クライアント用の動作環境ファイルには、アプリケーションの実行に必要な環境情報として実行パラメタを記述します。
実行パラメタは、以下に示す種類があります。
分類 | 実行パラメタ | 概要 | 記述数 | 記述の省略 | 埋込みSQL | JDBC |
|---|---|---|---|---|---|---|
通信 | 通信に利用するバッファ(クライアント側)のサイズ | 単一 | 省略可能 | ○ | ○ | |
アプリケーションをフェイルオーバ運用で実行する場合に必要な情報 | 単一 | 省略可能 | ○ |
| ||
サーバとの結合情報のデフォルト | 単一 | CONNECT文にDEFAULTを指定する場合は省略不可。 | ○ |
| ||
使用するサーバ用の動作環境ファイル名 | 複数可 | 省略可能 | ○ | ○ | ||
リモートのサーバと通信するための情報 | 複数可 | リモートのデータベースにアクセスする場合省略不可。ローカルの場合は指定できない。 | ○ |
| ||
SQLエラー発生時のトランザクション | 単一 | 省略可能 | ○ | ○ | ||
1つのトランザクションの最大使用可能時間 | 単一 | 省略可能 | ○ | ○ | ||
通信時の待ち時間 | 単一 | 省略可能 | ○ | ○ | ||
作業領域など | 動的SQLのSQL記述子の情報 | 単一 | 省略可能 | ○ |
| |
同時に操作できるSQL文の数 | 単一 | 省略可能 | ○ | ○ | ||
SQL文の実行手順を格納しておくバッファのサイズ | 単一 | 省略可能 | ○ | ○ | ||
一括FETCHを行う場合のバッファの数とサイズ | 単一 | 省略可能 | ○ | ○ | ||
作業用ソート領域として使うメモリサイズ | 単一 | 省略可能 | ○ | ○ | ||
作業用テーブルおよび作業用ソート領域として使用するファイルサイズ | 単一 | 省略可能 | ○ | ○ | ||
作業用テーブルとして使うメモリのサイズ | 単一 | 省略可能 | ○ | ○ | ||
作業用テーブルおよび作業用ソート領域のパス | 単一 | 省略可能 | ○ | ○ | ||
データ処理 | 代入処理でオーバフローが起きた場合の処理 | 単一 | 省略可能 | ○ | ○ | |
文字コードの変換をクライアントで行うか否か | 単一 | 省略可能 | ○ | ○ | ||
アプリケーション中の文字のコード | 単一 | 省略可能 | ○ |
| ||
JDBCドライバがコード変換時に使用するJavaのエンコーディング方法 | 単一 | 省略可能 |
| ○ | ||
JDBCドライバ利用時において、列名に全角小文字を使用し、かつResultSet.getXXXメソッドを使用する場合に、引数に指定した列名を正しく認識させるか否か | 単一 | 省略可能 |
| ○ | ||
アプリケーション中の日本語文字のコード | 単一 | 省略可能 | ○ |
| ||
表・インデックス | 格納構造定義を簡略化した表を定義する場合、Symfoware/RDBが自動的に生成する表のDSOの格納構造の選択 | 単一 | 省略可能 | ○ |
| |
格納構造定義を簡略化したインデックスを定義する場合のインデックスのデータ格納域の初期量、拡張量、ページ長など | 単一 | 省略可能 | ○ | ○ | ||
格納構造定義を簡略化した表を定義する場合のOBJECT構造の表のデータ格納域の初期量、拡張量、ページ長など | 単一 | 省略可能 | ○ | ○ | ||
格納構造定義を簡略化した表を定義する場合の表のデータ格納域の初期量、拡張量、ページ長など | 単一 | 省略可能 | ○ | ○ | ||
DSIの容量拡張を起動するか否か | 単一 | 省略可能 | ○ | ○ | ||
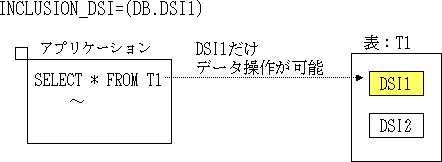
アプリケーションで使用するDSIを限定する | 単一 | 省略可能 | ○ | ○ | ||
一時表にインデックスを定義する場合のインデックスのデータ格納域の初期量、拡張量など | 単一 | 省略可能 | ○ | ○ | ||
一時表を定義する場合の表のデータ格納域の初期量、拡張量など | 単一 | 省略可能 | ○ | ○ | ||
排他 | 使用するDSOの占有の単位、占有モード | 単一 | 省略可能 | ○ | ○ | |
占有待ちの方式 | 単一 | 省略可能 | ○ | ○ | ||
占有の単位を行とする | 単一 | 省略可能 | ○ | ○ | ||
トランザクション | トランザクションアクセスモードの初期値を指定する | 単一 | 省略可能 | ○ | ○ | |
独立性水準の初期値を指定する | 単一 | 省略可能 | ○ | ○ | ||
デバッグ | アプリケーションで異常が発生した場合のダンプ出力先 | 単一 | 省略可能 | ○ |
| |
複数プロセス配下でアプリケーションが動作している場合、個別のトレース情報を出力するか否か | 単一 | 省略可能 | ○ |
| ||
ROUTINE_SNAP機能を利用するか否か | 単一 | 省略可能 | ○ | ○ | ||
コールバック関数の動的登録機能を利用するか否か | 単一 | 省略可能 | ○ |
| ||
SQL_SNAP機能を利用するか否か | 単一 | 省略可能 | ○ |
| ||
アクセスプランおよび性能情報(注) | アプリケーション単位でアクセスプランを取得するか否かおよびSQL文に対するアドバイスを出力するか否か | 単一 | 省略可能 | ○ | ○ | |
IGNORE_INDEX | インデックスを使用しないアクセスプランを選択するか否か | 単一 | 省略可能 | ○ | ○ | |
INACTIVE_INDEX_SCAN | 非活性状態のインデックスDSIを含むインデックスを使用したアクセスプランを選択するか否か | 単一 | 省略可能 | ○ | ○ | |
結合表と他の表のジョイン順 | 単一 | 省略可能 | ○ | ○ | ||
ジョインする方法 | 単一 | 省略可能 | ○ | ○ | ||
SCAN_KEY_ARITHMETIC_RANGE | 四則演算の検索範囲について、インデックスの範囲検索またはクラスタキーの検索を行うか否か | 単一 | 省略可能 | ○ | ○ | |
SCAN_KEY_CAST | 探索条件のCASTオペランドに指定した列でインデックスの範囲検索、または、クラスタキー検索を行うか否か | 単一 | 省略可能 | ○ | ○ | |
SORT_HASHAREA_SIZE | ソート処理がレコードをハッシングして格納するための領域サイズ | 単一 | 省略可能 | ○ | ○ | |
アプリケーション単位でSQL性能情報を取得するか否か | 単一 | 省略可能 | ○ | ○ | ||
述語ごとの検索範囲の選択率の値 | 単一 | 省略可能 | ○ | ○ | ||
インデックス検索と表データ取得のアクセスモデルでTIDソートを利用するか否か | 単一 | 省略可能 | ○ | ○ | ||
