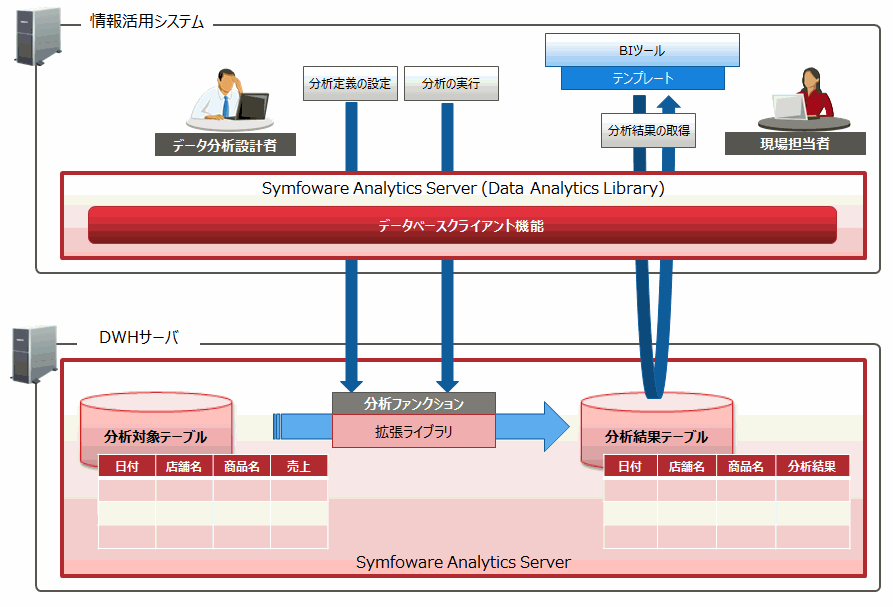
分析ファンクションは、Symfoware Analytics Serverに格納されたデータに対して、統計解析手法を利用したデータ分析を行います。また、その分析結果をテーブルおよびビューとして出力する機能です。
分析ファンクションと連携する拡張ライブラリは、データを転送する必要がなくSymfoware Analytics ServerのDWHサーバ上でカラムナテーブルを活かして高速に実行されます。
したがって、データ分析設計者は、データベースクライアント機能を使用して分析ファンクションを実行したあと、実行結果が格納されたテーブルをBIツールから参照することで、分析した結果を取得できます。
Symfoware Analytics Serverのデータベーステーブルの構成および利用したいデータ分析手法に合わせて、データ分析設計者が分析ファンクションを部分的に修正または一部をコピーして利用できます。
分析ファンクションにおけるユーザー
分析ファンクションの各操作を実行するユーザーには以下の種類があります。これらのユーザーには、実行する操作に合わせたデータベースユーザーを使用してください。
データ分析設計者
分析ファンクションを実行するための分析定義を設計して作成します。
分析ファンクションで使用する各テーブルに対して必要な権限は、以下の通りです。
テーブル名 | 必要な権限 |
|---|---|
分析対象テーブル | SELECT |
分析結果テーブル | INSERT、SELECT、UPDATE |
分析結果ビュー | SELECT |
データベース | CREATE、TEMPORARY |
現場担当者
実行された分析ファンクションの分析結果テーブルおよびビューを参照します。また、BIツールを利用して分析結果を可視化します。
分析ファンクションで使用する各テーブルに対して必要な権限は、以下の通りです。
テーブル名 | 必要な権限 |
|---|---|
分析結果テーブル | SELECT |
分析結果ビュー | SELECT |
参照
データベースユーザーの詳細は、“3.6 ユーザー定義”を参照してください。
図6.2 分析ファンクションのシステム構成
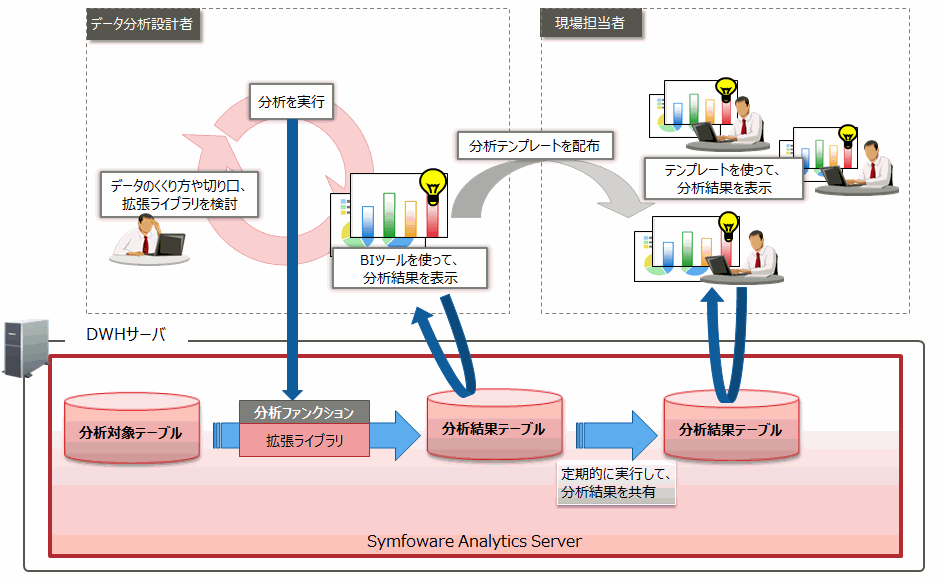
利用シーン
データ分析設計者は、分析ファンクションの実行結果をBIツール上で可視化しながら試行錯誤を行って、目的に応じた分析アルゴリズム(拡張ライブラリ)および分析対象のデータの組み合わせを決定します。また、決定した組み合わせで実行した分析結果を、BIツール上のグラフや表などで可視化したテンプレートを作成します。現場担当者などの利用者に、作成したBIツールのテンプレートを配布・共有することで、同じ視点・基準でデータを分析・活用することができます。
Symfoware Analytics Server上に分析対象のデータは分析対象テーブルとしてあり、分析ファンクションの結果は分析結果テーブルとしてあるため、定期的に追加されるデータに対して、現場担当者は、配付されたテンプレートを利用して分析できます。
参照
SQL関数と拡張ライブラリの詳細は、“6.2.1.3 pgxa_anls_ts_detect_outlier”を参照して下さい。
分析ファンクションを使用して、Symfoware Analytics Serverでデータ分析を行う場合の手順について説明します。
