■概要
クラスタシステムを構成するノードの1つに異常が発生しクラスタシステム間のハートビートが失敗した場合、PRIMECLUSTERシャットダウン機構は異常が発生したノードの電源を強制的に切断します。
ハートビートの失敗要因がパニックであった場合、クラッシュダンプ採取中に強制電源切断すると、クラッシュダンプ採取が途中で終了してしまうため、異常原因を調査する上で必要な資料が採取できなくなる場合があります。
クラスタ高速切替機能は、上記の問題を防止するためにクラッシュダンプ採取中の強制電源切断を抑止し、同時に異常発生ノードのクラッシュダンプ採取中のフェイルオーバを実現する機能です。
■kdump
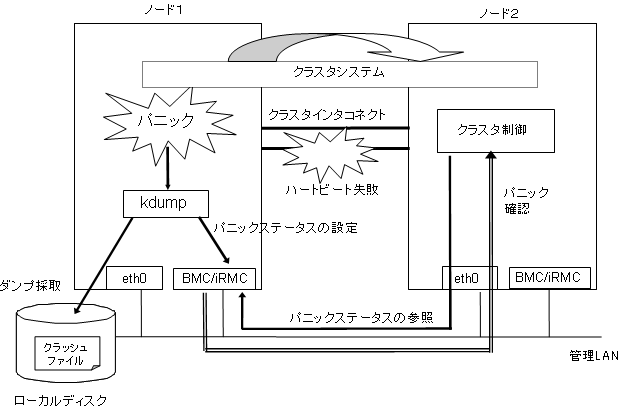
上図に示すように、ハートビート失敗時にクラスタ高速切替機能は BMC(Baseboard Management Controller) または iRMCを利用してパニックステータスを設定/参照します。これにより、ハートビート異常を検出したノードは、クラッシュダンプ中のノードの強制電源切断をすることなくこれを停止状態とみなし、業務を引き継ぐことが可能となります。
注意
クラッシュダンプ採取中にパニックしたノードをリセットすると、クラッシュダンプ採取が正しく行われません。クラッシュダンプ採取中はリセット操作をしないでください。
パニックしたノードのクラッシュダンプ採取後の動作はkdumpの設定に従います。
◆kdumpシャットダウンエージェントに必要な設定
kdumpの設定
kdumpを使用する場合は、事前にkdumpの設定を行う必要があります。
kdumpの確認
kdumpサーバ機能が利用可能となっていることを確認してください。利用可能となっていない場合は、利用可能にしてください。
確認操作はrunlevel(8)コマンドとchkconfig(8)コマンドで行います。
runlevel(8)コマンドで、現在のランレベルを確認します。
例) 以下の場合、現在のランレベルは3です。
# /sbin/runlevelN 3
chkconfig(8)コマンドで、kdumpの利用可能状態を確認します。
例) 以下の場合、現在のランレベル3のkdumpはオフです。
# /sbin/chkconfig --list kdumpkdump 0:オフ 1:オフ 2:オフ 3:オフ 4:オフ 5:オフ 6:オフ
現在のランレベルでkdumpがオフになっている場合、chkconfig(8)コマンドでオンにし、service コマンドで kdumpを起動してください。
# /sbin/chkconfig kdump on # /sbin/service kdump start■その他シャットダウンエージェントに必要な設定
kdumpシャットダウンエージェントの設定が完了したら、IPMI(Inteligent Platform Management Interface)、あるいはブレードサーバの設定を行ってください。
参考
IPMIシャットダウンエージェントは、BMCあるいはiRMCが搭載されているハードウェア装置で使用するシャットダウンエージェントです。
◆IPMIシャットダウンエージェントに必要な設定
IPMIのユーザ設定を行ってください。
ユーザID
パスワード
IPアドレス
詳細は、各機種ごとの“ユーザーズガイド”、およびServerView Operations Manager のマニュアルを参照してください。
◆Bladeシャットダウンエージェントに必要な設定
ブレードサーバの設定を行ってください。
ServerViewのインストール
SNMPコミュニティ
マネージメントブレードのIPアドレス
詳細は、ServerView Operations Manager のマニュアル、および 装置添付の各種ハードウェアガイドを参照してください。
PRIMEQUESTでクラスタシステムを構成するノードの1つに異常が発生した場合、PRIMECLUSTERシャットダウン機構は以下の2つの方法によってその異常を検出します。詳細については“PRIMECLUSTER コンセプトガイド”の“3.3.1.7 PRIMECLUSTER SF”を参照してください。
(1) MMBを通じてのノードの状態変化(非同期監視)
(2) クラスタノード間のハートビート(NSM:ノード状態モニタ)の失敗 (定周期監視)
(1)の非同期監視はノードの異常を即時に検出することができ、(2)の定周期監視で検出するよりもフェイルオーバが高速となります。
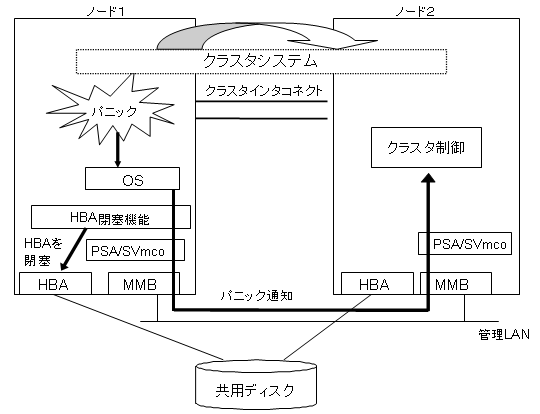
上図に示すように、パニック発生時にクラスタ制御はMMBによりパニック通知を受けます。これにより、ハートビート異常よりも早くノードのパニックを検出します。
参照
