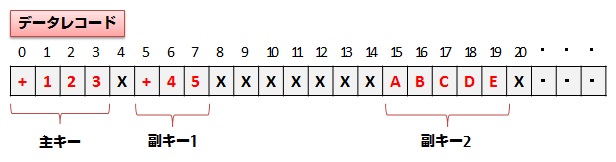
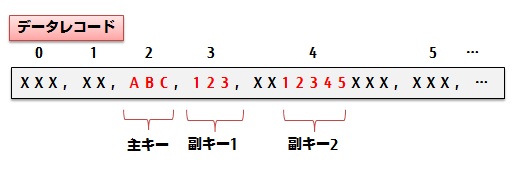
Shuffle&sortで使用するキー情報には、データのグループ化に使用される「主キー」と、並び替えに使用される「副キー」があります。主キーおよび副キーは複数指定可能です。キーごとに属性や並び順(昇順・降順)を指定することができます。
キー情報は、Hadoop入力データファイルごとに指定する必要があります。
設定内容 | 設定名(*) | 設定値 | 備考 |
|---|---|---|---|
主キー | sortkey.nn.main |
カンマ区切りで キー属性,オフセット,長さ,並び順 を指定します。 キー属性 “キー属性に指定する値”を参照 オフセット キーの先頭オフセットをバイト長で指定します。オフセットは0から始まります。 長さ キーの長さをバイト長で指定します 並び順 A(昇順)またはD(降順)を指定します省略した場合、昇順と見なします
カンマ区切りで キー属性,カラム目,並び順 または キー属性,カラム目:開始オフセット-長さ,並び順 を指定します。 キー属性 CSVまたはCSVN CSV:キーを文字として評価します CSVN:キーを数値として評価します カラム目:開始オフセット-長さ キーが存在するカラム目と、カラム内にあるキーの先頭オフセットおよび長さをバイト長で指定します 開始オフセットのみを指定した場合(-長さが指定されていない場合)は、カラムの末尾までを長さと見なします 並び順 A(昇順)またはD(降順)を指定します省略した場合、昇順と見なします | Shuffle&sortを使用する場合、指定必須 主キーを指定します。 複数指定する場合は/(スラッシュ)で区切って指定します。 このキーでグループ化されたデータが各Reduceタスクに渡されます。 |
副キー | sortkey.nn.sub | 省略可 副キーを指定します。 複数指定する場合は/(スラッシュ)で区切って指定します。 キーがCSVデータの場合、カラムは0番目から始まります。 キーがCSVデータの場合で、データ自体にセパレータ文字を含めたい場合は、カラムをダブルクォーテーションで囲む必要があります。 ただし、浮動フィールド指定にtrueが指定されている場合、フィールドを囲むダブルクォーテーションを考慮しません。 | |
ASCIIコードの 並び順 | sortkey.nn.colseq |
| 省略可 本指定が有効になるのは、キーの属性が以下の場合です。
|
SEPARATE指定なしの外部10進項目の並び順 | sortkey.nn.decimal |
| 省略可 本属性が有効になるのはキー属性がSEPARATE指定なしの外部10進項目の場合です。 |
内部浮動小数点の並び順 | sortkey.nn.float |
| 省略可 本属性が有効になるのはキー属性が内部浮動小数点項目の場合です。 |
指定例 |
| ||
*:設定名は「com.fujitsu.netcobol.hadoop.」で修飾します。
COBOLデータ種別 | 指定値 | |||||
|---|---|---|---|---|---|---|
字類 | 項類 | USAGE句 | SIGN句 | PICTURE句 | 呼び名 | |
数字 | 数字 | DISPLAY | なし | 9(4) | 外部10進 | 9 |
S9(4) | S9 | |||||
LEADING | S9(4) | S9L | ||||
TRAILING | S9T | |||||
LEADING SEPARATE | S9LS | |||||
TRAILING SEPARATE | S9TS | |||||
PACKED-DECIMAL | - | 9(4) | 内部10進 | 9P | ||
PACKED-DECIMAL | - | S9(4) | S9P | |||
COMP-6 | - | 9(4) | 符号なし内部10進 | 9PC6 | ||
COMP-6 | - | S9(4) | 符号付き内部10進 | S9PC6 | ||
BINARY,COMP | - | 9(4) | 規格2進 | 9B | ||
BINARY,COMP | - | S9(4) | S9B | |||
COMP-5 | - | 9(4) | システム2進項目 | 9C | ||
COMP-5 | - | S9(4) | S9C | |||
BINARY-CHAR | - | 9(4),S9(4) | int型2進整数項目 | BC | ||
BINARY-SHORT | - | BS | ||||
BINARY-LONG | - | BL | ||||
BINARY-DOUBLE | - | BD | ||||
+99.99E+99 | 外部浮動小数点項目 | EXFL | ||||
COMP-1 | - | 9(4),S9(4) | 単精度内部浮動小数点項目 | INFL | ||
COMP-2 | - | 9(4),S9(4) | 倍精度内部浮動小数点項目 | |||
数字編集 | DISPLAY | - | B / P V Z 0 9 , . * + - CR DB \ | ASCE | ||
英字 | 英字(*1) | DISPLAY | - | A | ASC | |
英数字 | 英数字(*1) | DISPLAY | - | A X 9 | ||
英数字編集(*1) | DISPLAY | - | A X 9 B 0 / | |||
日本語 | 日本語 | - | - | N | NLE16(*2) NLE32(*3) | |
日本語編集 | - | - | NB | |||
ブール | ブール | DISPLAY | - | 1(8) | 外部ブール項目 | BOOL |
(*1)ASCII(JIS8)コードのデータをEBCDICコード順に並べることができます。対応するEBCDICコードは以下です。
EBCDIC ASCII
EBCDIC 英小文字
EBCDIC カナ
(*2) UTF-16リトルエンディアンの場合「NLE16」を指定します。UTF-16ビッグエンディアンの場合「NBE16」を指定します。
(*3) UTF-32リトルエンディアンの場合「NLE32」を指定します。UTF-32ビッグエンディアンの場合「NBE32」を指定します。
参考
キー属性に「NLE」を指定した場合、「NLE16」が指定されたものと見なします。キー属性に「NBE」を指定した場合、「NBE16」が指定されたものと見なします。この指定は、互換のために用意されています。