Navigatorからデータベースのセットアップをする際には、以下のデータベースの構造を考慮します。
基本形式
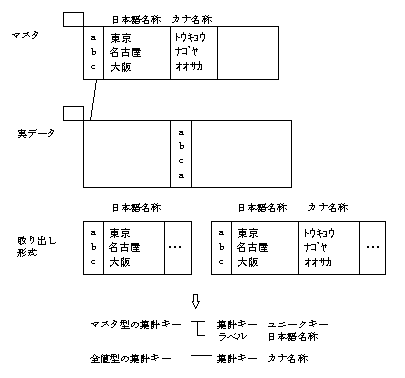
マスタテーブルと実データテーブルの結合
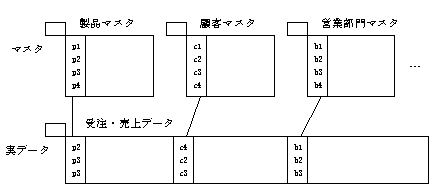
マスタテーブルとマスタテーブルの結合
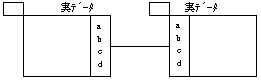
実データテーブルと実データテーブルの結合
拡張形式
重複結合
実データから1つのマスタに重複した参照ができます。
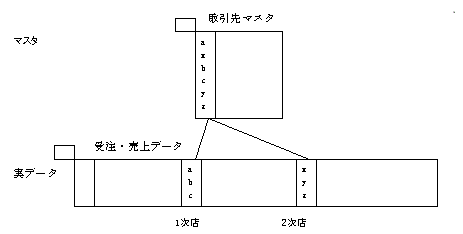
基本形式
マスタテーブルと実データテーブルの結合
実データテーブルとマスタテーブルの結合を規定するキーとして、マスタテーブル側にプライマリキー、実データテーブル側にコードがあります。
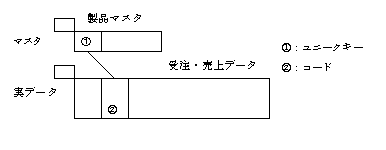
マスタテーブルとマスタテーブルの結合
マスタテーブルとマスタテーブルの結合を規定するキーとして、マスタテーブルにプライマリキー、他方のマスタテーブルにコードがあります。
実データテーブルと実データテーブルの結合
実データテーブルと実データテーブルの結合を規定するキーとして、実データテーブルにユニークキー、他方の実データテーブルもユニークキーがあります。
拡張形式
複数項目の結合(複合コードによる結合)
複数項目の結合ができます。
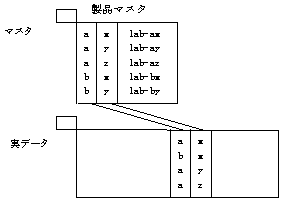
結合キーの制約
以下のデータ項目は結合キーとして使用できません。
80文字(日本語の場合は40文字)を超える文字列型データ
なお、可変長形式の場合は最大文字数がそれに対応します。
小数部のある数値型データ
浮動小数点型数値データ
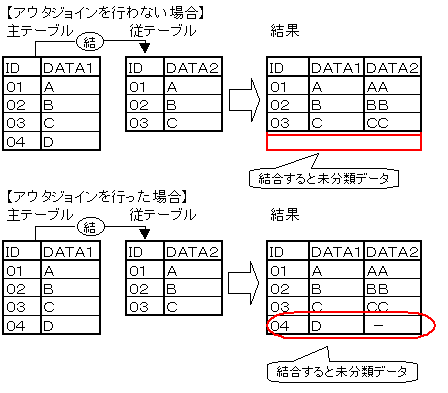
未分類データの表示
未分類を表示する集計を行う場合、データベースシステムによるテーブル結合が行われる問い合わせでは、対応する結合キーのないデータは、集計の対象となりません。
DBMSのアウタジョインの機能を利用することで、対応する結合キーのない主テーブル側のデータ(以下の例では、主テーブルのID項目の「04」が該当します)も集計対象とすることができるようになります。
アウタジョインを利用した問い合わせは、データベースがPostgres、Symfoware/RDB、Oracle、SQL Server、およびSAP IQの場合に利用できます。
DBMSのアウタジョインは、通常のジョインに比べて処理に時間がかかる場合があります。そのため、システム管理者はアウタジョインを使用するよりも、データベースのメンテナンスをして未分類データが発生しないようにしてください。アウタジョインを使用する場合には、事前に性能検証をしてください。
実データテーブルとマスタテーブルの結合を規定するキーとして、マスタテーブル側にプライマリキー、実データテーブル側にコードがあります。
マスタテーブルとマスタテーブルの結合を規定するキーとして、マスタテーブルにプライマリキー、他方のマスタテーブルにコードがあります。
実データテーブルと実データテーブルの結合を規定するキーとして、実データテーブルにユニークキー、他方の実データテーブルもユニークキーがあります。
