DBサービス定義は、複写元システムで抽出したデータを、複写先システムの表にどのように格納するかを定義するものです。
DBサービス定義はLinkexpressのDB連携機能の1機能です。以下の手順で実施します。詳細は、“Linkexpress 運用ガイド”を参照してください。
定義内容を記述したDBサービス定義ファイルを作成します。
また、Linkexpressクライアントの“業務定義ウィンドウ”で自側DB格納イベントまたは相手側DB格納イベントとしてGUIで定義することもできます。詳細は、“Linkexpress 運用ガイド”を参照してください。なお、グループ単位のレプリケーションの場合は、GUIによる定義を行うことはできません。
DBサービス定義は以下の4つの定義文により構成されています。
INTABLE定義文:入力データの定義を行う定義文です。
OUTTABLE定義文:出力データの定義を行う定義文です。
EXTRACT定義文:データの編集に関する指定を行う定義文です。
REPLICAGROUP定義文:レプリケーショングループを定義する定義文です。グループ単位のレプリケーションの場合にだけ必要です。
ここでは、Linkexpress Replication optionを使用する場合に、DBサービス定義の各定義文で注意する点について、以下の場合に分けて説明します。
表単位のレプリケーションでのDBサービス定義
グループ単位のレプリケーションでのDBサービス定義
なお、DBサービス定義ファイルのサンプルについては、“付録C サンプルファイル一覧”を参照してください。また、定義ファイル作成コマンド(lxrepmkdefコマンド)により、DBサービス定義ファイルの雛型を作成することができます。詳細は、“コマンドリファレンス”の“lxrepmkdefコマンド”を参照してください。
表単位のレプリケーションでは、以下の定義文が必要です。
INTABLE定義文
OUTTABLE定義文
EXTRACT定義文
表単位のレプリケーションでのDBサービス定義の方法を、以下の運用例に基づいて説明します。
なお、ここで説明するもの以外にもDBサービス定義の定義項目は存在します。詳細については、“コマンドリファレンス”の“lxgensvコマンド” および“Linkexpress 運用ガイド”を参照してください。
運用資源
運用資源 | 複写元システム | 複写先システム |
|---|---|---|
OS | Linux | Linux |
コード系 | UNICODE系 | UNICODE系 |
データベース名 | 社員管理データベース | 社員管理データベース |
スキーマ名 | 社員スキーマ | 社員スキーマ |
表名 | 社員表 | 社員表 |
列名およびデータ型 | 社員番号:SMALLINT | 社員番号:SMALLINT |
抽出データの形式 | UTF-8コード系 | - |
運用形態
社員管理データベースの仙台支店の社員データを社員管理データベースに複写します。
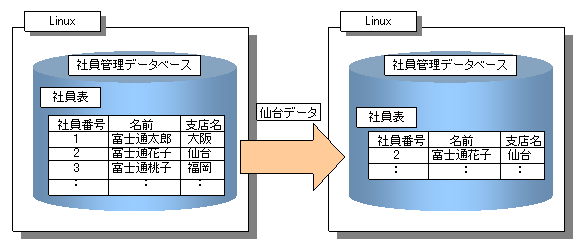
レプリケーション運用例でのINTABLE定義文の記述例を以下に示します。
内容および形式の詳細については、“Linkexpress 運用ガイド”を参照してください。
INTABLE
NAME = INEMPLY → 1
DATATYPE = (local,non-attribute add null field) → 2
CODE = unicode → 3
UNICODE_TYPE = utf8-4 → 3
BYTEORDER =littele → 4
ITEM = ((@DBOP,sint except null field),
(ITEM1,sint),
(ITEM2,vchar(40)),
(ITEM3,vchar(20))) → 5
FILE = /home/work/indata → 6以下にINTABLE定義文のオペランドの指定時に注意すべき点を説明します。各オペランドの番号は、記述例の番号と対応します。
INTABLE識別名を指定してください。
入力データの種別には、“local”を指定してください。
入力データの形式には、複写元システムの抽出定義で指定したNULLINDオペランドの値に従って指定してください。
複写元システムで抽出したコード系を指定します。抽出定義のOUTCODEオペランドの値に従って指定してください。