TIDユニオンマージのアクセスモデルを有効にするか否か | 単一 | 省略可能 | ○ | ○ | ||
UPDATE文:探索またはDELETE文:探索の更新標的レコードを位置づける部分の占有モード | 単一 | 省略可能 | ○ | ○ | ||
メッセージ | 表示するメッセージの言語種を設定する | 単一 | 省略可能 | ○ |
| |
SQL文実行時にエラーメッセージを表示するか否か | 単一 | 省略可能 | ○ |
| ||
リカバリ | アプリケーションのリカバリ水準を指定する | 単一 | 省略可能 | ○ | ○ | |
予約語とSQL機能 | アプリケーションの予約語とSQL機能のレベルを設定する | 単一 | 省略可能 | ○ | ○ | |
並列クエリ | データベースを並列に検索する場合の多重度 | 単一 | 省略可能 | ○ | ○ | |
アプリケーション単位またはコネクション単位に、データベースを並列に検索するか否か | 単一 | 省略可能 | ○ | ○ | ||
その他 | 表の設計変更により表の列を変更した場合、アプリケーションへの影響をチェックするか否か | 単一 | 省略可能 | ○ |
| |
アーカイブログ満杯時にエラー復帰するか否か | 単一 | 省略可能 | ○ | ○ | ||
シグナルをアプリケーションで利用するか否か | 単一 | 省略可能 | ○ |
|
埋込みSQL : 埋込みSQLを利用したアプリケーションにおいてパラメタが有効になるか否かを表します。
JDBC : JDBCドライバを利用したアプリケーションにおいてパラメタが有効になるか否かを表します。
○:パラメタが有効です。○が記載されていないパラメタはエラーになります。
注) アクセスプランおよび性能情報に関する実行パラメタです。
参照
アクセスプランおよび性能情報に関する実行パラメタの詳細については、“SQLTOOLユーザーズガイド”を参照してください。
通信に関する実行パラメタ
BUFFER_SIZE = ([初期量][,拡張量])
バッファの初期量を1~10240で指定します。省略した場合は、32が指定されたとみなします。
拡張量を1~10240で指定します。省略した場合は、32が指定されたとみなします。
CLUSTER_SERVICE_NAME = (クラスタサービス名)
PRIMECLUSTERまたはSafeCLUSTERと連携する場合、クラスタシステムに登録されているクラスタサービス名を記述します。
接続するデータベースに対するアクセス方法により、指定形式が異なります。
ローカルアクセスの場合
DEFAULT_CONNECTION = ([RDBシステム名.]データベース名)
リモートアクセスの場合
DEFAULT_CONNECTION = (SQLサーバ名,認可識別子,パスワード)
アプリケーションにCONNECT文を記述しない場合
CONNECT文にキーワード“DEFAULT”を指定した場合
CONNECT文のユーザ指定を省略した場合
サーバがマルチRDB運用をしている場合に結合するRDBシステム名を指定します。省略した場合は、環境変数RDBNAMEに設定されたRDBシステム名が指定されたとみなします。
接続するデータベース名を指定します。
接続するSQLサーバ名を指定します。
OSのログイン名、または、CREATE USER文で登録されている利用者名を指定します。
OSのパスワード、または、CREATE USER文で登録されているパスワードを指定します。
以下の場合、ログイン名およびパスワードの指定は不要です。
この場合、実行時のログイン名および実行時のパスワードが使用されます。
ローカルアクセスの場合
リモートアクセスの場合
![]()
![]() 接続先ホスト名に自端末のIPアドレス、自端末のホスト名、“localhost”またはループバックアドレスを指定した場合
接続先ホスト名に自端末のIPアドレス、自端末のホスト名、“localhost”またはループバックアドレスを指定した場合
![]() Windows(R) 2000の場合
Windows(R) 2000の場合
接続先ホスト名に“localhost”またはループバックアドレスを指定した場合
Windows Server(R) 2003以降の場合
接続先ホスト名に自端末のIPアドレス、自端末のホスト名、“localhost”またはループバックアドレスを指定した場合
ログイン名およびパスワードは、各サーバでは以下のように扱われます。
ログイン名
ログイン名のパスワード
ユーザ名(ログオン名)
ユーザ名のパスワード
SERVER_ENV_FILE = (SQLサーバ名,ファイル名)
CONNECT文の実行で指定するSQLサーバ名を記述します。
サーバ用の動作環境ファイル名を、絶対パスで指定します。
SERVER_SPEC = (通信方法,SQLサーバ名,データ資源名,ホスト名,ポート番号[,[接続サーバ種別]])
CONNECT文でSQLサーバ名を指定した場合、サーバとの通信状態を確立するために必要な情報を記述します。このため、CONNECT文で接続するSQLサーバ名は、アプリケーションの実行時にすべてSERVER_SPECに記述しておく必要があります。ローカルのデータベースだけにアクセスする場合は、この実行パラメタは指定しません。
TRAN_SPEC = ({NONE | TRANSACTION_ROLLBACK})
SQL文が実行中にエラーとなった場合のトランザクションの対処方法を指定します。省略した場合は、NONEが指定されたものとみなします。
なお、本実行パラメタは、トランザクションモニタ配下では指定できません。
各プラットフォームのトランザクションの仕様に従います。
SQL文の実行がエラーとなった場合に、トランザクションをロールバックします。
作業領域に関する実行パラメタ
MAX_SQL = (SQL文の数)
同一トランザクション内で指定できるSQL文の数を、2~32000の範囲で指定します。省略した場合は、1024が指定されたとみなします。
ポイント
MAX_SQLの値を拡張して使用した場合、以下の考慮が必要です。
Symfoware/RDBでは、同一SQL文を繰り返し実行する場合の処理効率を図るため、SQL文を実行するための情報の個数をMAX_SQLに指定します。また、SQL文の処理手順を格納するOPLバッファのサイズを、OPL_BUFFER_SIZEに指定します。
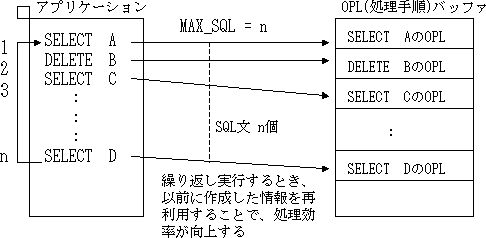
情報の保持数がMAX_SQLに指定した値を超えた場合、SQL文の実行情報は、古い情報から破棄されます。ただし、PREPARE文で準備されているSQL文およびオープン中のカーソルの情報は破棄できません。SQL文とSQL文情報の保持期間の関係を以下に示します。
SQL文の種類 | SQL文情報の保持期間 | |
|---|---|---|
動的SQL文 | カーソル系 | PREPARE文でSQL文が準備されてから、DEALLOCATE PREPARE文でSQL文が破棄されるまで |
非カーソル系 | ||
静的SQL文 | カーソル系 | OPEN文が実行されてからカーソルがクローズされるまで |