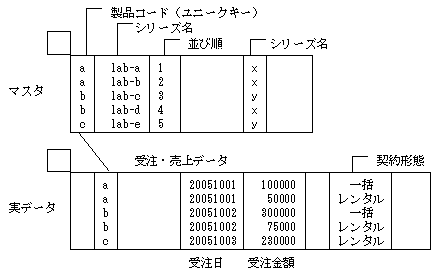
管理ポイントごとの集計キーの形式
各管理ポイントの集計キーの形式を説明します。管理ポイントについては、“Navigator Server概説書”を参照してください。
マスタのプライマリキーを集計キーにする方式です。テーブルの結合関係の定義から、自動的にNavigatorが設定します。この方式は、コード、ラベルと並べ順を規定するキーが一体で管理されます。
マスタ、または実データテーブルのデータ項目のユニークな値を、問い合わせ時に取り出して、それを集計キーにする方式です。集計結果を見やすくするためには、集計キーをカテゴリ型に再編集して、ラベルを付加したり、並べ順を変更したりする必要があります。
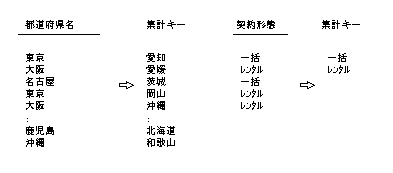
初期設定の並べ順は、文字型のデータの場合、文字コードの順序(昇順)となります。また、数値型データの場合、数値の大きさの順序(昇順)となります。なお、データにNULL値がある場合は、対象から除外されます。不都合がある場合は、NULL値をデータベースで代替値に置き換えてください。
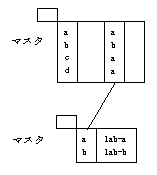
マスタ型、または全値型の集計キーを再編集して、新しいくくりを設定する方式です。
小区分(マスタ、または全値型)を編集して中区分を定義し、さらに中区分を編集して大区分を定義するなど、階層関係を持つ集計キーを作成することができます。
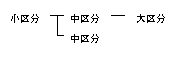
カテゴリ型の集計機能を応用すると、データのクリーニングが可能となります。性別を示すデータのクリーニングの例を、以下に示します。
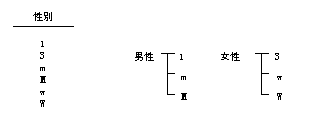
データ項目の値にNULLがあった場合、NULLは未区分として集計されます。未区分を表示しないモードで集計すると、NULL値のデータは無視されます。不都合がある場合は、NULL値をデータベースで代替値に置き換えてください。
なお、NULL値は、カテゴリを構成する内訳に含めることはできません。
SNに時間を示すデータ項目を集計キーとして宣言することにより、自動的にキーを設定する方式です。例えば、受注日(yyyymmdd)を集計キーに設定することにより、受注金額などの取り出したい形式(日単位、月単位、四半期単位、半期単位、年度単位)を、取り出し時点で、自由に要求することが可能です。
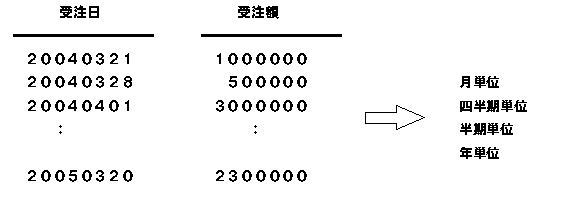
受注額、売上高などの計数データを範囲で集計する方式です。

制約とその回避方法
マスタ型の集計キーに対応した複数のラベルを使い分けることはできません。使用頻度の少ないラベルを全値型の集計キーとして定義して、情報活用で2つの集計キーを使い分けてください。
固定長形式の文字データは、頭詰めで入力されていること、また項目の属性として設定された文字数に満たない場合は、不足する位置に空白が保証されていることを前提としています。
![]()
は別の値として評価されます。
可変長の文字データは、頭詰めで入力されていることを前提としています。