作業の流れ
以下の手順で行います。
手順 | 作業項目 | 参照先 |
|---|---|---|
1 | 分析の準備 | |
2 | 分析の実行 | |
3 | 分析結果の確認 |
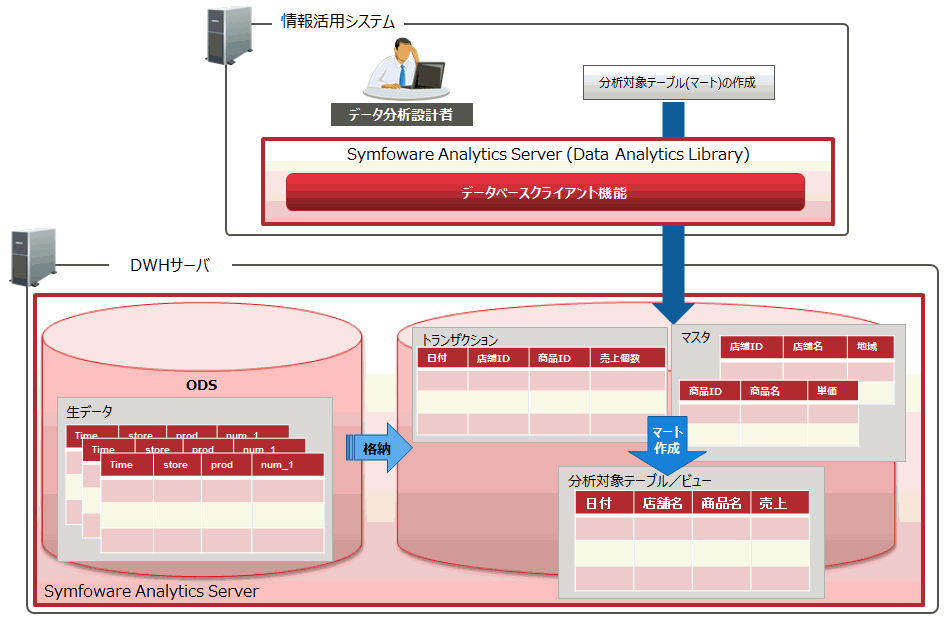
分析対象のデータは、データモデルに合わせて複数のテーブルに分けてDWHに格納します。
たとえば、基本的なデータモデルであるスタースキーマモデルでは、実データテーブル(売上実績など)といくつかのマスタテーブル(商品マスタ、店舗マスタなど)があり、それらのテーブルを結合して分析を行います。
データ分析設計者は、分析対象のデータを格納した以下のテーブルを分析ファンクションの入力テーブル(分析対象テーブル)として作成します。
テーブル
テーブルをもとに作成したビュー
複数のテーブルを加工して作成したテーブルまたはビュー
参照
作成する分析対象テーブルの詳細は、“6.2.1.3.6 分析対象テーブル”を参照してください。
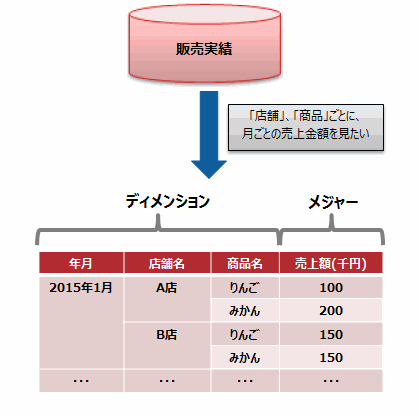
ここでは、分析ファンクションの分析対象となるデータについて、共通の用語について説明します。
データ分析では、実際のデータの内容(売上実績、顧客数)に着目して、分析を行います。この分析対象とするデータの内容をメジャーと呼びます。メジャーは、ファクトと呼ばれることもあります。
データ分析では、実際のデータの内容(メジャー)をどのように見るのかといった、データのくくり方や切り口があります。たとえば、“店舗別”、“商品別”、“月ごと”などの切り口が、売上実績に対して集計したり分析したりするときの分類キーとなります。これらのデータのくくり方や切り口のことをディメンションと呼びます。ディメンションは、“軸”や“次元”と呼ばれることもあります。
分析の実行で指定するパラメーターは、分析ファンクション向けに用意しているシステムカタログ(分析定義テーブル)に設定する必要があります。
分析定義テーブルに、分析対象テーブル・分析結果テーブルなどの分析に必要な情報を設定した分析定義を作成して、分析ファンクション(SQL関数)を実行すると、データ分析が実行されます。分析した結果は、分析結果テーブルとして設定したテーブルに出力されます。
1つの分析ファンクションに対して、1つの分析定義テーブルが対応します。また、分析定義テーブルの1行が1つの分析定義になります。
分析定義の作成および実行手順
データベースクライアント機能を利用して、データベースに接続します。
データベースの分析定義テーブルに、分析定義を追加します。
分析定義を指定して、分析ファンクション(SQL関数)を実行します。
実行した分析ファンクション(SQL関数)の戻り値を確認してください。異常終了している場合、SQL文を実行したコンソールに出力されているメッセージを確認して対処してください。
参照
分析定義テーブルおよび戻り値の詳細は、“6.2.1.3 pgxa_anls_ts_detect_outlier”の各分析ファンクションを参照してください。
分析定義の作成および実行例
以下は、分析定義の作成および実行例です。
psqlコマンドを使用して、データベースpostgresに接続します。
例)サーバのIPアドレスが“192.0.2.0”、ポート番号が“26500”に対して接続した例です。
> psql postgres psql (9.2.8) Type "help" for help.
