理時の出力ファイルイメージを以下に示します。
図1.1 並列処理時の出力ファイルイメージ
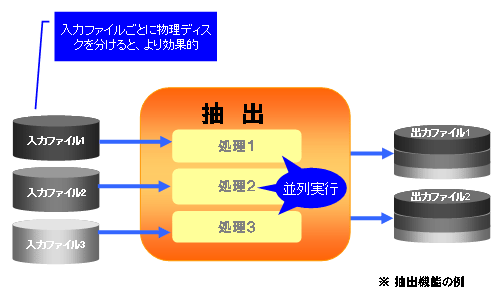
ParallelNumパラメタに2以上を指定した場合、入力ファイルは複数の物理ディスクに分散して配置することで、読込み処理のディスクI/Oの負荷を分散でき、並列効果を最大限に発揮できます。
そのため、ParallelNumパラメタに指定した並列数と、入力ファイルを配置する物理ディスクの数を同じにすることを推奨します。
出力ファイルタイプがCSVの場合、出力データの中の文字列値を二重引用符(")で括るかどうかを指定します。
0: 出力データの中の文字列値を、二重引用符(")で括る。
1: 出力データの中の文字列値を、二重引用符(")で括らない。
検索定義ファイルにリターン式を指定した場合だけ、本パラメタが有効になります。
リターン式を指定しない場合は、入力データをそのまま出力します。
組合せを以下に示します。
検索定義ファイルの | 本パラメタの指定 | 二重引用符(") |
|---|---|---|
指定あり | 0 | 二重引用符(")で括る |
1 | 二重引用符(")で括らない | |
指定なし | 無効 | 入力ファイルと同じ形式 |
本パラメタを省略した場合、0が指定されたものとみなします。
注意
本パラメタに“1”を設定した場合、結果データの文字列値にセパレータ文字や改行が存在しても、二重引用符は設定されません。そのため、その後の処理において、想定したデータとして扱われない場合があります。
処理対象のデータに、セパレータ文字や改行が存在する場合には、“0”を指定することを推奨します。以下に例を示します。

本パラメタに“1”を設定した場合、結果データの項目に二重引用符(")が存在しても二重引用符(")によるエスケープは設定されません。
本パラメタに“1”を設定した場合、入力ファイルのデータの項目に二重引用符(")が設定されていたときでも、結果データの項目には、二重引用符(")は付加されなくなります。
入力ファイルの区切り文字が半角空白や水平タブの場合、リターン式を指定すると結果データはカンマ区切りで出力されます。このため、入力ファイルのデータにカンマなどが存在している場合に、本パラメタに“1”を指定すると、結果データが想定したデータとして扱われない場合があります。
入力ファイルタイプがCSVの場合、項目間の区切り文字を変更する場合は、新しく区切り文字とする文字を二重引用符(")で囲んで指定します。区切り文字として使用できる文字は、以下のとおりです。
区切り文字 | 指定方法 |
|---|---|
カンマ | \, |
半角空白 | \s |
水平タブ | \t |
区切り文字として複数指定する場合は、個々の文字列をカンマ(,)で区切って指定します。
注意
本パラメタを指定した場合の出力時の区切り文字は、検索定義ファイルにおけるリターン式の指定によって、以下のように異なります。
リターン式 | 出力時の区切り文字 |
|---|---|
指定あり | カンマ |
指定なし | 入力ファイルと同じ形式 |
入力ファイルタイプがCSVの場合、2つ以上の連続した区切り文字の扱いを指定します。
0:1つの区切り文字を1つの項目間の区切りとして扱う。
1:2つ以上の連続した区切り文字を1つの項目間の区切りとして扱う。
本パラメタを省略した場合、0が指定されたものとみなします。
入力ファイルタイプがCSVの場合、エラーデータ出力ファイルと、エラーデータの最大出力件数を指定します。
本パラメタを指定すると、エラーデータを検索対象外のデータとして扱い、処理を継続します。
本パラメタを省略した場合、エラーデータを検出した時点でコマンドが異常終了します。
図1.2 エラーデータ出力の定義
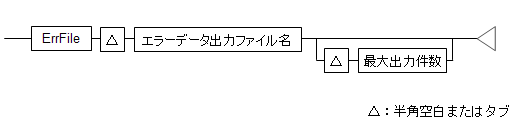
入力ファイル中にエラーデータを検出したとき、そのエラーデータの情報を出力します。
指定したファイルがすでに存在している場合は、その情報が上書きされます。
入力ファイル中にエラーデータが存在しなかった場合、エラーデータ出力ファイルは作成されません。
エラーデータの最大出力件数に指定できる値は、1から2147483647までです。
エラーデータの最大出力件数を指定すると、エラーデータが指定件数分、出力された時点でコマンドが異常終了します。
本パラメタを省略した場合、1000が指定されたものとみなします。
ポイント
エラーデータ出力ファイルには、文字コードが異なる入力ファイル名と、エラーとなったレコードが混在して出力されます。入力ファイル名に半角英数字を入れるなど工夫すると便利です。
詳細については、“1.2.2 入力定義ファイル”のDataFileパラメタを参照してください。
参照
エラーデータ出力ファイルの出力例は、“導入・運用ガイド”の“入力ファイルのエラー処理”を参照してください。