This section describes the hardware configuration for using this product.
Server configuration
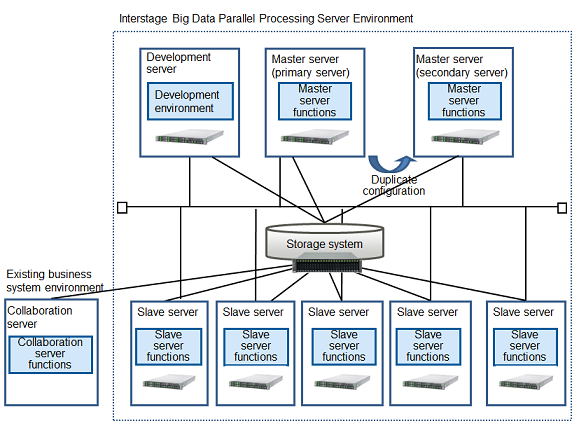
A master server splits large data files into blocks and makes files (distributed file system), and centrally manages those file names and storage locations.
A master server can also receive requests to execute analysis processing application jobs, and cause parallel distributed processing on slave servers.
This product requires that the master server is duplicated (a primary server and a secondary server).
This product's master server functions are installed on both the primary and secondary server of the master server.
Analysis processing can be performed in a short amount of time because the data file, split into blocks by the master server, is processed using parallel distributed processing on multiple slave servers.
Furthermore, the data that is split into blocks is stored in a high-reliability system.
This products's slave server functions are installed at each slave server.
The development server is a server where Pig or Hive is installed and executed. They enable easy development of applications that perform parallel distribution (MapReduce).
This product's development server functions are installed at the development server.
With Apache Hadoop, it was necessary to register in HDFS, the distributed file system for Hadoop, in order to analyze. Analysis can be performed by directly transferring the large amount of data on the business system to the DFS (Distributed File System), which is built on the high reliability storage system that is one of the main features of this product, from the collaboration server using the Linux standard file interface.
Installation of an existing data backup system on the collaboration server enables easy use of data backups.
This products's collaboration server functions are installed at the collaboration server.
Note
Make sure that the data stored in the DFS using data transfer is the data that is to be analyzed using Hadoop. Other data cannot be stored.
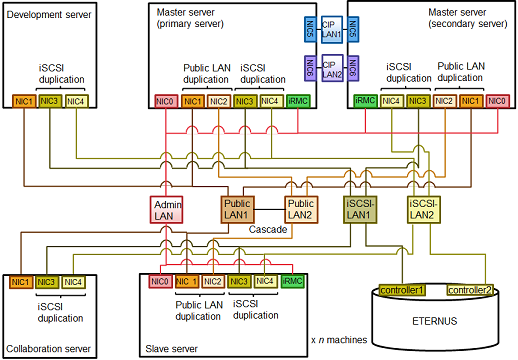
LAN used to perform the cloning processes in Smart setup.
This is established separately to the public LAN used for Hadoopp parallel distributed processing.
Use the first network interface as the connection for the admin LAN.
This is the LAN for analysis processing tasks between a master server and slave servers.
A configuration without redundancy is possible. However, by using the network redundancy software incorporated in this product, public LAN redundancy is possible even if a fault occurs in one LAN.
The configuration file (bdpp.conf) used during installation can be used to set whether or not redundancy is used. Refer to "A.2.1 bdpp.conf" for details of bdpp.conf.
This product uses Internet Small Computer System Interface (iSCSI) as the interface between the servers and the storage systems. This is the LAN for this iSCSI connection.
It is recommended to make the transfer speed between the storage systems and the network switch 10Gbit/s or more.
We recommend a redundancy configuration by means of the ETERNUS multipath driver as a precaution in case of a LAN fault.
This is the LAN used for a HA cluster configuration for the primary server and secondary server. A configuration without redundancy is possible, but we recommend redundancy as a precaution in case of a LAN fault.