分析定義の追加
分析定義を追加するために、SQL文のINSERT文を実行します。
なお、分析の実行時に指定する分析定義識別子(カラム名: id)は、自動採番されますので、SQL文のRETURNING句を指定して確認してください。
RETURNING句を省略した場合は、currval関数にシーケンス名(pgxa_def_anls_ts_detect_outlier_id_seq)を指定することで、直前に追加された定義の定義識別子を確認できます。
例)
postgres=# INSERT INTO pgxa_def_anls_ts_detect_outlier (in_table , out_table, out_col, out_view, dimensions, measure, time_col, time_field, algorithm) VALUES ('sales_detail', 'detect_outlier', 'outlier_in_sales', 'sales_detail_and_outlier', ARRAY['store_name', 'product_name'], 'sales', 'ship_date', 'month', 'PgxaTsDetectOutlierUsingArima') RETURNING id;
id
----
10
(1 row)
INSERT 0 1分析の実行
手順2で追加した分析定義の分析定義識別子(カラム名: id)を指定して実行します。
例)
postgres=# SELECT pgxa_anls_ts_detect_outlier(10); pgxa_anls_ts_detect_outlier ----------------------------- t (1 row)
分析ファンクションの実行結果は、Symfoware Analytics Serverのデータベーステーブル(分析結果テーブルおよび分析結果ビュー)として出力されます。BIツールから、データベースクライアント機能を使用して、分析結果テーブルおよび分析結果ビューを参照することによって、分析結果を取得できます。
参照
分析結果テーブルの詳細は、“6.2.1.3.7 分析結果テーブル”を参照してください。
分析結果ビューの詳細は、“6.2.1.3.8 分析結果ビュー”を参照してください。
BIツールで作成できるグラフや表の例は、“6.2.1.1.5 BIツールからの結果確認方法”を参照してください。
BIツールからSymfoware Analytics Serverのデータベーステーブルおよびビューを参照する方法は、各BIツールのマニュアルを参照してください。
ポイント
分析結果テーブルは、BIツール上ですでに抽出の設定を実施されているテーブルと分析ファンクションの実行結果を、BIツール上で結合してグラフなどの可視化を行いたい場合に利用します。
分析結果ビューは、分析対象テーブルと分析ファンクションの実行結果が結合されているため、BIツール上で結合せずにグラフなどの可視化が行えます。
作成した分析定義を変更または削除する場合は、以下の手順で行ってください。
データベースクライアント機能を使用して、データベースに接続します。
データベースの分析定義テーブルの分析定義から、分析結果テーブル名、分析結果カラム名、および分析結果ビュー名を確認します。
参照
分析定義テーブルの詳細は、“6.2.1.3.4 分析定義テーブル(pgxa_def_anls_ts_detect_outlier)”を参照してください。
変更または削除する分析定義の分析結果テーブルおよび分析結果ビューを削除します。
分析結果テーブルの削除は、pgxa_drop_tableシステム関数およびSQLのDROP FOREIGN TABLE文で実施してください。
分析結果ビューの削除は、pgxa_drop_viewシステム関数およびSQLのDROP VIEW文で実施してください。
分析定義を更新または削除してください。
分析定義の更新は、SQL文のUPDATE文を実行してください。また、分析定義の削除は、SQL文のDELETE文を実行してください。
分析定義の更新例
以下の分析定義を更新する場合について説明します。
分析定義テーブル: pgxa_def_anls_ts_detect_outlier
分析定義識別子: 10
psqlコマンドを使用して、データベースpostgresに接続します。
サーバのIPアドレスが“192.0.2.0”、ポート番号が“26500”に接続します。
> psql postgres psql (9.2.8) Type "help" for help.
分析定義テーブルの確認
分析定義テーブルpgxa_def_anls_ts_detect_outlierから、更新対象となる分析定義識別子“10”の分析結果テーブル名、分析結果カラム名、および分析結果ビュー名を確認します。
postgres=# SELECT out_table, out_col, out_view FROM pgxa_def_anls_ts_detect_outlier WHERE id = 10; out_table | out_col | out_view ----------------+--------------------+-------------------------- detect_outlier | outlier_in_sales | sales_detail_and_outlier (1 row)
分析結果ビューおよび分析結果テーブルの削除
手順2で確認した分析結果ビューおよび分析結果テーブルを削除します。
分析結果ビューの削除は、pgxa_drop_viewシステム関数およびSQL文のDROP VIEW文で実施します。分析結果テーブルの削除は、pgxa_drop_tableシステム関数およびSQL文のDROP FOREIGN TABLE文で実施します。
postgres=# SELECT pgxa_drop_view('sales_detail_and_outlier');
pgxa_drop_view
----------------
t
(1 row)
postgres=# DROP VIEW sales_detail_and_outlier;
DROP VIEW
postgres=# SELECT pgxa_drop_table('detect_outlier');
pgxa_drop_table
----------------
t
(1 row)
postgres=# DROP FOREIGN TABLE detect_outlier;
DROP FOREIGN TABLE分析定義の更新
分析定義(分析定義識別子“10”)をSQL文のUPDATE文で更新します。
postgres=# UPDATE pgxa_def_anls_ts_detect_outlier SET dimensions = ARRAY['store_name', 'category'] WHERE id = 10; UPDATE 1
分析定義の削除例
以下の分析定義を削除する場合について説明します。
分析定義テーブル: pgxa_def_anls_ts_detect_outlier
分析定義識別子: 10
“分析定義の更新例”の手順1から手順3と同じ手順で分析結果ビューおよび分析結果テーブルを削除します。
削除したあと、分析定義テーブル(分析定義識別子“10”)をSQL文のDELETE文で削除します。
postgres=# DELETE FROM pgxa_def_anls_ts_detect_outlier WHERE id = 10; DELETE 1
BIツールから、分析ファンクションを利用して分析を行った結果を確認する方法について説明します。
本節では、BIツールであるTableauおよびQlikViewのグラフ上に“ずれの検知”による分析結果として、“分析結果ビュー”をもとに表示する手順を例としています。TableauおよびQlikViewのマニュアルを参照して操作したうえで、以下の手順を参照してください。
Tableau 9.0を利用する場合
Tableau 9.0を利用する場合は、以下の手順で行います。
分析結果ビューのデータを取得
[データソースの編集]から、Symfoware Analytics Serverが提供するデータベースクライアントのODBCドライバ(Symfoware Server ANSI)を選択して、DWHサーバに接続します。
[表]からテキストボックスを使用して、分析結果ビューを検索したあと選択します。