注意
CODEオペランドにunicodeを指定した場合には、UNICODE_TYPEオペランドの指定が必要です。
BYTEORDERオペランド(入力データの数値の表現形式)
入力データに含まれる数値の表現形式を指定します。
抽出される差分データの形式に従ってください。
以下に複写元システムで抽出される差分データのレコード形式とITEMオペランドでの指定形式について説明します。
抽出レコード形式
レコードの形式にはナル表示域あり(抽出定義でNULLIND=YESを指定)と、ナル表示域なし(抽出定義でNULLIND=NOを指定)の2種類があります。
レコードの構成を以下に示します(コード系をUTF-8、数値の表現形式を後退法で示します。)。
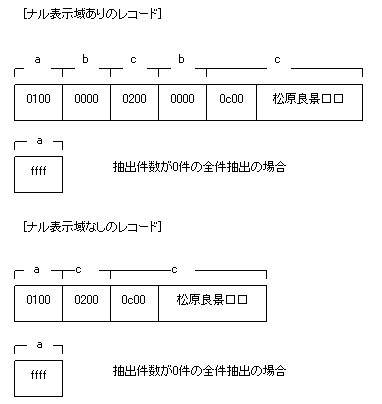
差分反映操作(長さ:2バイト、属性:SMALLINT)
0x0000:全件抽出
0x0001:追加差分
0x0002:更新差分
0x0003:削除差分
0xffff:抽出件数が0件の全件抽出
ナル表示域 (長さ:2バイト、属性:SMALLINT)
0x0000:ナル値でない
0xffff:ナル値
ナル表示域なしのレコードの場合および抽出件数が0件の全件抽出の場合、本フィールドは存在しません。
データ項目 (長さ:データ型によって異なります)
各項目のデータが抽出されます。
詳細は、“システム設計ガイド”の“抽出データ項目の形式”を参照してください。
抽出件数が0件の全件抽出の場合、本フィールドは存在しません。
ITEMオペランドでの指定形式
差分反映操作
“@DBOP,sint except null field”と指定してください。
DATATYPEオペランドの入力データの形式でナル表示域の有無に“except null field”を指定した場合、“@DBOP,sint”だけの指定も可能です。
各データ項目の属性
“システム設計ガイド”の“抽出データ項目の形式”を参照してください。
各データ項目のナル表示域の有無
DATATYPEオペランドで入力データの形式を指定した場合はナル表示域の有無をITEMオペランドで指定する必要はありません。
DATATYPEオペランドの入力データの形式を指定していない場合は、以下のように指定します。
ナル表示域ありのレコードの場合:add null field
ナル表示域なしのレコードの場合:except null field
格納処理の入力ファイル名(受信ファイル名)を指定してください。
レプリケーション運用例でのOUTTABLE定義文の記述例を以下に示します。
内容および形式の詳細については、“Linkexpress 運用ガイド”を参照してください。
OUTTABLE
NAME = OUTEMPLY → 1
DATATYPE = (database,enterprise/pgs) → 2
EXTRACT = EXTEMPLY → 3
CODE = unicode → 4
UNICODE_TYPE = utf8-4 → 4
DATABASE = 社員管理データベース → 5
SCHEMA = 社員スキーマ → 6
TABLE = 社員表 → 7
ITEM = (@DBOP,社員番号,名前,支店名) → 8
LOADMODE = (difference,load) → 9以下にOUTTABLE定義文のオペランドの指定時に注意すべき点を説明します。各オペランドの番号は、記述例の番号と対応します。
OUTTABLE識別名を指定してください。
DATATYPEオペランド(出力データの出力先およびデータベース・システムの種類)
データの出力先には、“database”を指定してください。
データベース・システムの種類は、複写先データベースに合わせ、以下のいずれかを指定してください。
Symfoware Server (Openインタフェース):symfoware/pgs
Symfoware Server (Postgres):enterprise/pgs
Enterprise Postgres:enterprise/pgs
EXTRACT識別名を指定してください。
複写先データベースに格納するデータのコード系を指定してください。
注意
CODEオペランドにunicodeを指定した場合には、UNICODE_TYPEオペランドの指定が必要です。
複写先データベースのデータベース名を指定してください。