非カーソル系 | SQL文が実行されている間 | |
したがって、MAX_SQLには、以下の数の総和を指定してください。
PREPARE文で準備しているSQL文の数
同時にオープン中のカーソルの数
保持しておきたい静的SQL文の数
OPL_BUFFER_SIZE = (バッファサイズ)
Symfoware/RDBでは、同一SQL文を複数回実行するときに、最初の実行で作成した処理手順を使用することによって処理効率の向上を図っています。本パラメタは、このSQLの処理手順を格納するバッファのサイズを1~1280000で指定します。単位はキロバイトです。省略した場合は、8192が指定されたとみなします。この領域は、サーバ側で獲得されます。
注意
同一SQL文を複数回実行するとき、以下の場合については最初の実行で作成した処理手順は使用されず、新たに処理手順を作成します。
SQL埋込みCプログラムにおいて、ポインタ変数として宣言したホスト変数を使用している場合
前回の実行後、保持可能な処理手順の数(MAX_SQLに指定した値と同数)以上の異なるSQL文を実行した場合
前回の実行後、SET TRANSACTION文によりトランザクションモード(アクセスモードまたは独立性水準)を変更した場合
前回の実行後、SET CATALOG文により被準備文の対象となるデータベース名を変更した場合
前回の実行後、SET SCHEMA文により被準備文の省略したスキーマ名を変更した場合
前回の実行後、SET SESSION AUTHORIZATION文によりスコープの異なる利用者に変更した場合
前回の実行後、SQL文が使用するデータベース資源についてALTER TABLE文により動的に列の追加または削除を実行した場合
前回の実行後、SQL文が使用するデータベース資源についてCREATE DSI文により動的にDSIの追加または削除を実行した場合
前回の実行後、SQL文が使用するデータベース資源についてALTER DSI文により動的にDSIの分割値変更を実行した場合
動作環境ファイルのパラメタINACTIVE_INDEX_SCANにNOを指定している場合に、前回の実行後、rdbexdsiコマンドにより任意のDSIの除外または除外の解除を実行した場合
前回の実行後、SQL文が使用するデータベース資源を削除した場合
ポイント
MAX_SQLの値を拡張した場合は、OPL_BUFFER_SIZEの値も変更する必要があります。以下の方法で見積もった値をキロバイト単位で指定してください。
SQLの処理手順を格納するバッファのサイズ
= 0.7KB + Σ アクセス対象の表単位のSQL処理手順サイズ
アクセス対象の表単位のSQL処理手順サイズ
= 4.2KB + Σ SQL文単位のSQL処理手順サイズ
SQL文単位のSQL処理手順サイズ
= 0.17KB × 列数 + 0.08KB × 条件数アクセス対象の表単位のSQL処理手順サイズ
アクセス対象の表単位のSQL処理手順サイズの総和です。アクセス対象の表単位のSQL処理手順サイズを求め、それらを合計します。
SQL文単位のSQL処理手順サイズ
当該表をアクセスするSQL文単位のSQL処理手順サイズの総和です。当該表をアクセスするSQL文単位のSQL処理手順サイズを求め、それらを合計します。
列数
当該SQL文に記述する列の数です。列に“*”を記述する場合は、表を構成する列の数になります。
条件数
当該SQL文に記述する条件(述語)の数です。
RESULT_BUFFER = ([個数][,バッファサイズ])
Symfoware/RDBでは、FETCH文によってデータを取り出すときの性能を良くするため、複数の行を一度に取り出します。この行を格納するバッファの数とサイズを指定します。バッファサイズを大きくするほど、FETCHの性能が良くなります。また、1つのカーソルが1つのバッファを使用するので、複数のバッファを用意すれば、複数のカーソルの操作の性能を良くすることができます。バッファを使用しない場合は、個数に0を指定します。単位はキロバイトです。この領域は、クライアント側とサーバ側で獲得されます。
使用するバッファの個数を0~255で指定します。省略した場合、クライアントのプラットフォームにより、以下となります。
![]()
![]() 2が指定されたとみなします。
2が指定されたとみなします。
![]() 0が指定されたとみなします。
0が指定されたとみなします。
使用するバッファのサイズを1~10240で指定します。省略した場合、クライアントのプラットフォームにより、以下となります。
![]()
![]() 32が指定されたとみなします。
32が指定されたとみなします。
![]() 1が指定されたとみなします。
1が指定されたとみなします。
WORK_ALLOC_SPACESIZE = ([初期量][,[増分量][,[最大量][,[保持指定]]]])
作業用ソート領域および作業用テーブルとしてサーバ側で使用するファイルサイズの初期量、増分量、最大量、保持指定を指定します。単位はキロバイトです。
初期量、増分量、最大量、保持指定のいずれかの値が省略された場合は、その値のデフォルト値が指定されたものとみなします。
以下に指定例を示します。
WORK_ALLOC_SPACESIZE = (10000,50000)
WORK_ALLOC_SPACESIZE = (,50000,100000)
作業用ソート領域および作業用テーブルとして外部ファイルを作成する場合の初期量を5000~1000000の範囲で指定します。省略した場合は10000が指定されたとみなします。
作業用ソート領域および作業用テーブルとして作成した外部ファイルを拡張する場合の増分量を1000~1000000の範囲で指定します。省略した場合は、50000が指定されたとみなします。
作業用ソート領域および作業用テーブルとして作成する外部ファイルの最大量を5000~2000000の範囲で指定します。省略した場合は、WORK_PATHで指定したパス名のディスク容量となります。
以下の中から1つを選択します。省略した場合は、HOLDが指定されたものとみなします。
- FREE:初期量として獲得した作業用ソート領域および
作業用テーブルの外部ファイルは、DISCONNECT文の実行時に
解放します。
拡張量として獲得した作業用ソート領域および作業用テーブルの
外部ファイルは、その領域を使用したSQL文の実行完了時に
解放します。
- HOLD:作業用ソート領域および作業用テーブルとして作成した
外部ファイルは、DISCONNECT文の実行時に解放します。
WORK_PATH = (ワークパス名[,ワークパス名]・・・)
サーバ側で使用する作業用ソート領域および作業用テーブルとして、サーバ側での獲得先ディレクトリを指定します。
省略した場合は、システム用の動作環境ファイルにおけるWORK_PATHの指定に従います。
作業用ソート領域および作業用テーブルの見積りについては“C.1 ソート作業域の見積り”を参照してください。
データ処理に関する実行パラメタ
CHARACTER_TRANSLATE = ({CLIENT | SERVER})