分析結果カラム(outlier_in_sales)が、[シート]上の[メジャー]として表示されます。
注意
Symfoware Analytics Serverでは、SQL文のGROUP句の各列の位置からグループ化列を参照する操作に対応していません。したがって、ODBC接続のカスタマイズでは、各列の位置からグループ化列を参照しない設定にしてください。
メジャーの値の時間推移をグラフ表示
[シート]に移動して、以下のカラムを[列]および[行]に設定します。
[列]シェルフ
日時カラムship_date
[行]シェルフ
ディメンションカラムstore_name, product_name
メジャーカラムsalesの合計
グラフとして、メジャーカラムsalesの時間推移が表示されます。
注意
Symfoware Analytics Serverでは、日付型へのSQL文のEXTRACT関数を利用した操作に対応していません。そのため、Tableau上では日付型のカラムのデータ型を文字列として設定する必要があります。
検出されたずれを表示
分析結果カラムoutlier_in_salesを[ディメンション]として設定します。
分析結果カラムoutlier_in_salesを[マーク]カード上の[色]に設定します。
検出されたずれの箇所が、ほかの箇所とは別の色として表示されます。
QlikView 11.20を利用する場合
QlikView 11.20を利用する場合は、以下の手順で行います。
分析結果ビューのデータを取得
[ロード スクリプトの編集]ダイアログから、Symfoware Analytics Serverが提供するデータベースクライアントのODBCドライバ(Symfoware Server ANSI)を選択して、DWHサーバに接続します。
[データベースのテーブル]から、分析結果ビューを選択します。
分析結果カラム(outlier_in_sales)を含めた分析結果ビューのカラムが、ロードされるように設定します。
分析結果カラム(outlier_in_sales)が、[項目]として利用できるようになります。
ディメンションの設定
メイン画面から[リストボックスの追加]でディメンションカラム(store_name, product_name)を[リストボックス表示項目]に追加します。
メジャーの値の時間推移をグラフに表示
メイン画面から[シートオブジェクトの追加]で[チャート]を選択したあと、[軸項目]に日時カラムship_dateを指定します。
[シートプロパティ]の[数式の編集]で、売上金額salesの合計を計算する定義を設定します。
グラフとして、メジャーカラムsalesの時間推移が表示されます。
検出されたずれを表示
手順3で設定した売上金額の定義の[背景色]の設定で、分析結果カラムoutlier_in_salesの値によって色を変えるように定義を設定します。
検出されたずれの箇所が、ほかの箇所とは別の色として表示されます。
利用者が分析ファンクションを流用して新しい統計解析手法を試したいときは、以下の方法があります。
用意されている分析ファンクション(SQL関数)のソースを参照して、新しくSQL関数を作成する方法です。
用意されている分析ファンクションの分析処理部分のみを、利用者が作成した統計解析手法に入れ替える方法です。
Symfoware Analytics Serverが提供する分析ファンクションを流用して、新しいSQL関数を作成できます。分析ファンクション(SQL関数)のソーステキストはpg_procカタログのソースコードカラムprosrcから参照できます。
参照
SQL関数の作成方法の詳細は、“2.5 Symfoware Analytics Serverで利用するオープンソース・ソフトウェアマニュアル”の“PL/R User’s Guide - R Procedural Language”を参照してください。
注意
分析定義テーブルは、分析ファンクションごとに作成する必要があります。分析ファンクションを流用して、新規にSQL関数を作成する場合は、SQL関数に対応する分析定義テーブルを新規に作成して、以下のように流用したソーステキスト内で定義されている分析定義テーブル名を変更してください。
####################### # analytics definition table ####################### deftblname <- "分析定義テーブル名"
分析ファンクションpgxa_def_anls_ts_detect_outlierのソーステキストを参照する場合の例を示します。
以下の手順で行います。
psqlコマンドを使用して、データベースpostgresに接続します。
サーバのIPアドレスが“192.0.2.0”、ポート番号が“26500”に接続します。
> psql postgres psql (9.2.8) Type "help" for help.
分析定義テンプレートのソーステキストの取得
pg_procカタログの関数名カラムpronameに分析ファンクション名pgxa_def_anls_ts_detect_outlierを指定してソースコードカラムprosrcの内容を表示します。
以下の例のソースは省略しています。
postgres=# select prosrc from pg_proc where proname = 'pgxa_anls_ts_detect_outlier';
prosrc
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
+
# global.pgxa.* +
global.pgxa.db.connect <- NULL +
+
#' pgxa_anls_ts_detect_outlier +
#' +
#' Outlier detection analysis of time-series data +
#' +
#' @param x analytics definition id +
#' @return boolean +
#' @export stringr DBI RPostgreSQL forecast +
#' +
pgxa_anls_ts_detect_outlier <- function( x = 1 ) +
{ +
library(stringr) +分析ファンクションで実行している分析の処理(拡張ライブラリ)を、データ分析設計者が作成したRの関数(以降では、ユーザー分析ライブラリと呼びます。)に置き換えることができます。
ユーザー分析ライブラリを使う場合、以下の手順で行ってください。
参照
ユーザー分析ライブラリのインターフェースの詳細は、“6.2.1.3 pgxa_anls_ts_detect_outlier”を参照してください。
R言語の関数の作成
“6.2.1.3.10 分析ライブラリのインターフェース”で説明するインターフェースを持つRの関数を作成します。
R言語の関数の登録
plr_modulesテーブルに、手順1で作成したR言語の関数をINSERT文の実行により追加します。plr_modulesテーブルは、Symfoware Analytics Serverのセットアップ時に自動的に作成されます。
参照
plr_modulesテーブルの詳細は、“2.5 Symfoware Analytics Serverで利用するオープンソース・ソフトウェアマニュアル”の“PL/R User’s Guide - R Procedural Language”を確認してください。
R言語の関数の有効化
システム関数reload_plr_modulesを実行することで、手順2で登録したR言語の関数を有効にします。
参照
reload_plr_modulesの詳細は、“2.5 Symfoware Analytics Serverで利用するオープンソース・ソフトウェアマニュアル”の“PL/R User’s Guide - R Procedural Language”を確認してください。
分析定義テーブルの設定
ユーザー分析ライブラリを利用するには、アルゴリズム名に手順2で登録した関数名を指定します。
また、ユーザー分析ライブラリでR言語のパッケージを利用する場合は、分析定義テーブルの追加パッケージにR言語のパッケージ名を指定してください。
例
ユーザー分析ライブラリの作成例
ユーザー分析ライブラリ(MyTsDetectOutlier)を作成して、pgxa_anls_ts_detect_outlierの分析の処理を置き換える手順を例として説明します。