複写先データベースの格納先のスキーマ名を指定してください。
複写先データベースの格納先の表名を指定してください。
格納先の表の列名を指定してください。
INTABLE定義文のITEMオペランドの入力データ項目名が複写先データベースの表の列名と同じ場合は、本オペランドを省略することができます。
格納方式には、全複写、一括差分複写を問わず、“difference”を指定してください。
格納方法には、“load”を指定してください。
複写元システムがグローバルサーバまたはPRIMEFORCEの場合は、“コマンドリファレンス”の“OUTTABLE定義文”を参照してください。
レプリケーション運用例でのEXTRACT定義文の記述例を以下に示します。
内容および形式の詳細については、“Linkexpress 運用ガイド”を参照してください。
EXTRACT
NAME = EXTEMPLY → 1
INTABLE = INEMPLY → 2
CONVERT = on → 3
SELECT = * → 4以下にEXTRACT定義文のオペランドの指定時に注意すべき点を説明します。各オペランドの番号は、記述例の番号と対応します。
グループ単位のレプリケーションでは、以下の定義文が必要です。
REPLICAGROUP定義文
INTABLE定義文
OUTTABLE定義文
EXTRACT定義文
グループ単位のレプリケーションでのDBサービス定義の方法を、以下の運用例に基づいて説明します。
なお、ここで説明するもの以外にもDBサービス定義の定義項目は存在します。詳細については、“コマンドリファレンス”の“lxgensvコマンド” および“Linkexpress 運用ガイド”を参照してください。
運用資源
運用資源 | 複写元システム | 複写先システム |
|---|---|---|
OS | Linux | Linux |
コード系 | UNICODE系 | UNICODE系 |
データベース名 | 受注管理データベース | 受注管理データベース |
スキーマ名 | 受注スキーマ | 受注スキーマ |
表名 | 受注表 | 受注表 |
列名およびデータ型 | [受注表] | [受注表] |
[在庫表] | [在庫表] | |
抽出データの形式 | UTF-8コード系 | - |
運用形態
受注管理データベースの以下のデータをグループ単位に受注管理データベースに複写します。
受注表の仙台支店データ
在庫表の全データ

REPLICAGROUP定義文は、レプリケーショングループを定義する定義文です。グループ単位のレプリケーションを行う場合に必要です。
レプリケーション運用例でのREPLICAGROUP定義文の記述例を以下に示します。
詳細は、“コマンドリファレンス”の“lxgensvコマンド”の“REPLICAGROUP定義文”を参照してください。
REPLICAGROUP
NAME = SENDAI → 1
MEMBER = (OUTORDER,OUTSTOCK) → 2
FILE = /home/work/indata → 3
INCODE = unicode → 4
IN_UNICODE_TYPE = utf8-4 → 4
DATABASE = 受注管理データベース → 5
OUTCODE = unicode → 6
OUT_UNICODE_TYPE = utf8-4 → 6
INBYTEORDER = little → 7以下にREPLICAGROUP定義文のオペランドについて説明します。各オペランドの番号は、記述例の番号と対応します。
MEMBERオペランド(レプリケーショングループに属するDBサービス定義の識別名)
1つのレプリケーショングループに属するDBサービス定義の識別名(OUTTABLE識別名、メンバDBサービス定義名ともいいます)を指定します。
レプリケーショングループに属するDBサービス定義の識別名(OUTTABLE識別名)を1つ以上記述します。
入力ファイル名を指定します。本指定値は、一括差分複写の場合に有効となります。全複写の場合、INTABLE定義文のFILEオペランドの指定値を使用します。
入力データのコード系を指定します。
注意
INCODEオペランドにunicodeを指定した場合には、IN_UNICODE_TYPEオペランドの指定が必要です。
複写先データベースのデータベース名を指定します。
データベースへ反映するデータのコード系を指定します。
注意
