This section explains the operations below when a master server error has occurred.
Errors while the system is running
Errors when the system starts up
When the events shown below occur on the master server (primary) while the system is operating, automatic switching to the master server (secondary) occurs.
The system stops due to the cause of such as system panic, forced power off.
The system has hung up
An error has occurred in the cluster interconnection
Error occurred on both cluster interconnect network in case redundant cluster interconnect is configured.
An error has occurred in the public LAN network
Error occrred on both publc LAN network in case redundant public LAN is configured.
An error has occurred in the iSCSI network
Error occrred on both iSCSI LAN network in case redundant iSCSI LAN is configured.
If JobTracker has ended abnormally, or been stopped using a method other than the bdpp_stop command (*1)
*1: JobTracker was stopped using the Apache Hadoop feature directly
Note
If an error occurs in the public LAN network or the iSCSI network, and there is a switch from the master server (primary) to the master server (secondary), refer to "5.4.1.3 If an Error Occurs in the Network" and perform the necessary operations.
If the switch from the master server occurs while a job is running, the execution of that job is suspended. Check the execution of the job status, and if necessary re-execute the job on the server that the job is switched to (master server (secondary)).
If an error occurs in the master server (primary) and there is a switch to the master server (secondary), it is possible to switch back to the master server (primary) after the cause of the error has been removed. Restart the system by executing the command to switch back on the master server (secondary) or switch back to the master server (primary).
Figure 5.1 Flow of operations between the occurrence of an error to the resumption of operations
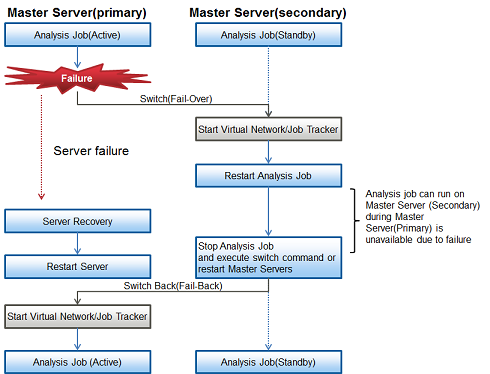
To switch back from the master server (secondary) to the master server (primary), use the hvswitch command.
# hvswitch app1 <Enter>
"app1" is a fixed string.
The switch back takes about 30 seconds, so execute the bdpp_stat command on the master server (primary) and see that Hadoop is running properly on the master server (primary).
Refer to "hvswitch" in "7.2.2 Switching an application" of the "PRIMECLUSTER Reliant Monitor Services (RMS) with Wizard Tools Configuration and Administration Guide" and Online help (man hvswitch) for information on the hvswitch bdpp_stat commands.
Refer to "A.1.12 bdpp_stat" for information on the bdpp_stat commands.
Note
The master server feature that is used for the execution of "4.9.1 Adding Slave Servers" is not a target of switching.
Perform "4.9.1 Adding Slave Servers" again after removing the cause of the problem from the master server (primary) if an error has occurred on it, and there was a switch to the master server (secondary).
If the events shown below occur in the master server when the system starts up, the normal start operation cannot be performed.
This section explains the operations that are used to start the system on the other server.
Starting the system when the master server (primary) is not running
Hadoop can be started with the bdpp_start command if the system has been running with the master server (secondary) because an error rendered the master server (primary) inoperable.
Refer to "A.1.11 bdpp_start" for details on starting Hadoop.
Starting the system when the master server (secondary) is not running
Hadoop can be started with the bdpp_start command if the system has been running with the master server (primary) because an error rendered the master server (secondary) inoperable.
Refer to "A.1.11 bdpp_start" for details on starting Hadoop.
The operations described below are required if there has been an error on the network causing a switch from the master server (primary) to the master server (secondary).
Log in to the server where the error occurred with root permissions.
Check DFS status.
# pdfsrscinfo -m <Enter>
/dev/disk/by-id/scsi-1FUJITSU_300000370106:
FSID MDS/AC STATE S-STATE RID-1 RID-2 RID-N hostname
1 MDS(P) run - 0 0 0 master1 <-- Master server (primary)
is in run state
1 AC run - 0 0 0 master1
1 MDS(S) wait - 0 0 0 master2
1 AC run - 0 0 0 master2On the server where the error occurred, unmount the DFS, and stop or restart the system.
# pdfsumount /mnt/pdfs <Enter> or; # shutdown -h now <Enter> or; # shutdown -r now <Enter>
Next log in to the switched server with root permissions.
Unmount the DFS.
# pdfsumount /mnt/pdfs <Enter>
Mount the DFS.
# pdfsmount /mnt/pdfs <Enter>
Check that the status of the DFS of the switched server is "run" using the pdfsrscinfo command.
# pdfsrscinfo -m <Enter> /dev/disk/by-id/scsi-36000c298b3c931387b26aaa0a9ee314f-part2: FSID MDS/AC STATE S-STATE RID-1 RID-2 RID-N hostname 1 MDS(P) stop - 0 0 0 master1 1 AC stop - 0 0 0 master1 1 MDS(S) run - 0 0 0 master2 <-- Master server (secondary) is in run state 1 AC run - 0 0 0 master2
Log into the servers connected to the master server (the slave servers, development server and collaboration server) using root permissions, unmount the DFS, then mount it again.
# umount pdfs1 <Enter> # mount pdfs1 <Enter>
This completes the operation. After this it is possible to restart operations.
When the server where the error occurred is restored and there is a switch back to the original server, complete steps 1 to 7, replacing "server where the error occurred" with "switched server" and "switched server" with "server after restoration".
Switch the server back using the hvswitch command.
# hvswitch app1 <Enter>
"app1" is a fixed string.
See
Refer to the "Appendix A Command Reference" of the "Primesoft Distributed File System for Hadoop V1 User's Guide" for information on the pdfsrscinfo, pdfsumount and pdfsmount commands.
Refer to "hvswitch" in "7.2.2 Switching an application" of the "PRIMECLUSTER Reliant Monitor Services (RMS) with Wizard Tools Configuration and Administration Guide" for information on the hvswitch command.