PRIMECLUSTERのクラスタシステムを構成する各ノード間のハートビートを行うことで、ノードが正常に動作しているか、およびクラスタ内のクラスタインタコネクトを利用した通信機能が正常であるかどうかを判断します。しかし、ユーザの業務やSANのホストアダプタの動作状態はクラスタインタコネクトを利用したハートビートでは判断できません。PRIMECLUSTERが提供するディテクタと呼ばれる監視プログラムは、ユーザ業務が動作するための各種コンポーネントおよび、ユーザ業務が使用するリソースの状態を監視します。各種リソースやユーザ業務の障害をディテクタが検出すると、PRIMECLUSTERのHAマネージャであるReliant Monitor Services (RMS) に通知されます。
RMSは以下の処理により、ユーザ資産であるデータ整合性を保証します。
ユーザ業務および各種リソースの監視
ユーザ業務を同時に複数実行させないこと
全てのクラスタノードの状態を確認した上でユーザ業務を自動起動する (RMS環境変数の設定により、制御されている場合は除く)
以下に、データ整合性を保証するための機能や処理の内容について説明します。
RMSはアプリケーション固有のルールおよびクラスタ構成で設定されます。RMSの構成情報は、ユーザが定義するユーザ業務固有の定義と、動作するクラスタ環境の情報で構成されます。ディテクタが障害を検出すると、RMSは定義に従い適切な処置をとり、ユーザ業務を続行させるために必要なリソースのリカバリを行います。リカバリ処理はユーザ業務、およびおのおののリソースごとに定義することができます。
RMSには以下のリカバリ処理があります。
ローカルリカバリ
ユーザ業務を他のノードに切り替えずに、現在のノードで再度Onlineに戻すリカバリ処理
リモートリカバリ
ユーザ業務を他のノードに切り替える (フェイルオーバ)
クラスタパーティションとはクラスタインタコネクトの障害により起こりうる現象のことです。
クラスタインタコネクトに障害が発生しても、クラスタの一部または全てのノードは処理を続行できますが、クラスタノードの一部のノード間通信は停止した状態になります。(スプリットブレイン状態とも呼ばれます。)スプリットブレイン状態を回避するには、クラスタインタコネクトの冗長化が有効ですが、充分ではありません。
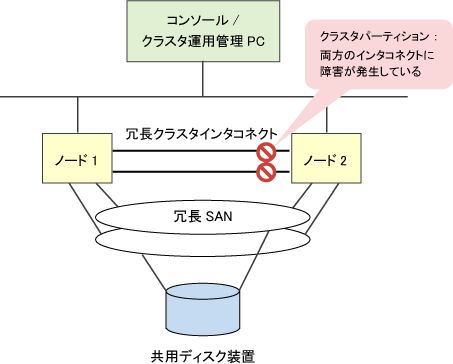
以下の図は、冗長化したクラスタインタコネクトの両方の接続が切断したことにより、ノード1とノード2の通信が停止した場合の例です。
2つのノードはまだSAN にアクセスすることができるため、各ノード上で独立してリカバリ処理を行うと、ユーザ業務がクラスタの2つのノードで互いに認識されないまま実行される可能性があります。この状態で互いに連携されていないユーザ業務が個別にデータを更新すると、共用ディスク装置上のユーザ資産を破損する危険性が生じます。
図1.2 2ノードクラスタのクラスタパーティション
ユーザ資産を破壊しないため、PRIMECLUSTERでは、以下のようなノード間の整合性を保つしくみを提供します。
クラスタシステム内の各ノードは、ハートビートによって相手ノードと通信できなかった場合(動作しているのか、または停止しているのかが不明な場合)、相手ノードをLEFTCLUSTER 状態に設定します。
PRIMECLUSTERは、各ノードのリカバリ処理を開始する前に、クラスタシステム内のノードが以下の状態であることを確認します。
すべてノードが、動作中(UP)または停止中(DOWN)のいずれかの状態であること
(LEFTCLUSTER状態のノードが存在しないこと)
動作中のノードが他のすべての動作中のノードと通信可能であること
PRIMECLUSTERでは、上記のようにノード間の整合性が保たれている状態を「クラスタ整合状態(クォーラム)」といいます。
PRIMECLUSTER のマニュアルでは「クラスタ整合状態」と「クォーラム」とは同じ意味です。クラスタ整合状態とは、クラスタの全てのノードが動作中 (UP) または 停止中(DOWN) のいずれかの状態で、動作中のUPノードが他の全てのUP状態のノードと通信可能な状態である場合に設定されます。クラスタ内で定義されているユーザ業務は、共用ディスク装置上のデータの変更を伴う処理を開始する前にクラスタがクラスタ整合状態になっていることを確認する必要があります。RMSはクラスタシステム内のユーザ業務起動前に、クラスタシステムがクラスタ整合状態になっていることを確認してから動作します。
PRIMECLUSTERは、クラスタシステムを構成するノードのアーキテクチャに応じた方法で、クラスタノードの強制停止を行います。PRIMECLUSTERはノードがLEFTCLUSTER状態であると判断すると、ノードを強制停止してユーザ業務のリカバリ処理 (ローカルリカバリあるいはリモートリカバリ (フェイルオーバ)) を行い、データの整合性を保証します。