データベースシステムの文字コード系が、アプリケーションで使用している文字コード系と異なる場合、コード変換をクライアントで行うか、サーバで行うかを指定します。省略した場合は、SERVERが指定されたとみなします。
LinuxクライアントでSQL埋込みホストプログラムを使用している場合で、かつアプリケーション起動時に環境変数LANGにja_JP.UTF-8が指定されている環境では、以下のデータベースに接続する場合にはCLIENTを指定する必要があります。
![]() Symfoware Server Enterprise Extended Edition 6.0.1以前
Symfoware Server Enterprise Extended Edition 6.0.1以前
Symfoware Server Enterprise Edition 6.0.1以前
Symfoware Server Standard Edition 6.0.1以前
![]() Symfoware Server Standard Edition V5.0L10以前
Symfoware Server Standard Edition V5.0L10以前
![]() Symfoware Server Enterprise Edition V6.0L10以前
Symfoware Server Enterprise Edition V6.0L10以前
Symfoware Server Standard Edition V6.0L10以前
Symfoware Server for Windows V6.0L10以前
クライアントでコード変換を行う場合に指定します。
サーバでコード変換を行う場合に指定します。
ポイント
サーバの負荷を少しでも減らしたい場合は、クライアントで行うよう指定します。
CHAR_SET = ({EUC_S90|EUC_U90|EUC|SJIS|UTF8})
文字列型のホスト変数、文字列型の動的パラメタ、および、SQLMSGの文字コード系を指定します。この指定は、アプリケーションをC言語で記述している場合に有効です。
データベースに格納される文字列型データの文字コード系とCHAR_SETとの関係を以下に示します。
データベースの文字コード系 | CHAR_SETの指定 | ||||
|---|---|---|---|---|---|
EUC_S90 | EUC_U90 | EUC | SJIS | UTF8 | |
EUCコードのS90コード | ◎ | × | ○ | ○ | |
EUCコードのU90コード | × | ◎ | ○ | ○ | |
シフトJISコード | ○ | ○ | ◎ | ○ | |
UNICODE | ○ | ○ | ○ | ◎ | |
◎:指定可能(省略値)
○:指定可能
×:指定不可能
ホスト変数内文字列のデータの文字コード系がEUCコードのS90コードの場合に指定します。
ホスト変数内文字列のデータの文字コード系がEUCコードのU90コードの場合に指定します。EUCは互換として存在します。
ホスト変数内文字列のデータの文字コード系がシフトJISコードの場合に指定します。
ホスト変数内文字列のデータの文字コード系がUNICODEの場合に指定します。
注意
アプリケーションをCOBOLで記述している場合は、本パラメタは無視されます。
参照
詳細は、“アプリケーション開発ガイド(埋込みSQL編)”の“文字コード系の決定”を参照してください。
JAVA_CONVERTER = (エンコーディング名)
JDBCドライバがコード変換時に使用する、Javaのエンコーディングを指定します。
JDBCドライバがコード変換時に使用する、Javaのエンコーディングを指定します。
JavaVMでサポートされているエンコーディング名を指定してください。省略した場合は、JDBCドライバが動作しているJava実行環境に合わせて、自動設定されます。
アプリケーション実行環境のロケールがCで、ASCIIコード範囲外の文字データを利用する場合、本パラメタで、対象データのエンコーディングを指定してください。
LOWERCASE_NAME =({ YES | NO })
列名に全角小文字を使用していて、ResultSet.getXXXメソッドを使用する場合に、指定した列名を正しく認識させるために指定します。省略した場合は、NOが指定されたとみなします。
Symfoware/RDBの表定義で、列名に全角小文字を使用している場合に指定します。
Symfoware/RDBの表定義で、列名に全角小文字を使用していない場合に指定します。
NCHAR_CODE = ({EUC_S90|EUC_U90|EUC|COBOL_EUC_S90|COBOL_EUC_U90|COBOL_EUC|SJIS|UTF8|UCS2|UCS2B })
各国語文字列型のホスト変数、各国語文字列型の動的パラメタの文字コード系を指定します。この指定は、アプリケーションをC言語で記述している場合に有効です。
アプリケーションをC言語で記述している場合の、CHAR_SETとNCHAR_CODEの関係を以下に示します。
| NCHAR_CODEの指定 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
CHAR_SET | EUC | COBOL | EUC | EUC | COBOL | COBOL | SJIS | UTF8 | UCS2 | UCS2B |
EUC_S90 | ◎ | ○ | × | × | × | |||||
EUC_U90 | × | ◎ | ○ | × | × | |||||
EUC | ||||||||||
SJIS | × | × | ◎ | × | ||||||
UTF8 | × | × | × | ◎ | ○ | |||||
◎:有効(省略値)
○:有効
×:無効(指定値を無視して省略値になります)
データベースに格納される各国語文字列型データの文字コード系とNCHAR_CODEとの関係を以下に示します。
データベース | NCHAR_CODEの指定 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
EUC | COBOL | EUC | EUC | COBOL | COBOL | SJIS | UTF8 | UCS2 | UCS2B | |
EUCコード | ◎ | × | ○ | ○ | ||||||
EUCコード | × | ◎ | ○ | ○ | ||||||
シフトJISコード | ○ | ○ | ◎ | ○ | ||||||
UNICODE | ○ | ○ | ○ | ◎ | ||||||
◎:指定可能(省略時は、CHAR_SETに設定される値かCHAR_SETの省略値)
○:指定可能
×:指定不可能
ホスト変数内文字列のデータの文字コード系がEUCコードのS90コードの場合に指定します。
ホスト変数内文字列のデータの文字コード系がEUCコードのU90コードの場合に指定します。EUCは下位互換として存在します。
ホスト変数内文字列のデータの文字コード系がEUCコードのS90コードのCOBOLの内部表現形式(COBOL_EUC)の場合に指定します。
