本製品を導入したシステムを起動する際には、以下の順序で作業を行ってください。
図8.1 本製品を導入したシステムの起動の流れ
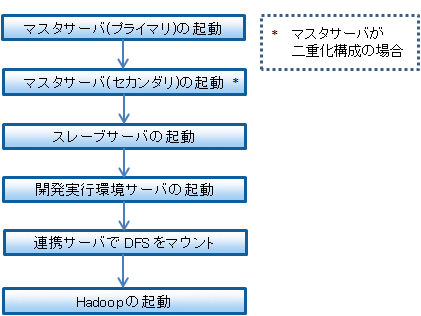
DFS をマウントする際は、必ず DFS 管理サーバ、DFS クライアントの順で行う必要があります。
そのため、DFS 管理サーバであるマスタサーバの起動から行います。マスタサーバを二重化構成で運用している場合は、マスタサーバ(プライマリ)、マスタサーバ(セカンダリ)の順でサーバの起動を行ってください。
マスタサーバの起動が完了したあとに、DFS クライアントであるスレーブサーバ、開発実行環境サーバ、連携サーバの起動を行います。
既存の業務システムを運用しているなど既に連携サーバが起動している場合、連携サーバでは DFS のマウントのみ行います。
注意
マスタサーバが二重化構成の場合、マスタサーバ(プライマリ)とマスタサーバ(セカンダリ)の両方で DFS 管理サーバが起動するまで、システムの起動が完了しません。
そのため、マスタサーバ(プライマリ)のシステム起動の完了を待たずに、マスタサーバ(セカンダリ)のシステムを起動してください。
サーバ起動時に DFS のマウントが自動的に行われない設定となっている場合は、サーバの起動後に手動で DFS のマウントを行ってください。
すべてのサーバで DFS のマウントが完了したあと、Hadoop の起動を行います。
本製品の Hadoop は、マスタサーバで bdpp_start コマンド を実行することで起動することができます。
bdpp_start コマンドの詳細については、「A.14 bdpp_start」を参照してください。
Hadoop の起動を行うと、次に示すプロセスが起動されます。
マスタサーバ
JobTracker(Hadoop)
スレーブサーバ
TaskTracker(Hadoop)
注意
マスタサーバ上の Apache Hadoop の "JobTracker" を直接、起動することはできません。本製品の Hadoop を起動する場合は必ず、bdpp_start コマンド を使用してください。
Apache Hadoop の利用方法については、「Hadoop プロジェクトトップページ http://hadoop.apache.org/」を参照してください。
参考
DFS の自動マウントを行うかどうかの設定は、/etc/fstab で行います。DFS のマウントオプションが以下の場合に、自動マウントが行われます。
マスタサーバの場合: noatrc オプションが指定されていない
それ以外のサーバの場合: noauto オプションが指定されていない