注意
クォーラムという用語の意味は、クラスタパーティションの処理を説明する文書にはさまざまな意味に用いられています。通常は、クラスタシステムを構成するノードがn個存在した場合、互いに (n + 1)/2 個のノードが参照できればクォーラムであり、クォーラムでないノードはI/O処理を行うことができません。PRIMECLUSTERではクォーラムの意味が上記の意味と異なるため、「クラスタ整合状態」という言葉を採用しています。
PRIMECLUSTERはクラスタ整合性モニタ (CIM) により、ユーザ業務がクラスタの複数ノードで共用されている資源を使った処理を、処理の競合をおこすことなく安全に処理することができるかどうかを判断します。つまり、処理を行うノードが、クラスタ整合状態であるクラスタシステムのメンバである場合、共用リソースを安全に使用することができることになります。
PRIMECLUSTERシステムにおける整合状態は、CIMが監視するクラスタシステムの全てのノードが動作中 (UP) または停止中 (DOWN) のいずれかの状態、かつ安全な状態である場合に設定されます。CIMが監視するノードは、CIM構成時に設定されたノード全てです。CIMはクラスタの状態を調べる場合、これらのノードのみを対象とします。
CIMは他のノードが安全である場合、クラスタ整合状態であると判断します。
クラスタを構成するノードの状態を調べる方式はCIM方式と呼ばれます。CIMは複数の異なるCIM方式を使用することができます。PRIMECLUSTERでは以下の方式が使用可能です。
NSM
ノード状態モニタ (NSM) はノードの状態を定周期で監視し、現在および過去のクラスタノードのノード状態を管理します。この方法はNULL方式またはデフォルトCIM方式とも呼ばれます。NSMはPRIMECLUSTER CFに組み込まれています。
RCI
RCI (Remote Cabinet Interface) は、Solarisシステム上でシステム間の状態通知やシステム制御を非同期で行う SPARC Enterprise Mシリーズ専用制御機構です (詳細については、“PRIMECLUSTER Cluster Foundation 導入運用手引書” を参照してください)。
XSCF SNMP
XSCF SNMP (eXtended System Control Facility Simple Network Management Protocol) は、Solaris システム上でシステム間の状態通知やシステム制御を非同期で行う SPARC M10 専用制御機構です ( 詳細については、“PRIMECLUSTER Cluster Foundation 導入運用手引書” を参照してください)。
MMB
MMB (Management Board) は、Linuxシステム上でシステム間の状態通知やシステム制御を非同期で行うPRIMEQUEST専用制御機構です (詳細については、“PRIMECLUSTER Cluster Foundation 導入運用手引書 ” を参照してください)。
PRIMECLUSTER は、複数の CIM 方式を登録して使用することができます。
複数のCIM方式が登録されている場合は、優先度の高い方式でノードの状態が判断できない場合にのみ優先度の低い方式を使用して確認します。例として、CIM方式としてRCIとNSMが登録され、RCI の方が優先度が高い場合は、CIMは、RCIを使用したCIM方式で確認を行います。
対象がノードまたはパーティションであれば、RCI~CIM方式がUPまたはDOWNを返して処理は終了します。一方、RCI 方式によりチェックされるノードがRCIに接続されていない、またはRCIが故障していた場合は、RCI方式は失敗するため、CIMはNSMによるCIM方式を使用してノード状態を調べます。
PRIMEQUEST ノードでは、CIM 方式として MMB と NSM が使用され、MMB の方が優先度が高い場合は、CIM は、MMB を使用した CIM 方式で確認を行い、MMB CIM 方式が UP または DOWN を返して処理は終了します。MMB 方式によりチェックされるノードが MMB に接続されていない、または MMB が故障していた場合は、MMB 方式は失敗するため、CIM は NSM による CIM 方式を使用してノード状態を調べます。
CIMは対象ノードに関して、クラスタ整合状態である (TRUE)、 またはクラスタ整合状態でない (FALSE) のいずれかのノード状態を通知します。TRUEとFALSEの定義は以下のとおりです。
TRUE
全てのCIMノードにとって、UP、またはDOWNの状態が既知の状態
FALSE
全てのCIMノードにとって、UP、またはDOWNの状態が不明な状態