末尾から連続する空白の評価は、使用しているデータベースの種類によって異なります。ただし、管理ポイントの作成元項目として使用すると、管理ポイントが正しく作成されないことがあります。末尾の空白がなくなるようにデータを更新してください。
![]()
は別の値として評価されます。
![]()
はデータベースの種類によって異なります。
Symfoware/RDB、またはSQL Serverの場合は、同一の値として評価されます。
Postgres、Oracleの場合は、別の値として評価されます。
不都合がある場合は、データを更新するかカテゴリ型の集計を適用して、クリーニングを実施してください。
80文字(日本語型の場合は40文字)を超える文字項目は、集計キーとして利用することができません。なお、可変長の場合は、最大文字数がそれに対応します。
結合キー項目に指定した項目が空白のみのデータを持つ場合、正しく集計されないことがあります。空白のみのデータを持つ項目を結合キー項目にする場合は、空白データを別のデータに置き換えてください。
サーバのキャラクタコードセットがEUCの場合、文字列型データに半角カナが混在するデータは、マスク指示したグループ化ができません。
富士通![]() : 全桁を対象とした集計キーの定義が可能
: 全桁を対象とした集計キーの定義が可能
富士通システム : 全桁を対象とした集計キーと、マスク指示したグループ化による集計キーの定義が可能
浮動小数点形式、および小数部を持つ固定小数点形式の数値データを、全値型の集計キーとして利用することはできません。精度によって、処理結果に揺れが生じることがあるためです。整数、または小数部のない固定小数点形式のデータに変換してください。
年の表現は、西暦の4桁を前提としています。2桁の表現の場合は、4桁に変更してください。また、年、月、日が分離されている場合は、結合して1つのデータ項目としてください。
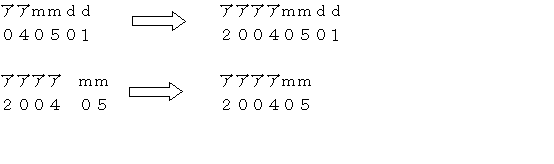
時間の表現は、CHARACTER型、DATE型とTIMESTAMP型のいずれでも動作を保証します。
性能面を考慮するとCHARACTER型が有利です。DATE型、またはTIMESTAMP型のデータ項目を結合キーにすると、性能が極端に悪化することがあります。
時間を表現するデータ項目は、以下のどれかの形式である必要があります。
| 対応する形式 | |
|---|---|---|
TIMESTAMP型 | yyyy-mm-dd hh:mm:ss | |
DATE型 | yyyy-mm-dd | |
DATE型 | OracleのDATE型は、環境変数RN_ORACLE_DATETYPEで、データの形式を指定します。
| |
datetime型 | yyyy-mm-dd hh:mm:ss | |
smalldatetime型 | yyyy-mm-dd hh:mm:ss | |
SQL_DATE型 | yyyy-mm-dd | |
SQL_TIMESTAMP型 | yyyy-mm-dd hh:mm:ss | |
date型 | yyyy-mm-dd | |
timestamp without time zone型 | yyyy-mm-dd hh:mm:ss | |
CHARACTER型 | 年月の表現 | yyyymm |
年月日の表現 | yyyymmdd | |
年月日時分秒の表現 | yyyymmddhhmmss | |