Purpose
When you build a cluster system using PRIMECLUSTER, you need to confirm before starting production operations that the entire system will operate normally and cluster applications will continue to run in the event of failures.
For 1:1 standby operation, the PRIMECLUSTER system takes an operation mode like the one shown in the figure below.
The PRIMECLUSTER system switches to different operation modes according to the state transitions shown in the figure below. To check that the system operates normally, you must test all operation modes and each state transition that switches to an operation mode.
Figure 1.3 State transitions of the PRIMECLUSTER system
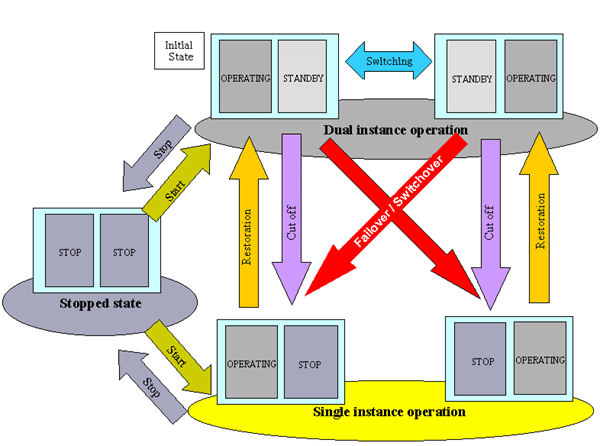
PRIMECLUSTER System State
Description | |
|---|---|
Dual instance operation | A cluster application is running, and it can switch to the other instance in the event of a failure (failover). Two types of the dual instance operation are OPERATING and STANDBY. Even if an error occurs while the system is operating, the standby system takes over ongoing operations as an operating system. This operation ensures the availability of the cluster application even after failover. |
Single instance operation | A cluster application is running, but failover is disabled. Two types of the single instance operation are OPERATING and STOP. Since the standby system is not supported in this operation, a cluster application cannot switch to other instance in the event of a failure. So, ongoing operations are disrupted. |
Stopped state | A cluster application is stopped. |
The above-mentioned "OPERATING", "STANDBY", and "STOP" are defined by the state of RMS and cluster application as follows;
RMS state | Cluster application state | Remark | |
|---|---|---|---|
OPERATING | Operating | Online | - |
STANDBY | Operating | Offline or Standby | - |
STOP | Stopped | Unknown * | SysNode is Offline |
* RMS determines the cluster application state. When RMS is stopped, the cluster application state is unknown.
Main tests for PRIMECLUSTER system operation
Conduct a startup test and confirm the following:
View the Cluster Admin screen of Web-Based Admin View, and check that the cluster system starts as designed when the startup operation is executed.
If an RMS configuration script was created, check that the commands written in the script are executed properly as follows.
For a command that outputs a message when it is executed, check that a message indicating that the command was executed properly is displayed on the console.
Check that the command has been executed properly by executing the "ps(1)" command.
A new cluster application is not started automatically during the PRIMECLUSTER system startup. To start the cluster application automatically, you must set "AutoStartUp" for that cluster application. The AutoStartUp setting must be specified as a userApplication attribute when the application is created. For details, see "6.7.2 Creating Cluster Applications."
If a failure occurs in a cluster application, the state of that application changes to Faulted.
To build and run this application in a cluster system again, you need to execute "Clear Fault" and clear the Faulted state.
Conduct a clear-fault test and confirm the following:
Check that the Faulted state of a failed application can be cleared without disrupting ongoing operations.
If an RMS configuration script was created, check that the commands written in the script are executed properly as follows.
For a command that outputs a message when it is executed, check that a message indicating that the command was executed properly is displayed on the console.
Check that the command has been executed properly by executing the "ps(1)" command.
Conduct a failover or switchover test and confirm the following:
Check that failover is triggered by the following event:
When an application failure occurs
Check that switchover is triggered by the following events:
When the OPERATING node is shut down
When an application is terminated by the exit operation
When an OPERATING cluster application is stopped
Check that failover or switchover is normally done for the following:
Disk switchover
Check that the disk can be accessed from the OPERATING node.
For a switchover disk, you need to check whether a file system is mounted on the disk by executing the "df(1M)" command.
If the Cmdline resources are to be used, check that the commands written in the Start and Stop scripts for the Cmdline resources are executed properly.
For a command that outputs a message when it is executed, check that a message indicating that the command was executed properly is displayed on the console.
Check that the command has been executed properly by executing the "ps(1)" command.
If IP address takeover is set, check that the process takes place normally by executing the "ifconfig(1M)" command.
If MAC address takeover is set, check that the process takes place normally by executing the "ifconfig(1M)" command.
If node name takeover is set, check that both the OPERATING and STANDBY nodes have the same node name after network takeover.
If a line switching unit is set up, check that line switching takes place correctly.
Check that an application is switched to other node.
You need to know the operation downtime in the event of a failure, so measure the switching time for each failure detection cause and check the recovery time.
Conduct a replacement and confirm the following:
Check that the OPERATING and STANDBY instances of the OPERATING business application occur normally when the cluster application replacement is executed. Check the following:
If disk switchover is to be used, check that the disk can be accessed from the OPERATING node but not from the STANDBY node.
For a switchover disk, you need to check whether a file system is mounted on the disk by executing the "df(1M)" command.
If Cmdline resources are to be used, check that the commands written in the Start and Stop scripts for the Cmdline resources are executed properly.
For a command that outputs a message when it is executed, check that a message indicating that the command was executed properly is displayed on the console.
Check that the command has been executed properly by executing the "ps(1)" command.
If IP address takeover is to be used, check that IP address takeover takes place normally.
Check that an application is switched to other node.
Conduct a stop test and confirm the following:
Check that an OPERATING work process can be stopped normally by the stop operation.
Check that work processes can be started by restarting all nodes simultaneously.
If Cmdline resources are to be used, check that the commands written in the Start and Stop scripts for the Cmdline resources are executed properly.
For a command that outputs a message when it is executed, check that a message indicating that the command was executed properly is displayed on the console.
Check that the command has been executed properly by executing the "ps(1)" command.
Conduct work process continuity and confirm the following:
Generating some state transitions in a cluster system, check that the application operates normally without triggering inconsistencies in the application data in the event of a failure.
For systems in which work processes are built as server/client systems, check that while a state transition is generated in the cluster system, work process services can continue to be used by clients, according to the specifications.
Please check that the shutdown facility's settings are properly functioning.
With a view to the following, please conduct a test of whether or not there has once been a stop to the cluster nodes of which the cluster is comprised
Check that the cluster nodes which are undergoing an error or are causing an OS error have undergone a forced stop.
Check that the cluster interconnect has been disconnected and that the low-priority cluster nodes have undergone a forced stop.
Note
So as to detect an NIC linkdown event on both paths, please disconnect the cluster interconnect.
For example, if the both nodes are connected through a switch instead of being connected directly, please disconnect the two cluster interconnects from the same node side. If you perform a method of disconnection that does not allow for the detection of an NIC linkdown event on both paths, there will be time differences in detecting an error for each route and the node that detected the error first will have priority and stop peer node forcibly.
Also, please check that the crash dump for the cluster nodes that underwent forced stop has been collected.
See
For information on the operation procedures for start, clear fault, failover, switchover, and stop, see "7.2 Operating the PRIMECLUSTER System".
For descriptions of IP address takeover and node name takeover, see "6.7.1.5 Creating Takeover Network Resources".