CIMは、クラスタ整合状態である場合にユーザ業務に対して動作することを許可しますが、クラスタ整合状態でない場合はこれを解決するような処理を行いません。高可用性要件ではクラスタ整合状態を保証するために複数の方式が使用されます。しかし、ノード間の協調を必要とせず、かつ完全に効果のある方法は1つだけです。PRIMECLUSTERでは、クラスタ整合状態を妨げるような問題が発生した場合は、シャットダウン機構 (SF) を使用して、クラスタ整合状態に戻します。図1.2 2ノードクラスタのクラスタパーティションの例では、2つのノードは互いに相手ノードに対してLEFTCLUSTERを通知した結果、CIMはFALSEと判断します。PRIMECLUSTERは、クラスタシステムをクラスタ整合状態にするため、SFは強制的に相手ノードを停止することで、生存ノードを1つにして競合の発生しない安全な状態にします。
SFの設定により、PRIMECLUSTERは異常となったノードを強制停止することができます。SFはノードを強制停止するような要求を受けると、ノードの強制停止を行い、成功した場合にノードの状態はLEFTCLUSTERからDOWNに変化します。
状態をLEFTCLUSTERからDOWNに変更すると PRIMECLUSTERは各種、リカバリ処理を開始します。ノードの強制停止の方法は、システムによって異なります。たとえば、Solarisでは有効なシャットダウンエージェントが、Linuxでは使用できないことがあります。
システムに登録されている全ての方式を実行しても要求したノードの強制停止成功の応答が得られない場合、処理はそこで停止します。この場合、クラスタはクラスタ整合状態ではない状態のままなので、オペレータによる操作が必要になります。
このフェイルセイフ方式により、誤ってクラスタパーティションに分割されたクラスタシステムの2箇所でユーザ業務を実行し、その競合によりユーザデータが破壊されることを防ぐことができます。また、システム負荷 (System Load) が著しく高いことなどが原因で、ノードがハートビートに対する応答に失敗し、後から復活するという状況でも、ユーザ資産は競合から保護されます。
注意
PRIMECLUSTERはハードウェア固有のさまざまな方法で、SolarisまたはLinuxが稼動するノードをリセットするように定義することができます。詳細については、“PRIMECLUSTER Cluster Foundation 導入運用手引書” を参照してください。
PRIMECLUSTERは、ハードウェアの機能を使用してシステム状態の変化をすばやく検出し、クラスタを構成するノードに通知します。PRIMECLUSTERのこの監視機能を非同期監視(Monitoring Agent)といいます。非同期監視を使用しない場合、ノードのパニックを検出する機能はクラスタのハートビートタイムアウトのみであるため、デフォルトのハートビート間隔の設定では検出に10秒が必要です。非同期監視を使用した場合、ノードのパニックを即時に検出することができます。非同期監視テクノロジーにより、PRIMECLUSTERは監視対象ノードの障害からすばやく復旧することができます。非同期監視は、シャットダウン機構のプラグインとして実装されています。
ノードに異常が発生した場合、PRIMECLUSTERは以下の処理を行います。
ノード異常の検出
異常となった障害の通知
ノード状態の確認
ノードの強制停止
MAはノード異常を検出すると、ただちにSFに通知します。 SFは、MAによる障害通知が本当に正しいかどうかを判断するために、ノード状態に関する冗長確認を行います。 この検証処理は、正常に動作しているノードが誤って停止されないようにするために行われます。
SFは、以下のようにしてノードの状態を確認します。
全ての登録済みMAから再度ノードの状態情報を採取する。
CFハートビート要求への応答があったかどうかを確認する。
全てのMAからSFに対してノード障害の通知があり、CFからSFに対して、ハートビート要求への応答がなかった旨の通知があった場合は、SFはMAに対して障害の発生したノードの強制停止を要求します。 ノードの強制停止が完了すると、他方のノードはDOWNの状態になります。
ユーザ業務を適切にリカバリするには、ユーザ業務の正常な動作に必要なリソースをあらかじめRMSに定義し、その状態を通知しておかなければなりません。リソース構成およびリソース間の関係はきわめて複雑になる場合があります。RMS Wizard ToolsおよびRMS Wizard Kitは、これらの情報をRMSに指定するための構成定義を行います。また、userApplication Configuration Wizardを用いることでこれらをGUIにより構成することができます。RMS Wizard Toolsは、クラスタや一般的なアプリケーションサービスに関係する一般的な情報を設定します。
注意
RMS Wizard Kitの可用性についての詳細は、当社技術員 (SE) にお問い合わせください。