The following figure shows the troubleshooting flow when a hardware or similar fault occurs.
Figure 12.3 Troubleshooting Flow (When Fault Occurs During Replication)
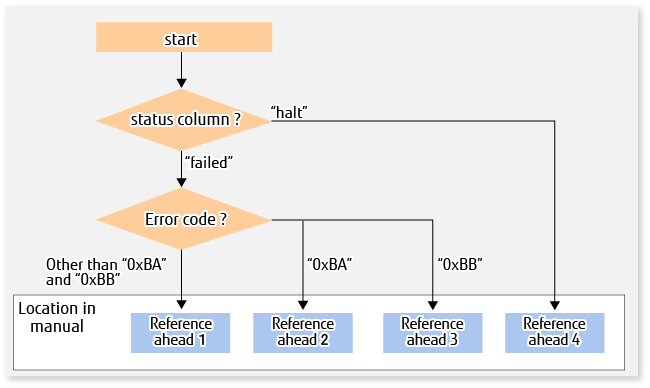
Reference ahead 1: 12.4.2.1 Hardware Error on Replication Volume
Reference ahead 2: 12.4.2.2 Troubleshooting If Bad Sector Occurred in Copy Source Volume
Reference ahead 3: 12.4.2.3 Troubleshooting When Lack of Free Space Has Occurred in Snap Data Volume or Snap Data Pool
Reference ahead 4: 12.4.2.4 Error (halt) on Remote Copy Processing
Note
Refer to "12.4.1 Overview" for details of the Status column and "Fault location".
If the Status column is "?????", check if the copy processing is in the error suspend status ("failed") or the hardware suspend status ("halt") using ETERNUS Web GUI.
If the copy processing is in either of these states, take the action indicated in the above troubleshooting flow.
In other cases, take the action checked in the following points.
If device information is unusual:
Restore the device information.
If a device is not accessible:
Check if the device exists.
If no dependency is configured between volumes and AdvancedCopy Manager service:
Configure the dependency. For details, refer to "14.1.5 Notes on Cluster Operation".
If there is anything unusual with Managed Server, switches, etc.:
Contact Fujitsu Technical Support.
Use ETERNUS Web GUI to check the error codes. Use the following two methods to check.
Checking with the swsrpstat command
Execute the command with the -O option.
Checking with ETERNUS Web GUI
On the [Display status] menu, click [Advanced Copy status display] in the status display.
At "Session status", click the "Number of active sessions" link for the relevant copy type.
Refer to the value in the "Error code" column of the relevant copy process.
The following table shows the meanings of the error codes.
Error Code | Meaning |
|---|---|
0xBA | If a) or b) below applies, a bad sector was created in the transaction volume.
|
0xBB | A lack of free space has occurred in the Snap Data Volume or Snap Data Pool. |
Other than 0xBA and 0xBB | An error other than the above occurred. |
When a hardware error occurs in a duplicate volume, perform the repair work on the error according to the following procedures.
Execute the swsrpcancel command to cancel the processing in which the error occurred. If the processing cannot be cancelled from the operation server when inter-server replication is performed, cancel it from a non-operational server.
If the processing cannot be cancelled by using the command, use ETERNUS Web GUI to cancel it.
Execute the swsrprecoverres command.
Execute the swsrpstat command to verify that no other errors have occurred.
Execute the swsrpdelvol command to delete the replication volume in which the error occurred.
Execute the swsrpsetvol command to register a new replication volume. If the replication volume on which the error occurred is to be repaired and be reused and if the device information has been modified, perform the following actions:
When AdvancedCopy Manager is being operated using the Web Console, refer to "Add/Reload Device" in the ETERNUS SF Web Console Guide to reload the configuration and re-register the replication volume.
When AdvancedCopy Manager is being operated using only Command Line Interface, execute the stgxfwcmsetdev command on the Management Server to reload the configuration and re-register the replication volume.
Re-execute the processing in which the error occurred.
If a bad sector occurred in the copy source volume, use the following procedure to restore the copy source volume:
Execute the swsrpcancel command to cancel processing for which the error occurred.
If inter-server replication was being performed and cancellation is not possible from the active server, cancel processing from the inactive server.
If processing cannot be cancelled using commands, use ETERNUS Web GUI to cancel it.
Execute the swsrpstat command to check for other errors.
Restoration is performed by overwriting the area containing the bad sector. Select the appropriate method, in accordance with the usage or use status of the copy source volume, from the methods below.
Restoration method 1:
If the area can be reconstructed from high-level software (file system, DBMS, or similar), reconstruct the area.
Restoration method 2:
If the area containing the bad sector is an area that is not being used, such as an unused area or a temporary area, use a system command (for example, the UNIX dd command or the Windows format command) to write to the area.