OUTCODEオペランドにunicodeを指定した場合には、OUT_UNICODE_TYPEオペランドの指定が必要です。
INBYTEORDERオペランド(入力データの数値表現形式)
入力データに含まれる数値の表現形式を指定します。
グループ単位のレプリケーションの運用例でのINTABLE定義文の記述例を以下に示します。
内容および形式の詳細については、“Linkexpress 運用ガイド”を参照してください。
INTABLE
NAME = INORDER → *
DATATYPE = (local-member,non-attribute add null field) → 1
ITEM = ((@TRHEADER,char(8) except null field),
(@DBOP,sint),
(ITEM1,sint),
(ITEM2,sint),
(ITEM3,sint),
(ITEM4,int),
(ITEM5,vchar(20))) → 2
FILE = /home/work/order → 3INTABLE
NAME = INSTOCK → *
DATATYPE = (local-member,non-attribute add null field) → 1
ITEM = ((@TRHEADER,char(8) except null field),
(@DBOP,sint),
(ITEM1,sint),
(ITEM2,vchar(40)),
(ITEM3,int),
(ITEM4,int)) → 2
FILE = /home/work/stock → 3以下にINTABLE定義文のオペランドについて説明します。各オペランドの番号は、記述例の番号と対応します。
なお、*印として表したオペランドは、表単位のレプリケーションの場合と同じです。“1.1.7.1 表単位のレプリケーションでのDBサービス定義”を参照してください。
グループ単位のレプリケーションの場合は、入力データの種別に“local-member”を指定してください。
抽出される差分データの形式に従ってください。
以下に複写元システムで抽出される差分データのレコード形式とITEMオペランドでの指定形式について説明します。
抽出レコード形式
レコードの形式にはナル表示域あり(抽出定義でNULLIND = YESを指定)と、ナル表示域なし(抽出定義でNULLIND = NOを指定)の2種類があります。
レコードの構成を以下に示します(コード系をUTF-8、数値の表現形式を後退法で示します。)。
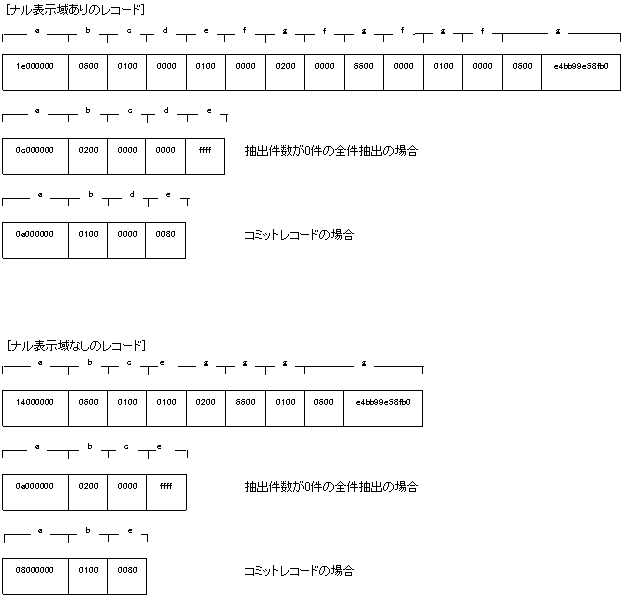
レコード長(長さ:4バイト、属性:INTEGER)
レコードの先頭から末尾までの長さが設定されます。
有効列数(長さ:2バイト、属性:SMALLINT)
抽出される項目数だけでなく、抽出識別子および差分反映操作も個数に含まれます。コミットレコードの場合は差分反映操作だけの個数が設定されます。
抽出識別子(長さ:2バイト、属性:SMALLINT)
抽出側のレプリケーショングループ内の表に対するユニークなIDが設定されます。全件抽出の場合はつねに0x0000が設定されます。
コミットレコードの場合、本フィールドは存在しません。
差分反映操作のナル表示域(長さ:2バイト、属性:SMALLINT)
つねに0x0000が設定されます。
差分反映操作(長さ:2バイト、属性:SMALLINT)
0x0000:全件抽出
0x0001:追加差分
0x0002:更新差分
0x0003:削除差分
0xffff:抽出件数が0件の全件抽出
0x8000:コミットレコード
ナル表示域 (長さ:2バイト、属性:SMALLINT)
0x0000:ナル値でない
0xffff:ナル値
抽出件数が0件の全件抽出の場合およびコミットレコードの場合、本フィールドは存在しません。
データ項目 (長さ:データ型によって異なります)
各項目のデータがバイナリ形式で抽出されます。
詳細は、“システム設計ガイド”の“抽出データ項目の形式”を参照してください。
抽出件数が0件の全件抽出の場合およびコミットレコードの場合、本フィールドは存在しません。
ITEMオペランドでの指定形式
レコード長、有効列数および抽出識別子
レコード長、有効列数および抽出識別子の3つを合わせて、8バイトのナル表示域なしの文字列として、“@TRHEADER,char(8) except null field”と指定します。