R言語の関数の作成
任意のエディタを利用して、分析ライブラリと同じインターフェースとなるR言語の関数を作成します。
MyTsDetectOutlier <-
function(target = NULL, samples = NULL, custom.params = NULL) {
# 直前の時間帯(例:前日)からの差の割合が
# 閾値を超えた箇所(ずれ)を検出します。R言語の関数の登録
手順1で作成したR言語の関数をplr_modulesテーブルに追加するために、データベースに接続してINSERT文を実行します。modsrcカラムには手順1で作成したR言語の関数のソースを指定して、modseqカラムには0を指定してください。
postgres=# INSERT INTO plr_modules (modseq, modsrc)
VALUES (0,'MyTsDetectOutlier <- function(target = NULL, samples = NULL, custom.params = NULL) {
if( 1 < length(custom.params)) {
stop("Invalid Custom Param")
}
threashold <- -0.2
if ( 0 < length(custom.params)) {
i.th <- custom.params[[1]]
if (! is.null(i.th) && ! is.na(i.th)) {
threashold <- custom.params[[1]]
}
}
dif <- 0
predicted <- samples[nrow(samples),2]
actual <- target[,2]
dif <- actual - predicted
sigma <- samples[nrow(samples),2]
difrate <- dif / sigma
ret <- NULL
if (difrate < threashold) {
ret <- list(1, predicted, actual, difrate, dif)
} else {
ret <- list(0, predicted, actual, difrate, dif)
}
return (ret)
}
');
INSERT 0 1登録したRの関数の有効化
手順2で登録したRの関数を有効にするために、システム関数reload_plr_modulesを実行します。
postgres=# SELECT reload_plr_modules (); reload_plr_modules -------------------- OK (1 行)
分析定義テーブルの設定
作成したユーザー分析ライブラリの関数名(MyTsDetectOutlier)と利用するR言語のパッケージ名(zooおよびtimeDate)を指定します。
postgres=# INSERT INTO pgxa_def_anls_ts_detect_outlier (in_table , out_table, out_col, out_view, dimensions, measure, time_col, time_field, algorithm, ex_pkgs) VALUES ('sales_detail', 'detect_outlier', 'outlier_in_sales', 'sales_detail_and_outlier', ARRAY['store_name', 'product_name'], 'sales', 'ship_date', 'month', 'MyTsDetectOutlier ', ARRAY['zoo', 'timeDate']) RETURNING id;
id
----
11
(1 row)
INSERT 0 1pgxa_anls_ts_detect_outlierは、指定した分析定義識別子に対応する分析定義テーブルの設定に沿って、ずれを検出します。結果は、分析結果テーブルの分析結果カラムに格納されます。
時間とともに記録されるデータが格納されている分析対象テーブルから、ディメンションの組み合わせごとにメジャーを集計して時系列データを算出します。時系列データとは、時間とともに変動する値を、ある時間間隔(日ごと等)で記録したデータのことです。また、算出された時系列データに対して、拡張ライブラリで決められたルールに沿って、ほかの時間帯と異なる箇所(ずれ)を検知します。
たとえば、チェーン展開しているスーパーの全店舗の売上明細から、店舗・商品カテゴリごとの売上金額を1日単位で集計して、前日から売上金額が20%以上減少している店舗・商品カテゴリを検知します。このとき、「前日から売上金額が20%以上減少している箇所がずれである」ということが、拡張ライブラリで決められたルールになります。
このルールに沿って検知されたずれの箇所は、分析結果テーブルに格納されます。さらに、分析結果テーブルに格納された結果と分析対象テーブルを結合した分析結果ビューを自動的に生成します。
参考
分析結果が分析結果テーブルに格納された場合、本関数はTRUEを返却します。
分析定義テーブルの設定の詳細については、“6.2.1.3.4 分析定義テーブル(pgxa_def_anls_ts_detect_outlier)”を参照してください。
分析定義識別子のデータ型は、INTEGER型を指定してください。
分析定義識別子には、分析定義テーブルpgxa_def_anls_ts_detect_outlierの分析定義識別子カラムidの値を設定してください。指定した分析定義識別子に対応する定義(行)の設定で分析が実行されます。
戻り値は、BOOLEAN型です。
以下の場合、本関数はFALSEを返却して、エラーの内容を説明するメッセージが出力されます。
指定した定義識別子、または、対応する分析定義に誤りがある場合
分析結果テーブルがすでに存在して“分析結果テーブル”で説明するカラムのデータ型・制約と異なる場合
詳細は、“6.2.1.3.7 分析結果テーブル”を参照してください。
ずれの算出に失敗した場合
分析結果ビューがすでに存在する場合、本関数はTRUEを返却します。

WHERE句を使用して分析定義テーブルの絞込み条件を指定しない場合は、分析対象テーブルのデータすべてに対して、分析を実行します。したがって、分析に長時間かかることがあります。
分析対象とするデータが大量である場合、長時間にわたってCPU負荷が高い状態になる場合があります。
同じ分析結果テーブルを複数の分析定義で利用する場合は、同じディメンション、日時集計単位を指定してください。
例
たとえば、以下の分析定義識別子1,2は、同じディメンション(store_name, product_name)および日時集計単位(month)を指定しているため、同じ分析結果テーブル(outlier)を分析結果テーブルとして指定できます。
postgres=# SELECT id,dimensions,time_field,out_table,out_col from pgxa_def_anls_ts_detect_outlier where id = 1 or id = 2;
id | dimensions | time_field | out_table | out_col
----+-------------------------+------------+-----------+---------
1 | { store_name,product_name } | month | outlier | outlier_in_sales1
2 | { store_name,product_name } | month | outlier | outlier_in_sales2分析ファンクションpgxa_anls_ts_detect_outlierの分析の定義を設定・参照するための分析定義テーブルです。
項目 | カラム名 | データ型 | 省略可否 (○:省略可、×:必須、-:設定不可) | 説明 | デフォルト値 |
|---|---|---|---|---|---|
分析定義識別子 | id | integer | - | 自動採番されるため、追加時に指定しないでください。 | - |
分析結果テーブル名 | out_table | varchar(63) | × | 分析結果を格納するテーブル名を指定します。省略できません。 分析結果テーブルが存在しない場合は、自動生成されます。 分析結果テーブルの詳細は、“6.2.1.3.7 分析結果テーブル”を確認してください。 なお、以下の点に注意してください。