ホスト変数内文字列のデータの文字コード系がEUCコードのU90コードのCOBOLの内部表現形式(COBOL_EUC)場合に指定します。COBOL_EUCは下位互換として存在します。
ホスト変数内文字列のデータの文字コード系がシフトJISコードの場合に指定します。
ホスト変数内文字列のデータの文字コード系がUNICODEのUTF-8コードの場合に指定します。
ホスト変数内文字列のデータの文字コード系がUNICODEのUCS-2コードの場合に指定します。
ホスト変数内文字列のデータの文字コード系がUNICODEのUCS-2コードのバイトスワップ形式の場合に指定します。
注意
アプリケーションをCOBOLで記述している場合は、本パラメタは無視されます。
参照
詳細は、“アプリケーション開発ガイド(埋込みSQL編)”の“文字コード系の決定”を参照してください。
表・インデックスに関する実行パラメタ
DEFAULT_DSI_TYPE = {SEQUENTIAL | OBJECT}
格納構造定義を簡略化した表を定義する場合に、Symfoware/RDBが自動的に生成する表のDSOの格納構造を選択します。この実行パラメタを省略した場合は、システム用の動作環境ファイルにおけるDEFAULT_DSI_TYPEの指定に従います。
本パラメタにより格納構造の選択ができるのは、表の形式が以下の条件をすべて満たしている場合のみです。
表の最後に1つだけ、BLOB型でサイズに32キロバイト以上を指定している場合
BLOB型以外の列は固定長属性の場合
BLOB型の列にNOT NULL制約を指定している場合
上記以外の場合は、表のDSOはSEQUENTIAL型となります。
表のDSOとしてSEQUENTIAL格納構造のDSOを定義します。
表のDSOとしてOBJECT格納構造のDSOを定義します。
DEFAULT_INDEX_SIZE = (ベース部ページ長,インデックス部ページ長,ベース部初期量,インデックス部初期量[,拡張量,拡張契機])
格納構造定義を簡略化したインデックスを定義する場合、インデックスのベース部とインデックス部の割付け量、ページ長などを指定します。単位はキロバイトです。この実行パラメタを省略した場合は、システム用の動作環境ファイルにおけるDEFAULT_INDEX_SIZEの指定に従います。
ベース部のページ長を1、2、4、8、16、32の中から指定します。
インデックス部のページ長を1、2、4、8、16、32の中から指定します。
ベース部の初期量を2~2097150の範囲で指定します。
インデックス部の初期量を2~2097150の範囲で指定します。
インデックスのベース部の拡張量を1~2097150の範囲で指定します。省略した場合は、10240が指定されたとみなします。インデックス部の拡張量は、ベース部の5分の1の値となります。
ベース部およびインデックス部の拡張を行うタイミングとして、DSIの空き容量を0~2097150の範囲で指定します。つまり、インデックスのDSIの空き容量がここで指定した値になると、インデックスのベース部およびインデックス部の拡張が行われます。省略した場合は、0が指定されたとみなします。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
ベース部の5分の1がインデックス部のページ長の倍数でない場合、インデックス部のページ長の倍数に繰り上げます。
DEFAULT_OBJECT_TABLE_SIZE = (ページ長,初期量[,拡張量,拡張契機])
格納構造定義を簡略化した表を定義する場合、OBJECT構造の表のデータ格納域の割付け量、ページ長などを指定します。単位はキロバイトです。この実行パラメタを省略した場合は、システム用の動作環境ファイルにおけるDEFAULT_OBJECT_TABLE_SIZEの指定に従います。
データ格納域のページ長を指定します。必ず32を指定します。
データ格納域の初期量を2~2097150の範囲で指定します。
データ格納域の拡張量を1~2097150の範囲で指定します。省略した場合は、32768が指定されたとみなします。
データ格納域の拡張を行うタイミングとして、表のDSIの空き容量を0~2097150の範囲で指定します。つまり、表のDSIの空き容量がここで指定した値になると、表のデータ格納域の拡張が行われます。省略した場合は、0が指定されたとみなします。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
DEFAULT_TABLE_SIZE = (ページ長,初期量[,拡張量,拡張契機])
格納構造定義を簡略化した表を定義する場合、表のデータ格納域の割付け量、ページ長などを指定します。単位はキロバイトです。この実行パラメタを省略した場合は、システム用の動作環境ファイルにおけるDEFAULT_TABLE_SIZEの指定に従います。
データ格納域のページ長を1、2、4、8、16、32の中から指定します。
データ格納域の初期量を2~2097150の範囲で指定します。
データ格納域の拡張量を1~2097150の範囲で指定します。省略した場合は、10240が指定されたとみなします。
データ格納域の拡張を行うタイミングとして、表のDSIの空き容量を0~2097150の範囲で指定します。つまり、表のDSIの空き容量がここで指定した値になると、表のデータ格納域の拡張が行われます。省略した場合は、0が指定されたとみなします。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
DSI_EXPAND_POINT=({ON | OFF})
アプリケーションによるデータ操作で、DSIに指定された拡張契機(rdbalmdsiコマンドまたはDSI定義文で定義します)を無効とするか否かを指定します。省略した場合、ONが指定されたとみなします。
DSIに定義された拡張契機は有効になります。アプリケーションによるデータ操作で、DSIの空きページ容量が拡張契機に達した時点で、領域を拡張します。
DSIに定義された拡張契機は無効になります。アプリケーションによるデータ操作で、DSIの空きページ容量が拡張契機に達しても、領域を拡張しません。この場合、DSIの空き領域が枯渇した時点で、領域を拡張します。
TEMPORARY_INDEX_SIZE = (ベース部初期量,インデックス部初期量[,拡張量,拡張契機])
一時表にインデックスを定義する場合に、インデックスのベース部とインデックス部の割付け量を指定します。単位はキロバイトです。この実行パラメタを省略した場合は、システム用の動作環境ファイルにおけるTEMPORARY_INDEX_SIZEの指定に従います。
ベース部の初期量を64~2097150の範囲で指定します。
インデックス部の初期量を64~2097150の範囲で指定します。
インデックスのベース部の拡張量を32~2097150の範囲で指定します。インデックス部の拡張量は、ベース部の5分の1の値となります。