DATATYPEオペランドの入力データの形式でナル表示域の有無に“except null field”を指定した場合、“@TRHEADER,char(8)”だけの指定も可能です。
差分反映操作
以下のように指定します。
ナル表示域ありのレコードの場合:“@DBOP,sint add null field”
ナル表示域なしのレコードの場合:“@DBOP,sint except null field”
DATATYPEオペランドの入力データの形式でナル表示域の有無に差分反映操作と同じ値を指定した場合、“@DBOP,sint”だけの指定も可能です。
各データ項目の属性
“システム設計ガイド”の“抽出データ項目の形式”を参照してください。
各データ項目のナル表示域の有無
DATATYPEオペランドで入力データの形式を指定した場合はナル表示域の有無をITEMオペランドで指定する必要はありません。
DATATYPEオペランドの入力データの形式を指定していない場合は、以下のように指定します。
ナル表示域ありのレコードの場合:add null field
ナル表示域なしのレコードの場合:except null field
グループ単位のレプリケーションの場合、本オペランドの指定値は全複写時に有効になります。一括差分複写の場合、REPLICAGROUP定義文のFILEオペランドの指定値が使用されます。
グループ単位のレプリケーションの運用例でのOUTTABLE定義文の記述例を以下に示します。
内容および形式の詳細については、“Linkexpress 運用ガイド”を参照してください。
OUTTABLE
NAME = OUTORDER → *
DATATYPE = (database-member,enterprise/pgs) → 1
EXTRACT = EXTORDER → *
SCHEMA = 受注スキーマ → *
TABLE = 受注表 → *
ITEM = (@TRHEADER,@DBOP,受注番号,製品番号,数量,受注額,支店名) → *
LOADMODE = (difference,load) → 2OUTTABLE
NAME = OUTSTOCK → *
DATATYPE = (database-member,enterprise/pgs) → 1
EXTRACT = EXTSTOCK → *
SCHEMA = 受注スキーマ → *
TABLE = 在庫表 → *
ITEM = (@TRHEADER,@DBOP,製品番号,製品名,単価,在庫量) → *
LOADMODE = (difference,load) → 2以下にOUTTABLE定義文のオペランドについて説明します。各オペランドの番号は、記述例の番号と対応します。
なお、*印として表したオペランドは、表単位のレプリケーションの場合と同じです。“1.1.7.1 表単位のレプリケーションでのDBサービス定義”を参照してください。
DATATYPEオペランド(出力データの出力先およびデータベース・システムの種類)
グループ単位のレプリケーションの場合は、出力データの出力先に“database-member”を指定してください。
データベース・システムの種類には、複写先データベースに合わせ、以下のいずれかを指定してください。
Symfoware Server (Openインタフェース):symfoware/pgs
Symfoware Server (Postgres):enterprise/pgs
Enterprise Postgres:enterprise/pgs
全複写、一括差分複写を問わず、格納方式に“difference”を指定してください。
全複写、一括差分複写を問わず、格納方法に“load”を指定してください。
グループ単位のレプリケーションの運用例でのEXTRACT定義文の記述例を以下に示します。
内容および形式の詳細については、“Linkexpress 運用ガイド”を参照してください。
EXTRACT
NAME = EXTORDER
INTABLE = INORDER
CONVERT = on
SELECT = *EXTRACT
NAME = EXTSTOCK
INTABLE = INSTOCK
CONVERT = on
SELECT = *オペランドについての説明は、表単位のレプリケーションの場合と同じです。“1.1.7.1 表単位のレプリケーションでのDBサービス定義”を参照してください。