| - |
分析結果カラム名 | out_col | varchar(63) | × | メジャーカラムに対して分析された結果を出力するカラム名を指定します。省略できません。 ほかの分析定義が同じ分析結果テーブル名を持つ場合、分析結果カラム名が重複しないように指定してください。 以下のカラム名は指定できません。
また、以下のカラム名は予約語ですので、指定できません。
| - |
分析結果ビュー名 | out_view | varchar(63) | ○ | 分析対象テーブルに対して、分析結果テーブルを結合したビューを作成する場合は、任意のビュー名を指定します。 分析結果ビューを、BIツールで取得することにより、BIツール上で分析対象テーブルと分析結果テーブルを結合せずに、分析対象と分析結果をグラフなどで可視化できます。 省略した場合、分析結果ビューは作成されません。 なお、以下の点に注意してください。
| - |
分析対象テーブル名 | in_table | varchar(63) | × | 分析対象とするテーブル名を指定します。省略できません。 分析対象テーブルとして指定できるテーブルの詳細は、“6.2.1.3.6 分析対象テーブル”を確認してください。 | - |
ディメンションカラム名 | dimensions | ARRAY[varchar(63)] | ○ | ディメンションカラム名を配列で指定します。複数指定した場合は、重複したカラム名を指定できません。 以下のカラム名は指定できません。
また、以下のカラム名は予約語ですので、指定できません。
指定できるカラムの詳細は、“6.2.1.3.6 分析対象テーブル”を確認してください。 省略した場合、時間単位ごとの推移のみの分析結果になります。たとえば、グルーピングがない全店舗の売上げ推移のような分析結果になります。 | - |
メジャーカラム名 | measure | varchar(63) | × | 分析対象とするデータを格納したメジャーカラム名を指定します。省略できません。 指定できるカラムの詳細は、“6.2.1.3.6 分析対象テーブル”を確認してください。 | - |
日時カラム名 | time_col | varchar(63) | × | 日時カラム名を指定します。省略できません。 指定できるカラムの詳細は、“6.2.1.3.6 分析対象テーブル”を確認してください。 | - |
ターゲット区間 | target | varchar(16) | ○ | ずれを検出する範囲を指定します。 以下の範囲を指定できます。
| latest |
絞り込み条件 | cond_where | varchar(10000) | ○ | 分析対象テーブルに対する集計時のSELECT文のWHERE句への指定内容を、WHERE句を除いて10000文字以内の文字列で指定します。 なお、セミコロンおよび改行コードは含まないでください。 省略した場合は、分析対象テーブルに指定したデータ全てが、分析の対象になります。 WHERE句の詳細は、“PostgreSQL文書”の“WHERE句”を参照してください。 例) カラム名“store_name”に対して“川崎店”を検索する場合 "store_name"='川崎店' | - |
項目 | カラム名 | データ型 | 省略可否 (○:省略可、×:必須、-:設定不可) | 説明 | デフォルト値 |
|---|---|---|---|---|---|
日時集計単位 | time_field | varchar(16) | ○ | 集計の日時単位を指定します。 日時カラムのデータに対して、本カラムの設定値をdate_trunc関数のfieldに設定した実行結果ごとに集計します。 date_trunc関数の詳細は、“PostgreSQL文書”の“date_trunc”を参照してください。 日時カラムtime_colで指定したカラムのデータ型に対して、以下を指定することができます。
| timestampおよびdateの場合: day timeの場合:second |
集計方法 | aggr | varchar(16) | ○ | 実績値を計算するための集計方法を指定します。 以下を指定します。
| sum |
項目 | カラム名 | データ型 | 省略可否 (○:省略可、×:必須、-:設定不可) | 説明 | デフォルト値 |
|---|---|---|---|---|---|
アルゴリズム名 | algorithm | varchar(64) | ○ | ずれを検出するための拡張ライブラリを指定します。 以下の値を指定することができます。
拡張ライブラリの詳細は、“6.2.1.3.5 拡張ライブラリ”を参照してください。 | PgxaTsDetectOutlierUsingArima |
サンプル区間 | sample_size | integer | ○ | ずれを検出するために、対象の時間よりどれぐらい前の時間帯のデータを利用するかを指定します。 以下の範囲で指定してください。 1~65535 | 30 |
カスタマイズパラメーター | custom_params | ARRAY[varchar(128)] | ○ | 分析ファンクションで使用する拡張ライブラリのパラメーターをチューニングする場合に指定します。 パラメーターを配列で指定してください。 省略した場合のパラメーター値および拡張ライブラリのパラメーターの詳細は、“6.2.1.3.5 拡張ライブラリ”を参照してください。 | - |
追加パッケージ | ex_pkgs | ARRAY[varchar(64)] | ○ | ユーザー分析ライブラリで利用するRパッケージ名を配列で指定します。 | - |
多重度 | multi_proc | integer | ○ | 拡張ライブラリの分析処理を並列して実行することで、分析処理を高速で実行できます。 以下の範囲で指定してください。 1~16 なお、DWHサーバのCPU数以上の値を指定した場合、CPU数と同じ値が設定されたものとして動作します。 | 1 |
拡張ライブラリで設定できるアルゴリズムの内容およびチューニング可能なパラメーターについて説明します。パラメーターは、分析定義テーブルのカスタマイズパラメーターcustom_paramsに文字列の配列として設定します。
arima
対象の時点より過去のデータを用いて、対象の時点の予測値と実際の値がずれているかどうかが検出されます。
予測値は、ARIMA(自己回帰和分移動平均)モデルを使用して過去のデータの解析結果から算出されます。ARIMAは、時系列データが中長期的に増加・減少している場合にも、有効な予測結果が算出されます。
配列のインデックス | 項目 | 形式 | 説明 | デフォルト値 |
|---|---|---|---|---|
1 | 閾値 | 以下の形式で指定します。 形式) ±N.M
| 予測値と実際の値の差が、サンプル区間の値の平均値と比べて「指定の値×標準偏差」より大きいまたは小さい場合に、ずれとして検出します。 省略した場合、「3.0」を指定します。この値より小さい値を指定した場合、多くの箇所がずれとして検出されます。 | +3.0 |
2 | 閾値評価法 | 以下の文字列のどれかを指定します。
| 閾値と、算出された差との評価方法を指定します。 以下を指定してください。
| abs |
3~ | 予測モデルのカスタマイズパラメーター | 以下の形式で、文字列で指定します。 形式) (パラメーター名)=(設定値) | 予測モデル(ARIMA)のパラメーターをチューニングする際に指定します。 本パラメーターの詳細は、“予測モデルのカスタマイズパラメーターに指定する各パラメーターの詳細”を参照してください。 例: 以下は、パラメーター名stepwiseにFALSE、パラメーター名icに"bic"を指定する場合のカスタマイズパラメーターcustom_paramsの指定例です。 ARRAY['2.0','abs','stepwise=FALSE','ic="bic"'] | デフォルト値の詳細は、“予測モデルのカスタマイズパラメーターに指定する各パラメーターの詳細”を参照してください。 |
予測モデルのカスタマイズパラメーターに指定する各パラメーターの詳細
