Data Effectorのコマンドでは、以下に示す拡張的な使い方もできます。
CPUやメモリなどの資源に余裕があり、入力ファイルを分散配置できる環境下では、大量のファイルを高速に処理する業務要件があります。このように、入力ファイルが複数の場合、同時に処理する数を指定することで、処理を高速化できます。
並列数は、各動作環境ファイルのParallelNumパラメタで設定します。
以下に、並列処理の概要を示します。
図5.2 並列処理の概要
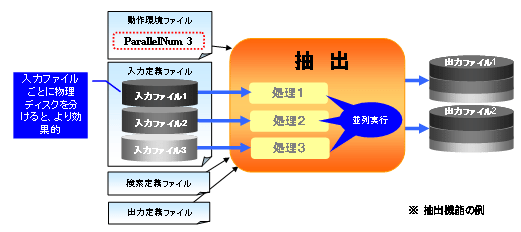
抽出機能を使って結果を複数ファイルに仕分けして、その結果をそれぞれ集計するなどの処理を組み合わせてファイルを受け渡す場合、入出力ファイルに名前付きパイプを使用すると、受渡し時に中間ファイルを使用せず効率的に実行できます。
ポイント
名前付きパイプとは、プログラム同士がデータをやり取りできるようにした、プロセス間通信の1手法です。
名前付きパイプの指定例については、“5.6.3 名前付きパイプの指定例”を参照してください。
以下に、名前付きパイプの概要を示します。
図5.3 名前付きパイプの概要
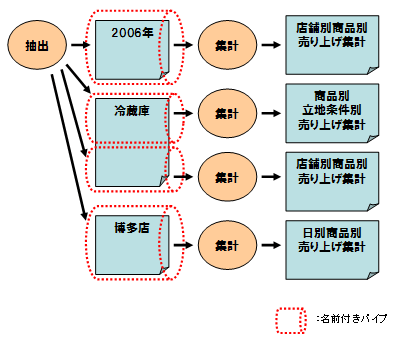
名前付きパイプは、入出力ファイルの先頭に“pipe@”を記述することで、使用できます。
![]() “pipe@”の後に、名前付きパイプの書式“¥¥.¥pipe¥名前付きパイプ名”を指定してください。
“pipe@”の後に、名前付きパイプの書式“¥¥.¥pipe¥名前付きパイプ名”を指定してください。
注意
スキーマ情報ファイルおよび入力マスタファイルには、名前付きパイプを指定できません。ファイル名の先頭に"pipe@"を記述してもファイル名の一部と認識します。
以下に、入力定義ファイルでの名前付きパイプの指定例を示します。
![]() Windowsの場合
Windowsの場合
## 入力定義ファイル SchemaFile D:¥Shunsaku¥data¥schema.csv DataFile pipe@¥¥.¥pipe¥named_pipe_data |
![]()
![]() Linux/Solarisの場合
Linux/Solarisの場合
## 入力定義ファイル SchemaFile /home/shunsaku/data/schema.csv DataFile pipe@/home/shunsaku/data/named_pipe_data |
ポイント
入出力ファイルが1つの場合は、標準入出力で処理可能です。
標準入出力の例については、“5.6.1 抽出、連結および集計のコマンド組合せ例”または“5.6.2 抽出およびソートのコマンド組合せ例”を参照してください。