ベース部およびインデックス部の拡張を行うタイミングとして、インデックスの空き容量を0~2097150の範囲で指定します。つまり、インデックスの空き容量がここで指定した値になると、インデックスのベース部およびインデックス部の拡張が行われます。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
ベース部の5分の1がインデックス部のページ長の倍数でない場合、インデックス部のページ長の倍数に繰り上げます。
TEMPORARY_TABLE_SIZE = (初期量[,拡張量,拡張契機])
一時表を定義する場合に、表のデータ格納域の割付け量を指定します。単位はキロバイトです。この実行パラメタを省略した場合は、システム用の動作環境ファイルにおけるTEMPORARY_TABLE_SIZEの指定に従います。
データ格納域の初期量を64~2097150の範囲で指定します。
データ格納域の拡張量を32~2097150の範囲で指定します。
データ格納域の拡張を行うタイミングとして、表の空き容量を0~2097150の範囲で指定します。つまり、表の空き容量がここで指定した値になると、表のデータ格納域の拡張が行われます。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
排他に関する実行パラメタ
DSO_LOCK = (DSO名[/[P][占有モード]][,DSO名[/[P][占有モード]]・・・])
アプリケーションで使用するDSOおよびその占有の単位、占有モードを指定します。
本パラメタを指定した場合、指定されなかったDSOについては、占有単位がページとなります。
DSO_LOCKが指定された場合、SET TRANSACTION文、クライアント用の動作環境ファイルのDEFAULT_ACCESS_MODEおよびDEFAULT_ISOLATIONは指定できません。
なお、動作環境ファイルのR_LOCKの値により、DSO_LOCKを指定できない場合があります。詳細は、“表1.3 DSO_LOCKとR_LOCKの関係”を参照してください。
アプリケーションで使用するDSO名を以下の形式で指定します。
データベース名.DSO名
DSOの占有の単位をページとします。省略した場合は、占有の単位はDSIとなります。
DSO名に指定されたDSOにPRECEDENCE(1)が指定されている場合、本パラメタは指定できません。
占有のモードとして以下のいずれかを指定します。省略した場合は、EXが指定されたとみなします。
- EX: 非共有モードの排他を行います。
- SH: 共有モードの排他を行います。
ISOLATION_WAIT = ({WAIT | REJECT})
あるトランザクションで資源にアクセスしようとしたとき、別のトランザクションがその資源を占有していた場合に、資源の占有が解除されるまで待つか否かを指定します。省略した場合は、WAITが指定されたとみなします。
資源の占有が解除されるまで待ちます。
エラーとしてアプリケーションに復帰します。
R_LOCK = ({YES | NO})
占有の単位を行とします。このパラメタを指定した場合、クライアント用およびサーバ用の動作環境ファイルにDSO_LOCKパラメタを指定することはできません。
占有の単位は、DSO_LOCKの指定に従います。このパラメタを指定し、かつDSO_LOCKが指定されていない場合は、Symfoware/RDBによって自動的に占有の単位が選択されます。詳細については、“1.1.7 排他制御”を参照してください。
注意
動作環境ファイルのR_LOCKがNOの場合、動作環境ファイルのDEFAULT_ISOLATIONにREPEATABLE_READを指定、またはSET TRANSACTION文にREPEATABLE READを指定しても、独立性水準はSERIALIZABLEになります。
動作環境ファイルのR_LOCKがYESの場合、動作環境ファイルのDEFAULT_ISOLATIONまたはSET TRANSACTION文にSERIALIZABLEを指定しても、独立性水準はREPEATABLE READになります。
動作環境ファイルのR_LOCKがNOの場合、DSO定義でPRECEDENCE(1)が指定されたSEQUENTIAL構造の表にアクセスするアプリケーションの排他の単位はDSIになります。
トランザクションに関する実行パラメタ
DEFAULT_ACCESS_MODE = ({READ_ONLY | READ_WRITE})
トランザクションアクセスモードの初期値を指定します。DEFAULT_ACCESS_MODEが指定された場合、プロセスで最初に実行されるSQL文の直前でSET TRANSACTION文が実行されたことになります。省略した場合は、システム用の動作環境ファイルにおけるDEFAULT_ACCESS_MODEの指定に従います。
DEFAULT_ACCESS_MODEが指定された場合、動作環境ファイルのDSO_LOCKは指定できません。
トランザクションアクセスモードの初期値をREAD ONLYとします。
トランザクションアクセスモードの初期値をREAD WRITEとします。
DEFAULT_ISOLATION = ({DEFAULT | READ_UNCOMMITTED | READ_COMMITTED | REPEATABLE_READ | SERIALIZABLE})
独立性水準の初期値を指定します。DEFAULT_ISOLATIONが指定された場合、プロセスで最初に実行されるSQL文の直前でSET TRANSACTION文が実行されたことになります。省略した場合は、DEFAULTが指定されたとみなします。
DEFAULT_ISOLATIONが指定された場合、動作環境ファイルのDSO_LOCKは指定できません。
独立性水準の初期値はシステム用の動作環境ファイルにおけるDEFAULT_ISOLATIONの指定に従います。
独立性水準の初期値をREAD UNCOMMITTEDとします。
独立性水準の初期値をREAD COMMITTEDとします。
独立性水準の初期値をREPEATABLE READとします。
独立性水準の初期値をSERIALIZABLEとします。
注意
動作環境ファイルのR_LOCKがNOの場合、DEFAULT_ISOLATIONにREPEATABLE_READを指定しても、独立性水準はSERIALIZABLEになります。
動作環境ファイルのR_LOCKがYESの場合、DEFAULT_ISOLATIONにSERIALIZABLEを指定しても、独立性水準はREPEATABLE READになります。
デバッグに関する実行パラメタ
DIV_TRACE_FILE = ({YES | NO})
複数のアプリケーションが動作する場合、出力ファイル名(SQL_SNAP機能やROUTINE_SNAP機能によって出力されるファイル、および、アクセスプラン情報やSQL性能情報を取得するファイル)の後ろに、プロセスIDなどの情報を付加して個別のトレース情報を出力するか否かを指定します。省略した場合は、NOが指定されたとみなします。
出力ファイル名の後に以下の情報を付加して個別のトレース情報を取得します。
- ログイン名
- プロセスID
- セション開始時間