カスタマイズパラメーターのパラメーター名および設定値に指定可能な値は、R言語のパッケージであるforecast(オープンソース・ソフトウェア)が提供しているマニュアルのauto.arima関数の説明を参照してください。仮引数名の指定のないパラメーターは指定できません。
省略した場合は、以下の値が設定されます。
d=1
D=NA
max.p=2
max.q=2
max.P=2
max.Q=2
max.order=8
max.d=1
max.D=1
start.p=2
start.q=2
start.P=1
start.Q=1
stationary=FALSE
seasonal= FALSE
ic=c("aicc","aic", "bic")
stepwise=TRUE
trace=FALSE
approximation=(length([過去のデータ])>100 | frequency([過去のデータ])>12)
xreg=NULL
test=c("kpss","adf","pp")
seasonal.test=c("ocsb","ch")
allowdrift=TRUE
lambda=NULL
parallel=FALSE
num.cores=NULL
分析ファンクションで時系列データの分析を行うために、分析対象のデータ(メジャー)、分析の視点(ディメンション)、日時カラムを持つ単一のテーブル、およびビューを分析対象テーブルとして準備します。
なお、各カラム名は、63バイト以内で定義してください。
項目種別 | データ型 | 省略可否 | 説明 |
|---|---|---|---|
メジャー候補カラム | smallint integer bigint numeric real double precision | × | 分析の対象となる時系列データを格納するカラムです。 たとえば、“売上金額”、“単価”、“売上個数”というデータを分析対象にする場合は、メジャーとしてそれらのデータを格納するカラムを定義する必要があります。 分析定義のメジャーカラム名measureに指定するカラム名を変更することにより、分析対象となる時系列データを変更することができます。 |
ディメンション候補カラム | smallint integer bigint numeric real double precision character varying(n) varchar(n) charcter(n) char(n) date time timestamp | ○ | ディメンションを格納するカラムです。 たとえば、“店舗別”、“顧客年齢別”、“商品別”という視点で分析したい場合は、ディメンションとしてそれらのデータを格納するカラムを定義する必要があります。 分析定義のディメンションカラム名dimensionsに指定するカラム名の組み合わせを変更することにより、分析の視点を変更して分析を行うことができます。 省略した場合、時間単位ごとの推移のみの分析結果になります。たとえば、店舗別のグルーピングがない全店舗の売上げ推移のような分析結果になります。 |
日時カラム | date time timestamp | × | 日付/時刻を格納するカラムです。 |
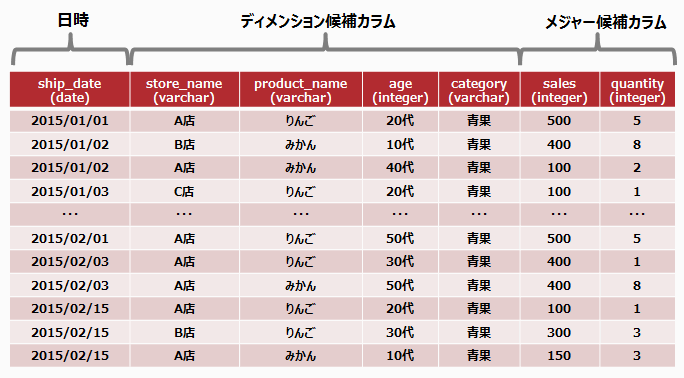
例
分析対象テーブル
売上げの履歴データを分析するために、分析対象(メジャー)、分析の視点(ディメンション)の分析対象テーブルを定義した場合の例を以下に示します。
日時カラム: ship_date
ディメンション候補カラム: store_name、product_name、age、category
メジャー候補カラム: sales、quantity
分析ファンクションを実行すると、分析定義テーブルで設定した日時カラムtime_col、ディメンションカラムdimensions、および分析結果カラムout_colに指定したカラムが格納された分析結果テーブルout_tableが作成されます。
すでに分析結果テーブルout_tableで指定したテーブルが存在しており、分析結果カラム名で指定したカラムが存在しない場合は、分析結果テーブルout_tableにその分析結果カラムが挿入されます。
以下の場合は、分析ファンクションの実行が異常終了します。
プライマリキー制約(日時カラムとディメンションカラムの組み合わせ)が表の定義と異なる場合
カラム名に対応するカラムのデータ型が表の定義と異なる場合
分析ファンクションの実行時に自動作成される分析結果テーブルの内容は、以下のとおりです。
項目種別 | 項目名 | データ型 | プライマリキー制約 | 説明 |
|---|---|---|---|---|
日時カラム | 以下の形式で格納されます。 形式) aggr_by_<分析定義テーブルの日時集計単位time_fieldで指定された値> | 分析定義テーブルの日時カラム名time_colに設定したカラムの日時データ型 | ○ | 日時カラムの値が、日時集計単位ごとに出力されます。 日時は、日時集計単位に指定した単位で出力され、日時カラムの値を切り捨てた値になります。 例1)date型に対して日時集計単位にmonthを指定した場合の例は、以下のとおりです。 2015-01-01 2015-02-01 2015-03-01 例2)time型に対して、日時集計単位にminuteを指定した場合の例は、以下のとおりです。 01:00:00.0000000 01:01:00.0000000 01:02:00.0000000 |
ディメンションカラム | 分析定義テーブルのディメンションカラム名dimensions | 分析定義テーブルのディメンションカラム名dimensionsに設定したカラムのデータ型 | ○ | ディメンションカラムの値が出力されます。 なお、分析定義テーブルのディメンションカラム名に複数指定した場合は、指定した数分のカラムが作成されます。 |
分析結果カラム | 分析定義テーブルの分析結果カラム名out_col | integer | 分析の結果が出力されます。 ずれとして検出された場合には“1”、ずれではないと検出された場合には"0”が出力されます。 |
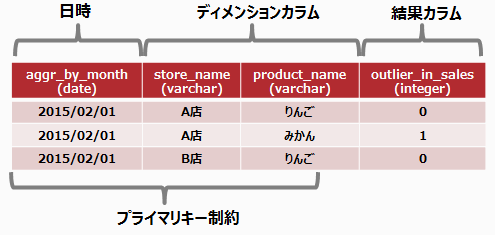
例
分析結果テーブル
“分析対象テーブル”のテーブルの例に対して、以下のように分析定義テーブルの各カラムを設定した場合の例を示します。
日時カラム名time_col: ship_date
日時集計単位time_filed: month(月)
ディメンションカラム名dimenstions: store_name、product_name
メジャーカラム名measure: sales
分析結果カラム名out_col: outlier_in_sales
注意
分析結果テーブルに対して、列の追加のようなテーブル構成の変更を行わないでください。変更した場合、分析結果ビューが正しく表示されなくなる場合があります。
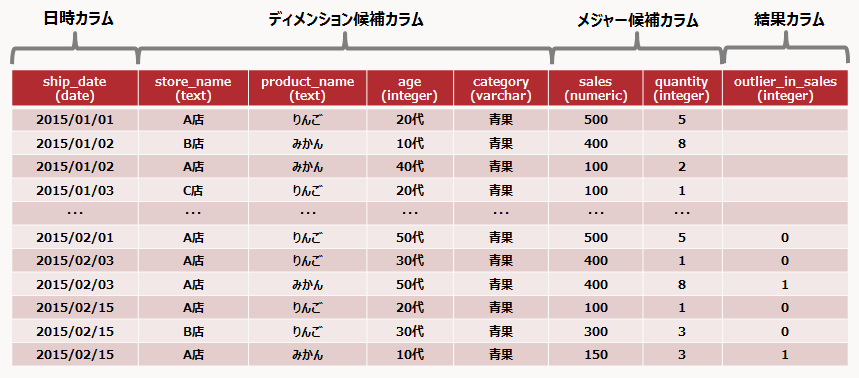
分析結果ビューは、分析対象テーブルおよび分析結果テーブルを結合したテーブルです。分析結果ビューをBIツールから参照することで、BIツール上で分析対象テーブルおよび分析結果テーブルを結合せずにすぐに分析ができます。
分析対象テーブルに対して、分析定義テーブルに指定した分析結果カラムが追加された分析結果ビューが作成されます。分析結果カラムには、分析結果テーブルの対応する行(同じディメンションの組み合わせ、同じ日時集計区間など)の値が格納されます。対応する行が存在しない場合には、NULLが格納されます。
例
分析結果ビュー
“分析対象テーブル”および“分析結果テーブル”のテーブルの例に対して、作成されるビューは以下の通りです。
以下の内容を分析定義テーブルに定義して実行する例について説明します。
分析対象テーブルin_table: sales_detail
分析結果テーブルout_table: detect_outlier
分析結果カラム名out_col: outlier_in_sales
分析結果ビューout_view: sales_detail_and_outlier
ディメンションカラム名dimensions: store_name、product_name
メジャーカラム名measure: sales
日時カラム名time_col: ship_date
日時集計単位time_field: month(月毎)
拡張ライブラリ名: algorithm: PgxaTsDetectOutlierUsingArima (予測値からのずれの検知)
以下の手順で行います。
分析対象テーブルの確認
