When the userApplication starts up, the takeover virtual interface (sha0:65) becomes active on the operating node, allows to hold communication using the takeover virtual IP address.
During normal operation, userApplication communicates with the remote system using the virtual interface on the operating node.
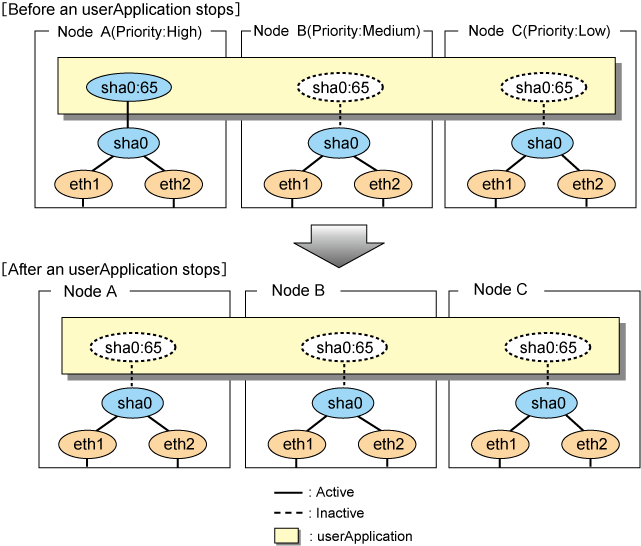
After the redundant control function start-up, the virtual interface is activated. Once it has been activated, regardless of the cluster system shutdown or restart, it stays to be active until the system shuts down.
Figure 5.28 Start-up behavior of Fast switching mode illustrates start-up behavior of Fast switching mode
Figure 5.28 Start-up behavior of Fast switching mode
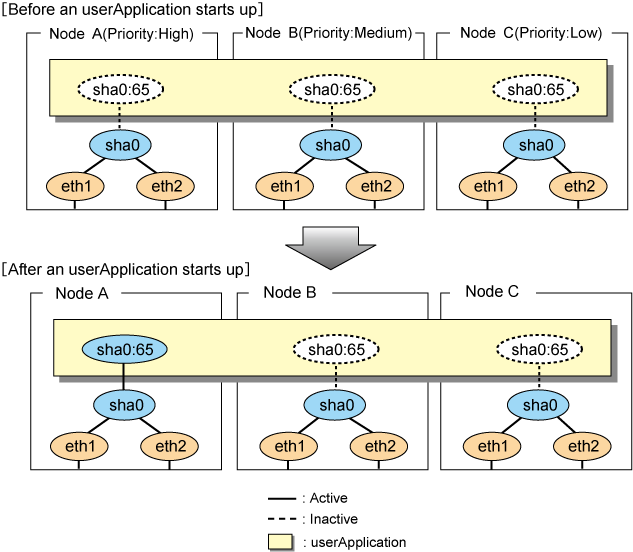
During normal operation, userApplication communicates with the remote system using the takeover virtual interface on the operating node.
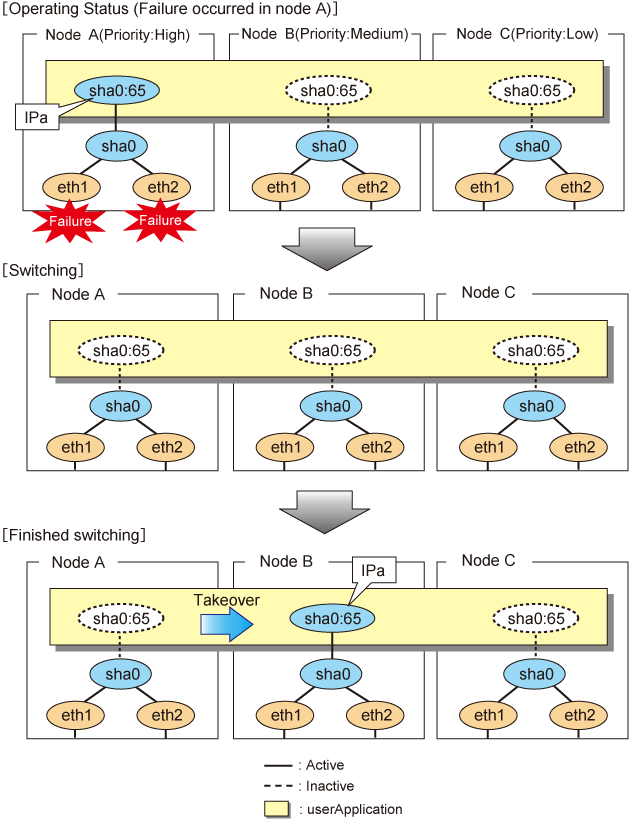
When a failure (panic, hang, detecting failure in transfer route) occurs in the operating node, redundant control function allows switching to the standby node, which has a higher priority within a several other standby nodes. It inherits the communication of operating node by reconnecting to the node using the application.
Figure 5.29 Switching operation of Fast switching mode illustrates switching behavior of Fast switching mode.
In the following figure, the takeover IP address (IPa) is allocated to the takeover virtual interface (sha0:65) for operating node A. Then it activates the takeover virtual interface. When switching the interface due to failures in the transfer path, the takeover virtual interface (sha0:65) for operating node A becomes inactive. Then in standby node B, the takeover virtual interface (sha0:65), which has allocated the takeover IP address (IPa) becomes active. Note that the virtual interface (sha0) in node A stays unchanged.
Figure 5.29 Switching operation of Fast switching mode
The following is a fail-back procedure, describing how to recover from the cluster switching.
1) Recovering the node, which encountered a failure
If switching was caused by panic or hang up, then reboot the node.
On the other hand, if switching was caused by a transfer path failure, then recover the transfer path encountered a failure. (Recovering options are reconnecting the cable, restore the power of HUB, and exchange the broken HUB.)
2) Fail-back to an arbitrary node on standby
Fail-back the userApplication to an arbitrary node on standby using "Cluster Admin" of Web-Based Admin View.
Figure 5.30 Stopping operation of Fast switching mode illustrates stopping operation of a userApplication
Figure 5.30 Stopping operation of Fast switching mode