ここでは、以下の場合でマスタサーバに異常が発生した際の動作について説明します。
システムの運用中の異常
システム起動時の異常
システムの運用中に、マスタサーバ(プライマリ)に以下に示す事象が発生した場合、マスタサーバ(セカンダリ)へ切り替えが発生します。
システムがパニックまたは、強制電源切断などで停止した場合
システムがハングアップした場合
クラスタインターコネクトに異常が発生した場合
クラスタインターコネクトを二重化している場合は、その両方に異常が発生した場合
業務 LAN のネットワークに異常が発生した場合
業務 LAN を二重化している場合は、その両方に異常が発生した場合
iSCSI のネットワークに異常が発生した場合
マルチパスドライバを利用して、iSCSI を二重化している場合は、その両方に異常が発生した場合
JobTracker が異常終了または、“bdpp_stop コマンド”以外の方法(*)で停止した場合
*: Apache Hadoop の機能を直接利用して、JobTracker を停止した場合
注意
業務 LAN のネットワーク、またはiSCSI のネットワークに異常が発生して、マスタサーバ(プライマリ)からマスタサーバ(セカンダリ)へ切り替えられた場合は、「5.4.1.3 ネットワークに異常が発生した場合」を参照して操作を行う必要があります。
ジョブの実行中にマスタサーバの切り替えが発生した場合、ジョブの実行が中断されますので、ジョブの実行状況を確認し、切り替わった側(マスタサーバ(セカンダリ))で、必要に応じて再度ジョブを実行してください。
マスタサーバ(プライマリ)に異常が発生し、マスタサーバ(セカンダリ)に切り替わった場合は、マスタサーバ(プライマリ)で異常の原因を取り除いてシステムを再起動させた後、マスタサーバ(セカンダリ)で切り戻しコマンドを実行する、またはシステムを再起動してマスタサーバ(プライマリ)に切り戻しを行うことができます。
図5.1 異常発生から業務再開までの流れ
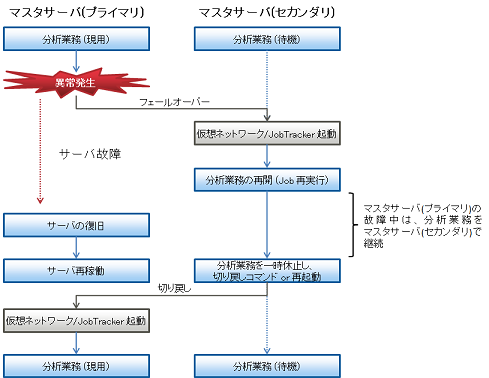
コマンドで、マスタサーバ(セカンダリ)からマスタサーバ(プライマリ)へ切り戻しを行うには、“hvswitch コマンド”を使用します。
# hvswitch app1 <Enter>
“app1”は、固定の文字列です。
約30秒程度で切り戻されるため、マスタサーバ(プライマリ)で“bdpp_stat コマンド”を実行し、Hadoop がマスタサーバ(プライマリ)上で動作していることを確認してください。
“hvswitch コマンド”の詳細は、「PRIMECLUSTER 活用ガイド <コマンドリファレンス編>」-「第7章」-「hvswitch」、“bdpp_stat コマンド”の詳細は、「A.1.12 bdpp_stat」をそれぞれ参照してください。
注意
「4.9.1 スレーブサーバの追加」を行うためのマスタサーバの機能は、切り替えの対象とはなりません。
マスタサーバ(プライマリ)に異常が発生し、マスタサーバ(セカンダリ)に切り替わった場合は、マスタサーバ(プライマリ)で異常の原因を取り除いた後、マスタサーバ(プライマリ)へ切り戻しを行ってから、再度「4.9.1 スレーブサーバの追加」を実施してください。
システムの起動時に、マスタサーバに以下の事象が発生した場合、通常の起動操作が出来ません。
ここでは、片系運用の場合において運用を開始する場合の操作について説明します。
マスタサーバ(プライマリ)が起動していない場合のシステム起動
マスタサーバ(プライマリ)が何等かの異常により動作しない状況で、システムをマスタサーバ(セカンダリ)だけで起動した場合、“bdpp_start コマンド”による Hadoop の起動が可能です。
Hadoop の起動については、「A.1.11 bdpp_start」を参照してください。
マスタサーバ(セカンダリ)が起動していない場合のシステム起動
マスタサーバ(セカンダリ)が何等かの異常により動作しない状況で、システムをマスタサーバ(プライマリ)だけで起動した場合、“bdpp_start コマンド”による Hadoop の起動が可能です。
Hadoop の起動については、「A.1.11 bdpp_start」を参照してください。
ネットワークに異常が発生して、マスタサーバ(プライマリ)からマスタサーバ(セカンダリ)に切り替えられた場合、以下に示す操作が必要です。
異常が発生したサーバに、root 権限でログインします。
DFS の状態を確認します。
# pdfsrscinfo -m <Enter> /dev/disk/by-id/scsi-1FUJITSU_300000370106: FSID MDS/AC STATE S-STATE RID-1 RID-2 RID-N hostname 1 MDS(P) run - 0 0 0 master1 ← マスタサーバ(プライマリ)がrun状態 1 AC run - 0 0 0 master1 1 MDS(S) wait - 0 0 0 master2 1 AC run - 0 0 0 master2
異常が発生したサーバで DFS をアンマウント、システムを停止、または再起動します。
# pdfsumount /mnt/pdfs <Enter> または、 # shutdown -h now <Enter> または、 # shutdown -r now <Enter>
次に、切り替えられたサーバに、root 権限でログインします。
DFS をアンマウントします。
# pdfsumount /mnt/pdfs <Enter>
DFS をマウントします。
# pdfsmount /mnt/pdfs <Enter>
“pdfsrscinfo コマンド”で、切り替えられたサーバの DFS が“run”状態であることを確認します。
# pdfsrscinfo -m <Enter> /dev/disk/by-id/scsi-36000c298b3c931387b26aaa0a9ee314f-part2: FSID MDS/AC STATE S-STATE RID-1 RID-2 RID-N hostname 1 MDS(P) stop - 0 0 0 master1 1 AC stop - 0 0 0 master1 1 MDS(S) run - 0 0 0 master2 ← マスタサーバ(セカンダリ)がrun状態 1 AC run - 0 0 0 master2
マスタサーバに接続されるすべてのサーバ(スレーブサーバ、開発実行環境サーバ、連携サーバ)で、それぞれ root 権限でログインして、DFS をアンマウント、および再マウントします。
# umount pdfs1 <Enter> # mount pdfs1 <Enter>
以上で操作は完了です。以後、業務を再開することができます。
異常が発生したサーバが復旧し、元のサーバに切り戻す場合は、「異常が発生したサーバ」を「切り替えられたサーバ」、「切り替えられたサーバ」を「復旧後のサーバ」にそれぞれ読み替えて、1から7までの手順を実施します。
“hvswitch コマンド”でサーバの切り戻しを行います。
# hvswitch app1 <Enter>
“app1”は、固定の文字列です。
参照
pdfsrscinfo, pdfsumount, pdfsmount の各コマンドについては、「Primesoft Distributed File System for Hadoop V1 ユーザーズガイド」の「コマンドリファレンス」で 各コマンドを参照してください。
“hvswitch コマンド”の詳細は、「PRIMECLUSTER 活用ガイド <コマンドリファレンス編>」-「第7章」-「hvswitch」を参照してください。