出力ファイル名をsqlsnap.lstとし、ログイン名がtest、プロセスIDが288、セション開始時間が2007年4月16日12時34分56秒であるとした場合、以下のファイルに情報が出力されます。
sqlsnap_test_288_20070416123456.lst
個別のトレース情報を取得しません。
注意
アプリケーションがマルチスレッド環境で動作する場合は、DIV_TRACE_FILEの指定に関係なく、自動的に以下の情報を出力ファイル名の後に付加して、個別のトレース情報を出力します。
ログイン名
プロセスID
セションID
セション開始時間
ROUTINE_SNAP = ({ON | OFF},ルーチンスナップファイル名[,出力レベル])
ROUTINE_SNAP機能を利用するかどうかを指定します。省略した場合は、OFFが指定されたとみなします。
ROUTINE_SNAP機能は、SQL手続き文の実行情報をファイルに出力する機能です。
参照
ROUTINE_SNAP機能の詳細および使用方法については、“アプリケーション開発ガイド(埋込みSQL編)”の“アプリケーションのデバッグ”を参照してください。
ROUTINE_SNAP機能を利用する場合に指定します。
ROUTINE_SNAP機能を利用しない場合に指定します。
SQL手続き文の実行情報の出力先のサーバ側のファイル名を、絶対パスで指定します。指定されたファイルがすでに存在する場合は、情報を追加して出力します。
複数のアプリケーションが動作する場合は、クライアント用の動作環境ファイルの実行パラメタ(DIV_TRACE_FILE)の指定により、出力ファイル名の後にプロセスIDなどの情報を付加して、個別のトレース情報を出力します。
アプリケーションがマルチスレッド環境で動作する場合は、DIV_TRACE_FILEの指定に関係なく、出力ファイル名の後にプロセスIDやセションIDなどの情報を自動的に付加して、個別のトレース情報を出力します。
出力する情報のレベルとして、1または2を指定します。省略した場合は、2が指定されたとみなします。
参照
出力レベルの指定と出力情報の対応については、アプリケーション開発ガイド(埋込みSQL編)”の“ROUTINE_SNAP機能の利用方法”を参照してください。
SET_CALLBACK = (ライブラリ名)
動的ライブラリを使用してコールバック関数を登録する場合、動的ライブラリ名を指定します。
動的ライブラリ名が絶対パスでの指定でない場合は、以下のディレクトリにライブラリを格納する必要があります。
![]()
![]() 環境変数LD_LIBRARY_PATHに指定したディレクトリ
環境変数LD_LIBRARY_PATHに指定したディレクトリ
![]() PATHに指定したディレクトリ
PATHに指定したディレクトリ
SQL_SNAP = ({ON | OFF}[,[スナップファイル名][,[出力レベル][,[繰り返し幅]]]])
SQL_SNAP機能を利用するかどうかを指定します。省略した場合は、OFFが指定されたとみなします。
SQL_SNAP機能は、アプリケーションが実行したSQL文の情報をファイルに出力する機能です。
参照
SQL_SNAP機能の詳細および使用方法については、“アプリケーション開発ガイド(埋込みSQL編)”の“アプリケーションのデバッグ”を参照してください。
SQL_SNAP機能を利用する場合に指定します。
SQL_SNAP機能を利用しない場合に指定します。
SQL_SNAP機能が出力するSQL文の実行情報の出力先ファイル名を指定します。ファイル名を省略した場合は、アプリケーションのファイル名の拡張子を“.SNP”に変更したものとなります。ファイル名にディレクトリの指定がない場合は、カレントディレクトリが指定されたものとみなします。指定されたファイルがすでに存在する場合は、情報を追加して出力します。
複数のアプリケーションが動作する場合は、クライアント用の動作環境ファイルの実行パラメタ(DIV_TRACE_FILE)の指定により、出力ファイル名の後にプロセスIDなどの情報を付加して、個別のトレース情報を出力します。
アプリケーションがマルチスレッド環境で動作する場合は、DIV_TRACE_FILEの指定に関係なく、出力ファイル名の後にプロセスIDやセションIDなどの情報を自動的に付加して、個別のトレース情報を出力します。
出力する情報のレベルとして、1、2、PRC1、PRC2のいずれかを指定します。省略した場合は、2が指定されたとみなします。
参照
出力レベルの指定と出力情報の対応については、アプリケーション開発ガイド(埋込みSQL編)”の“SQL_SNAP機能の利用方法”を参照してください。
出力する情報の繰り返し幅として、1から32767を指定します。1つのSQL文の出力を1とします。繰り返し幅を指定した場合は、その幅でサイクリックに情報を出力します。省略した場合は、先頭からの情報をすべて出力します。
アクセスプラン・性能情報に関する実行パラメタ
ACCESS_PLAN = ({ON | OFF},ファイル名[,[出力レベル][,[SQLアドバイザ出力レベル]]])
アプリケーション単位でアクセスプランを取得するかどうかを指定します。本パラメタを省略した場合は、ACCESS_PLAN=(OFF)が指定されたものとみなします。
参照
アクセスプランについては、“3.1 アクセスプラン”を参照してください。
アクセスプラン取得機能を利用する場合に指定します。
アクセスプラン取得機能を利用しない場合に指定します。省略した場合は、OFFが指定されたものとみなします。
出力先のサーバ側のファイル名を、絶対パスで指定します。指定されたファイルがすでに存在する場合は、情報を追加して出力します。
また、指定するパスが存在することと、CONNECT文で指定したユーザIDに対する書込み権があることを確認してください。
出力レベルには1または2を指定します。1を指定すると、アクセスプランのセクション情報のみを出力します。2を指定すると、セクション内の各エレメント詳細情報も出力します。省略した場合は、2が指定されたものとみなします。
SQLアドバイザ出力レベルには、“ADVICE”または“NOADVICE”を指定します。“ADVICE”を指定すると、SQL文に対するアドバイスを出力します。“NOADVICE”を指定すると、SQL文に対するアドバイスを出力しません。省略した場合は、“ADVICE”が指定されたものとみなします。
SQL_TRACE = ({ON | OFF},性能情報ファイル名[,出力レベル])
アプリケーション単位でSQL性能情報を取得するかどうかを指定します。
SQL性能情報取得機能を利用する場合に指定します。
SQL性能情報取得機能を利用しない場合に指定します。省略した場合は、OFFが指定されたものとみなします。
出力先のサーバ側のファイル名を、絶対パスで指定します。指定されたファイルがすでに存在する場合は、情報を追加して出力します。
複数のアプリケーションが動作する場合は、クライアント用の動作環境ファイルの実行パラメタ“DIV_TRACE_FILE”の指定により、出力ファイル名の後にプロセスIDなどの情報を付加して、個別のトレース情報を出力します。