The configuration file (bdpp.conf) used during installation can be used to set whether or not redundancy is used. Refer to "A.2.1 bdpp.conf" for details of bdpp.conf.
The following hardware conditions must be met when using this product.
Function | Hardware | Notes |
|---|---|---|
Master server | PRIMERGY RX Series, | The CPU must be at least a dual-core CPU. |
Slave server | PRIMERGY RX Series, | The CPU must be at least a dual-core CPU. |
Development server | PRIMERGY RX Series, | The CPU must be at least a dual-core CPU. |
Collaboration server | PRIMERGY RX Series, | The CPU must be at least a dual-core CPU. |
External storage apparatus | ETERNUS DX series |
*1: Refer to the supported model information at the following site for the PRIMERGY RX and TX Series models supported by this product.
Supported model information
Refer to following URL for detail information on supported PRIMERGY RX/TX :
http://globalsp.ts.fujitsu.com/dmsp/Publications/public/ds-ror-ve-v3-0-ww-en.pdf
The static disk sizes below are required for a new installation of this product. Disk sizes vary in accordance with differences in the environment being checked.
Static disk size (not including OS)
OS type | Directory | Disk size (unit: megabytes) |
|---|---|---|
Linux | /opt | 900 |
/etc | 16 | |
/var | 220 | |
/usr | 60 |
OS type | Directory | Disk size (unit: megabytes) |
|---|---|---|
Linux | /opt | 120 |
/etc | 1 | |
/var | 25 | |
/usr | 60 |
OS type | Directory | Disk size (unit: megabytes) |
|---|---|---|
Linux | /opt | 10 |
/etc | 1 | |
/var | 1 | |
/usr | 60 |
OS type | Directory | Disk size (unit: megabytes) |
|---|---|---|
Linux | /opt | 30 |
/etc | 1 | |
/var | 1 | |
/usr | 60 |
When using this product, the disk sizes below are required in addition to the static disk size, in the master server and slave server directories.
Installation type | Directory | Disk size (unit: megabytes) |
|---|---|---|
Master server | /etc | 2 |
/var/opt | 2510 | |
Cloning image file storage directory Default: /var/opt/FJSVscw-deploysv/depot | Cloning image file storage area | |
Agent | /etc | 1 |
/var/opt | 1 |
Cloning image file storage area
A cloning image file storage area is required if cloning is to be performed.
Allocate area on the master server as an area to store the slave server cloning image files that are collected when cloning is used.
Note
Create the cloning image file storage area at the master server local disk or at SAN storage. Folders on network drives, shared folders (NFS, SMB, etc.) on other machines on the network, or UNC format folders cannot be specified.
The server used to create the cloning image and the servers targeted as clones must be the same model. If there are different models, a separate cloning image must be created for each model. Refer to "4.9.1.1.3 Creating a Cloning Image" for details.
The method for estimating the space required as a cloning image file storage area is as follows:
Cloning image file storage area = Disk space used by one slave server * Compression ratio * Number of models
If actual results are available from a system build having the same software configuration, use the same disk size as that system. If one disk is split into multiple sections, use the total size used in all sections.
Use the operating system features to check the disk size used.
If actual results are not available from a system build having the same software configuration, make an estimation on the basis of the disk space given in software installation guides or similar.
This is the compression ratio when the disk area used at the slave server is stored at the master server as an image file.
The compression ratio depends on the file content, but generally a ratio of about 50% can be expected.
The following memory sizes are required in order to use this product.
Memory size (not including OS)
OS type | Memory size (unit: gigabytes) |
|---|---|
Linux | 8.0 or more |
OS type | Memory size (unit: gigabytes) |
|---|---|
Linux | 4.0 or more |
OS type | Memory size (unit: gigabytes) |
|---|---|
Linux | 4.0 or more |
OS type | Memory size (unit: gigabytes) |
|---|---|
Linux | 4.0 or more |
Two or more network interface cards will be required when building LAN redundancy.