Restoration method 3:
Execute the swsrpmake command to restore the data from the copy destination volume. (Restoration is also possible from the copy destination volume of the copy process for which the bad sector occurred.)
A Snap Data Volume lack of free space occurs when the Snap Data Pool is not being used, whereas a Snap Data Pool lack of free space occurs when the Snap Data Pool is being used.
If a lack of free space occurs of Snap Data Volume or Snap Data Pool, refer to the following sections to recover it according to the Snap Data Pool usage condition:
When not using the Snap Data Pool : "Recovery of Insufficient Free Space in Snap Data Volume"
When using the Snap Data Pool : "Recovery of Insufficient Free Space in Snap Data Pool"
Point
The use status of the Snap Data Pool can be checked by specifying "poolstat" subcommand in the swstsdv command.
Recovery of Insufficient Free Space in Snap Data Volume
When a lack of free space has occurred in the Snap Data Volume, follow these steps to undertake recovery:
Cancel the processing in which the error occurred with the swsrpcancel command.
If inter-server replication was being performed and cancellation is not possible from the active server, cancel processing from the inactive server.
If processing cannot be cancelled using commands, use ETERNUS Web GUI to cancel it.
The likely causes of a lack of free space in the Snap Data Volume are as follows:
The estimate of the physical size of the Snap Data Volume is not accurate.
The estimate of the physical size of the Snap Data Volume is accurate but, as a result of a large volume being updated in the Snap Data Volume when the SnapOPC/SnapOPC+ session does not exist, the physical capacity of the Snap Data Volume is being used up.
The usage status of the Snap Data Volume can be checked by specifying "stat" subcommand in the swstsdv command.
If "a." applies, re-estimate the physical size of the Snap Data Volume, and recreate the Snap Data Volume.
If "b." applies, use ETERNUS Web GUI or, specify "init" subcommand in the swstsdv command, and then initialize the Snap Data Volume.
Recreation of the partition (slice) is required after recreation/initialization of the Snap Data Volume.
Recovery of Insufficient Free Space in Snap Data Pool
When a lack of free space has occurred in the Snap Data Pool, follow these steps to undertake recovery:
Cancel the processing in which the error occurred with the swsrpcancel command.
If inter-server replication was being performed and cancellation is not possible from the active server, cancel processing from the inactive server.
If processing cannot be cancelled using commands, use ETERNUS Web GUI to cancel it.
The likely causes of a lack of free space in the Snap Data Pool are as follows:
The estimate of the size of the Snap Data Pool is not accurate.
The estimate of the size of the Snap Data Pool is accurate but, as a result of a large volume being updated in the Snap Data Volume when the SnapOPC/SnapOPC+ session does not exist, the capacity of the Snap Data Pool is being used up.
The use status of the Snap Data Pool can be checked by specifying "poolstat" subcommand in the swstsdv command.
If "a." applies, re-estimate the size of the Snap Data Pool, and after increasing the size of the Snap Data Pool, recreate the Snap Data Volume.
If "b." applies, use ETERNUS Web GUI or, specify "init" subcommand in the swstsdv command, then initialize the Snap Data Volume.
Recreation of the partition (slice) is required after recreation/initialization of the Snap Data Pool.
The REC restart (Resume) method varies, depending on the halt status.
Execute the swsrpstat command with the -H option specified to check the halt status, and then implement the relevant countermeasure.
For "halt(use-disk-buffer)" or "halt(use-buffer)"
This status means that data is saved to the REC Disk buffer or REC buffer because data cannot be transferred due to a path closure (halt).
In order to restart REC, perform path recovery before a space shortage occurs for the REC Disk buffer or REC buffer.
After recovery, the ETERNUS Disk storage system restarts REC automatically.
If a space shortage has already occurred for the REC Disk buffer or REC buffer, the "halt(sync) or halt (equivalent)" status shown below occurs. Implement the countermeasures for that status.
For "halt(sync) or halt(equivalent)"
This status means that data transfer processing was discontinued due to a path closure (halt).
The REC restart method differs for different REC Recovery modes.
Remove the cause that made all paths close (halt).
ETERNUS Disk storage system automatically restarts (Resume) REC.
Remove the cause that made all paths close (halt).
Execute the swsrpmake command to forcibly suspend the REC that is in the halt status.
[For volume units] swsrpmake -j < replication source volume name > <replication destination volume name > [For group units] swsrpmake -j -Xgroup <group name> |
Execute the swsrpstartsync command to restart (Resume) the REC. The -t option must be specified if REC is being restarted after a forcible suspend.
[For volume units] swsrpstartsync -t <replication source volume name > <replication destination volume name > [For group units] swsrpstartsync -t -Xgroup <group name> |