アプリケーションがマルチスレッド環境で動作する場合は、DIV_TRACE_FILEの指定に関係なく、出力ファイル名の後にプロセスIDやセションIDなどの情報を自動的に付加して、個別のトレース情報を出力します。
出力レベルには1または2を指定します。1を指定すると、DSOごとに集計された性能情報を出力します。2を指定すると、DSI単位の情報までも出力します。省略した場合は、2が指定されたものとみなします。
参照
出力レベルによる、出力内容の詳細については、“SQLTOOLユーザーズガイド”の“実行エレメント情報”を参照してください。
参照
以下の実行パラメタの詳細については、“SQLTOOLユーザーズガイド”を参照してください。
IGNORE_INDEX
INACTIVE_INDEX_SCAN
JOIN_ORDER
JOIN_RULE
SCAN_KEY_ARITHMETIC_RANGE
SCAN_KEY_CAST
SORT_HASHAREA_SIZE
SS_RATE
TID_SORT
TID_UNION
USQL_LOCK
メッセージに関する実行パラメタ
リカバリに関する実行パラメタ
予約語とSQL機能に関する実行パラメタ
SQL_LEVEL = ({SQL88 | SQL92 | SQL95 | SQL96 | SQL2000 | SQL2007})
アプリケーションの予約語とSQL機能のレベルを設定します。省略した場合は、SQL2007が指定されたとみなします。
予約語とSQL機能のレベルを設定することで、キーワードの範囲と利用可能なSQLの機能を変更できます。
SQLの機能とそれを利用可能なレベルとの関係を以下に示します。
表に記載のない機能は、SQL_LEVELに関係なく利用可能です。
SQL_LEVEL | SQLの機能 | |
|---|---|---|
SQL2007 | XMLQUERY関数 | |
述語 | XMLEXISTS述語 | |
ROWNUM | ||
SQL2000以上 | ファンクションルーチン | |
ロール | ||
プロシジャ例外事象 | 条件宣言 | |
ハンドラ宣言 | ||
SIGNAL文 | ||
RESIGNAL文 | ||
SQL96以上 | トリガ | |
行識別子 | ||
並列指定 | ||
SQL95以上 | プロシジャルーチン | |
SQL92以上 | 定数 | 日時定数 |
時間隔定数 | ||
データ型 | 日時型 | |
時間隔型 | ||
BLOB型 | ||
順序定義 | ||
一時表定義 | ||
数値関数 | POSITION | |
EXTRACT | ||
CHAR_LENGTH | ||
CHARACTER_LENGTH | ||
OCTET_LENGTH | ||
データ列値関数 | SUBSTRING | |
UPPER | ||
LOWER | ||
TRIM | ||
日時値関数 | CURRENT_DATE | |
CURRENT_TIME | ||
CURRENT_TIMESTAMP | ||
CAST指定 | ||
CASE式 | NULLIF | |
COALESCE | ||
CASE | ||
結合表 | ||
カーソルのSCROLL指定 | ||
ポイント
SQL2007の関数名と同名のファンクションルーチンを定義している場合、関数とファンクションルーチンの動作の優先順位は以下になります。
ファンクションルーチン名へのスキーマ名修飾の有無 | SQL_LEVEL | |
|---|---|---|
SQL2007 | SQL2000 | |
スキーマ名修飾有 | ファンクションルーチン | ファンクションルーチン |
スキーマ名修飾無 | 関数 | ファンクションルーチン |
SQL文にSQL2007の関数名と同名のファンクションルーチンを指定している場合、関数が優先して動作することで、ファンクションルーチンの結果と異なる結果になる場合があります。
ファンクションルーチンの動作を優先する場合は、SQL_LEVELにSQL2000を指定するか、ファンクションルーチン名をスキーマ名修飾してください。
コンパイル時にRオプションまたはWオプションで予約語とSQL機能のレベルが指定されていた場合も、本パラメタで指定された値が有効となります。
並列クエリに関する実行パラメタ
その他の実行パラメタ
ALTER_CHECK=({YES | NO})
表の設計変更により表の列を変更した場合に、アプリケーションに影響があるか否かをチェックします。省略した場合はNOが指定されたとみなします。
本実行パラメタは、Symfoware Server Enterprise Extended Edition を使用した場合のみ指定できます。
選択リストに“*”を指定したカーソル宣言または単一行SELECT文や、挿入列リストを省略したINSERT文の実行をチェックします。これらのSQL文の実行がエラーになります。
選択リストに“*”を指定したカーソル宣言または単一行SELECT文や、挿入列リストを省略したINSERT文に対するチェックをせずに実行します。
ARC_FULL = ({RETURN | WAIT})
エラーとしてアプリケーションに復帰します。
空きのアーカイブログファイルが作成されるまで待ちます。
注意
“WAIT”を指定した場合、空きのアーカイブログファイルが作成されるまでアプリケーションは無応答状態となりますので注意してください。
また、本実行パラメタの指定が互いに異なる複数のアプリケーションが、同時に同じDSIを扱うような運用はしないでください。例えば、以下の事象が発生する場合があります。
トランザクションAは、ARC_FULL=RETURNを設定し、アーカイブログ満杯の状態であるとします。トランザクションBは、ARC_FULL=WAITを設定し、アーカイブログ満杯の状態で資源を占有しているとします。このとき、トランザクションBは、空きのアーカイブログファイルが作成されるまで待ちます。同じ資源にアクセスしているトランザクションAは、トランザクションBの終了を待つため、ARC_FULL=RETURNを設定しているにもかかわらず、無応答状態になります。
この場合は、rdblkinfコマンドのlオプションやrdblogコマンドのVオプションかつaオプションで排他やアーカイブログの状況を確認できます。また、アーカイブログに関する以下のシステムメッセージが表示されます。これらの情報をもとに、バックアップ可能なアーカイブログファイルをバックアップするか、または新規にアーカイブログファイルを追加して対処してください。
rdb: WARNING: qdg13336w:転送可能なアーカイブログ域が不足しています rdb: ERROR: qdg03132u:アーカイブログファイルが満杯です
以下のいずれかの処理中にシステムロググループまたはユーザロググループのアーカイブログファイルが満杯状態になった場合の振る舞いについては、本実行パラメタの指定に関わらずシステム用の動作環境ファイルに指定したARC_FULLパラメタに従います。
・SQL文の実行で自動容量拡張が動作する。
・SQL文中に順序を直接指定して番号を採番する。
・表定義のDEFAULT句に順序を指定して、自動的に取得した値を表に挿入する。