分析対象テーブルを確認します。
postgres=# select * from sales_detail limit 1; order_id | region | state | location | store_id | store_name | ship_date | department_category | department | category | product_name | quantity | sales | hours | gender | age ----------+--------+--------+----------+----------+------------+------------+---------------------+------------+----------+--------------+----------+ -------+-------+--------+----- 100010 | 関東 | 東京 | 705287 | 10101 | 蒲田 | 2015-03-01 | 青果 | 果物 | 柑橘 | みかん | 1 | 88 | 1 | 男性 | 10 (1 row)
分析定義の追加
分析定義を追加するために、INSERT文を実行します。
以下の例では、分析定義識別子“10”が作成されています。
postgres=# INSERT INTO pgxa_def_anls_ts_detect_outlier (in_table , out_table, out_col, out_view, dimensions, measure, time_col, time_field, algorithm) VALUES ('sales_detail', 'detect_outlier', 'outlier_in_sales', 'sales_detail_and_outlier', ARRAY['store_name', 'product_name'], 'sales', 'ship_date', 'month', 'PgxaTsDetectOutlierUsingArima') RETURNING id;
id
----
10
(1 row)
INSERT 0 1分析の実行
手順2で追加した分析定義の分析定義識別子“10”を指定して実行します。
postgres=# SELECT pgxa_anls_ts_detect_outlier(10); pgxa_anls_ts_detect_outlier ----------------------------- t (1 row)
分析結果の表示
分析結果を表示します。
postgres=# select * from detect_outlier limit 5; aggr_by_month | store_name | product_name | outlier_in_sales ---------------+------------+--------------+------------------ 2015-04-30 | 横浜 | カンロ | 0 2015-04-30 | 横浜 | ロース | 0 2015-04-30 | 横浜 | かじか | 0 2015-04-30 | 横浜 | 炭酸水 | 0 2015-04-30 | 横浜 | 青梨 | 0 (5 rows)
ずれの検知を行う分析ライブラリのインターフェースについて説明します。ユーザー分析ライブラリを作成する場合は、以下で説明するインターフェースを持つR言語の関数としてください。
ユーザー分析ライブラリの例
MyTsDetectOutlier <-
function(target = NULL, samples = NULL, custom.params = NULL) {
# 直前の時間帯(例:前日)からの差の割合が
# 閾値を超えた箇所(ずれ)を検出します。
#
# Args:
# target: 判定する時間帯の実績値
# samples: 直前を含む時間帯の実績値
# custom.params: カスタマイズパラメーター
# (2個以上指定した場合は異常終了)
#
# Retuns:
# 判定結果を含むリストを返します。
# 1列目: 判定結果(0/1)
# 2列目: 直前の時間帯の実績値 [デバック用]
# 3列目: 判定する時間帯の実績値 [デバック用]
# 4列目: 差の割合 [デバック用]
# 5列目: 差 [デバック用]
# カスタマイズパラメーターの判定
if( 1 < length(custom.params)) {
stop("Invalid Custom Param")
}
# 差の計算
threashold <- -0.2
if ( 0 < length(custom.params)) {
i.th <- custom.params[[1]]
if (! is.null(i.th) && ! is.na(i.th)) {
threashold <- custom.params[[1]]
}
}
dif <- 0
predicted <- samples[nrow(samples),2] # 前日の実績値
actual <- target[,2] # 実績値
dif <- actual - predicted # 前日との差
sigma <- samples[nrow(samples),2]
difrate <- dif / sigma # 差の割合
# 閾値を超えているかどうか判定
ret <- NULL
if (difrate < threashold) {
# ずれの場合
ret <- list(1, predicted, actual, difrate, dif)
} else {
# ずれではない場合
ret <- list(0, predicted, actual, difrate, dif)
}
return (ret)
}function(target = NULL, samples = NULL, custom.params = NULL)
target
ずれを検知する時間帯の日時(*1)と集計された実績値が格納された1行2列の行列が設定されます。1列目に日時(character型)、2列目に実績値(double型)が格納されます。
sample
ずれを検知する時間帯からサンプル区間の数(N)分の過去の時間帯の日時(*1)と、集計された実績値が格納された、N行2列の行列が設定されます。1列目に日時(character型)、2列目に実績値(double型)が格納されます。
custom.params
分析定義テーブルのカスタマイズパラメーターに設定した値が、chracter型のリストとして設定されます。
カスタマイズパラメーターが省略された場合、空(長さ0)のリストが設定されます。
参考
*1:日時は、以下の形式で設定されます。
日時カラムがtimestampまたはdate型の場合
%Y-%m-%d %H:%M:%S
日時カラムがtime型の場合
%H:%M:%S
また、これらの形式の各要素の詳細は、以下のとおりです。
%Y: 年(4桁表示の西暦)
%m: 月(01-12)
%d: 日(01-31)
%H: 時(00-23)
%M: 分(00-59)
%S: 秒(00-61)
ずれの検知の判定結果を含めて、以下の値を設定した5つの要素を持つリストを返却します。
1列目(integer型): 判定結果
ずれであると判定された場合は1、ずれでないと判定された場合は0を設定します。
2列目(double型): 任意のデバック情報
3列目(double型): 任意のデバック情報
4列目(double型): 任意のデバック情報
5列目(double型): 任意のデバック情報
参考
client_min_messagesパラメーターの値にLOG以下を設定することで、分析ファンクションのデバック情報がアプリケーションに返却されます。
client_min_messagesパラメーターの詳細は、“PostgreSQL文書”の“サーバの設定”を参照してください。
例
カンマ(,)区切りの後ろから5番目までの値が、出力パラメーターの判定結果およびデバック情報として設定した値です。なお、設定した順に出力されます。
NOTICE: RET(AnlsFunc): 1,2015-05-01 00:00:00,1,200,140,-0.3,-60
stop関数の実行やR言語の関数の実行でエラーが発生して、作成したユーザー分析ライブラリがエラーで停止した場合、分析ファンクションは異常終了します。