PRIMEQUESTでは、ダンプ環境を設定することにより、パニック時にクラッシュダンプを採取することができます。
PRIMEQUESTのダンプ機能、設定方法、および、確認方法については、以下のマニュアルを参照してください。
PRIMEQUEST 1000 シリーズ 導入マニュアル
PRIMEQUEST 1000 シリーズ ServerView Mission Critical Option ユーザマニュアル
(1)の非同期監視を利用するためには、MMBを制御するソフトウェアのインストールやドライバの適切な設定が必要です。本節では高速切替を実現するために必要なMMBを制御するソフトウェアのインストールやドライバの設定を説明します。
HBA閉塞機能とPSA/SVmcoのインストール
MMBを通じてのノードの状態変化はHBA閉塞機能とPSA/SVmcoによりシャットダウン機構に通知されます。シャットダウン機構の設定を行う前にHBA閉塞機能とPSA/SVmcoのインストールを行ってください。インストール方法については、以下のマニュアルを参照してください。
PRIMEQUEST 1000 シリーズ HBA閉塞機能説明書
PRIMEQUEST 1000 シリーズ 導入マニュアル
PRIMEQUEST 1000 シリーズ ServerView Mission Critical Option ユーザマニュアル
PSA/SVmcoおよびMMBの設定
MMBを通じてのノードの状態変化を正しくシャットダウン機構に通知させるためには、PSA/SVmcoおよびMMBの設定が必要です。シャットダウン機構の設定を行う前にPSA/SVmcoの設定を行ってください。設定方法については、以下のマニュアルを参照してください。
PRIMEQUEST 1000 シリーズ 導入マニュアル
PRIMEQUEST 1000 シリーズ ServerView Mission Critical Option ユーザマニュアル
また、PRIMECLUSTERがMMBと連携するために、RMCPのユーザを作成する必要があります。PRIMECLUSTERを構成するすべてのPRIMEQUEST上にRMCPでMMBを制御するためのユーザを必ず作成してください。RMCPでMMBを制御するためのユーザを作成するには、MMB Web-UIにログインし、“Network Configuration”メニューの“Remote Server Management”画面から作成します。その際、以下のようなユーザを作成してください。
[Privilege]は「Admin」とする
[Status]は「Enabled」とする
RMCPでMMBを制御するためのユーザの作成方法について詳しくは、本体装置添付の“PRIMEQUEST 1000 シリーズ 運用管理ツールリファレンス”を参照してください。
ここで作成したユーザ名と設定したパスワードはシャットダウン機構の設定の際に使用します。メモしてください。
注意
MMBには以下の2種類のユーザが存在します。
MMB全体を制御するためのユーザ
RMCPでMMBを制御するためのユーザ
ここで作成するユーザはRMCPでMMBを制御するためのユーザです。誤らないようにしてください。
HBA閉塞機能の設定
注意
共用ディスクを使用する場合は、本設定を必ず行ってください。
パニックが発生した場合に共用ディスクに接続しているHBAを閉塞させ、共用ディスクへのI/O処理を打ち切ります。こうすることで、共用ディスク内のデータの整合性を保ちつつ、高速に切り替えることができます。
全ノードで、共用ディスクのデバイスパス(GDSを使用している場合はGDSのデバイスパス)をHBA閉塞機能用コマンドに指定し、HBAの機能停止を行う対象として共用ディスクを追加してください。本設定は、GDSを使用している場合はGDSの設定完了後に行ってください。設定方法については、 “PRIMEQUEST 1000 シリーズ HBA閉塞機能説明書”を参照してください。
I/O完了待ち時間の設定
パニックなどのノードダウンが発生しフェイルオーバする場合、共用ディスクへのI/Oの整合性を保つため、ノードダウンが発生してから新運用ノードが運用を開始するまでに、一定のI/O完了待ち時間が必要な共用ディスク装置があります。
I/O完了待ち時間の初期値として0秒を設定していますが、I/O完了待ち時間が必要な共用ディスク装置を使用している場合、この値を適切な値に設定してください。
参考
ETERNUS ディスクアレイの場合、I/O完了待ち時間は不要ですので、本設定を行う必要はありません。
本設定はCFの設定完了後に行ってください。設定方法については、“I/O完了待ち時間の設定”を参照してください。
注意
I/O完了待ち時間を設定した場合、パニックなどのノードダウン時の切替え時間がその時間分増加します。