スマートワークロードリカバリ機能のシステム構成を説明します。システム構成に基づいて、AWS環境の設計および導入を行ってください。なお、導入手順については“A.2 導入”を参照してください。
ポイント
スマートワークロードリカバリの概要は、“PRIMECLUSTER コンセプトガイド”の“1.9 スマートワークロードリカバリ”を参照してください。
AWSのリソースやサービスについての詳細は、AWSの公式ドキュメントを参照してください。
システム構成
スマートワークロードリカバリは、運用系だけで待機系を持たないシングルノードのクラスタシステムです。異常発生時にクラスタノードのインスタンスが動作しているアベイラビリティゾーンからインスタンスを削除して、別のアベイラビリティゾーンで新たなインスタンスを起動します。切替え先にするアベイラビリティゾーンは、事前にサブネットなどのネットワーク環境を構築する必要があります。
リソース監視機構と切替機構は、AWS CloudWatchやAWS Lambdaなどのサービスと連携して、インスタンスの切替えを実現しています。クラスタノードのインスタンスと切替え先のサブネットはタグで認識します。そのため、インスタンスとサブネットに指定のタグを設定します。
図A.1 システム構成
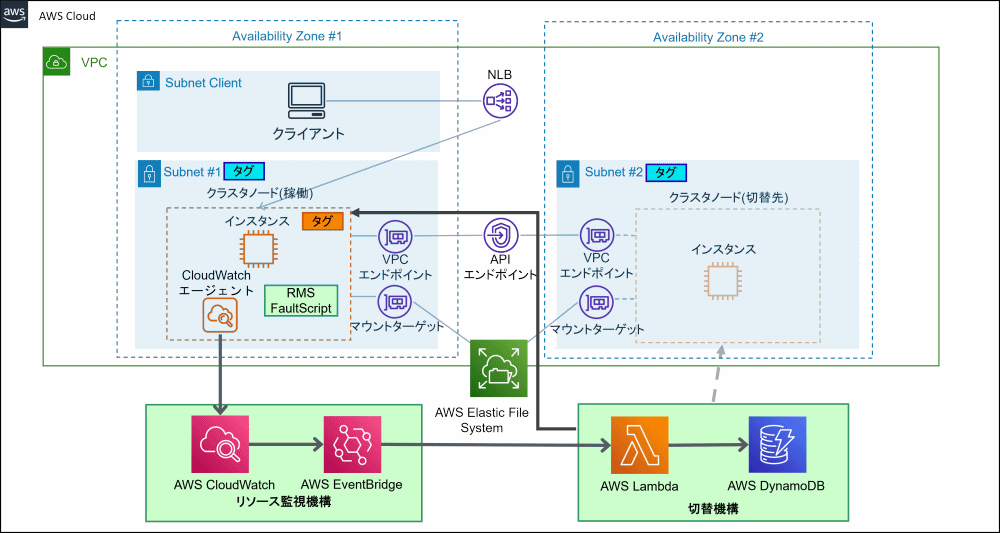
コンポーネント
各コンポーネントの説明を、以下に示します。また、AWS環境の設計や導入時に必要な作業についても、概要を説明します。なお、以下に記載された導入時に必要な作業は、“A.2 導入”以降で実施します。
ネットワーク
ネットワークの構成は、1つのAmazon Virtual Private Cloud(VPC)において切替え対象にするアベイラビリティゾーンごとにサブネットを作成して、ネットワークの引継ぎのためにElastic Load Balancing(ELB)のNetwork Load Balancer(NLB)、またはApplication Load Balancer(ALB)を配置します。また、CloudWatchエージェントがAmazon CloudWatchのサービスにアクセスできるように、APIエンドポイントとの接続を確保します。
切替機構がインスタンスを再配備するサブネットとして認識できるように、対象のサブネットにタグを設定します。サブネットのタグについては、“A.2.1.1 VPCとサブネットの作成”で説明しています。
注意
ネットワークの引継ぎは、NLBまたはALBのどちらも選択できます。設計や導入の図は、一例としてNLBを使用して説明します。
セキュリティグループ
ユーザのセキュリティ要件に応じてセキュリティグループを設計してください。
また、すべてのトラフィックを遮断するセキュリティグループとして、ブラックホールセキュリティグループを用意します。切替機構は、異常発生時にクラスタノードのインスタンスが動作しているアベイラビリティゾーンからインスタンスを削除して、別のアベイラビリティゾーンで新たなインスタンスを起動します。削除するインスタンスにブラックホールセキュリティグループを設定することで、クラスタノードを隔離します。
ディスク
共用するデータはEFSに配置します。切替え対象にするアベイラビリティゾーンごとに、EFSのマウントターゲットを作成します。
導入では、RMSのログを格納するために、EFSのファイルシステムを作成します。また、ユーザが共用するデータを格納する場合は、別にEFSのファイルシステムを作成します。
インスタンス
クラスタノードとなるインスタンスのAMIを用意します。AMIのインスタンスを作成して、アプリケーションの異常を検知するためにPRIMECLUSTERのRMSをインスタンスにインストールし、FaultScriptを作成および登録します。また、インスタンスのメトリクスとログをリソース監視機構のAmazon CloudWatchに渡すため、CloudWatchエージェントをインスタンスにインストールします。必要なソフトウェアをインストールしたあとに、インスタンスのイメージを作成します。
切替機構がクラスタノードのインスタンスを認識できるように、対象のインスタンスにタグを設定します。
リソース監視機構
リソース監視機構はAmazon CloudWatchおよびAmazon EventBridgeの総称です。インスタンスからメトリクスとログを収集するために、Amazon CloudWatchと連携しています。また、切替機構にインスタンスの異常をイベントとして通知するため、Amazon EventBridgeと連携しています。
導入では、CloudWatch アラームとAmazon EventBridgeのルールを追加する作業を実施します。
切替機構
切替機構は、対象のインスタンスに異常が発生したことをAmazon EventBridgeのイベントで検知します。イベントの検知後、AWS Lambdaは、異常が発生していないアベイラビリティゾーンのサブネットに、インスタンスを再配備します。切替機構の保持するデータはAmazon DynamoDBに格納します。
導入では、AWS Lambdaの関数とAmazon DynamoDBのテーブルを登録する作業を実施します。
ポイント
複数のリソースを作成する場面について
スマートワークロードリカバリを設計するときに、同じ種類のリソースを複数用意する場面があります。その場面がどのような場合であるかを、以下に説明します。また、その場面でどのようにスマートワークロードリカバリを設計するかも、以下に説明します。
リージョン
複数のリージョンを使用する場合は、以下のように設計してください。
切替機構のAmazon DynamoDB
1つのリージョンに対して、Amazon DynamoDBのテーブルを1つ用意してください。
クラスタノードのインスタンスに設定するタグ([fujitsu.pclswr.id]キー)
タグの[fujitsu.pclswr.id]キーには、インスタンスごとに重複しない整数値を指定します。重複しない整数値は、リージョンごとに重複しない値を指定してください。
VPC
複数のVPCを使用する場合は、以下のように設計してください。
ブラックホールセキュリティグループ
1つのVPCに対して、ブラックホールセキュリティグループを1つ用意してください。
切替機構のAWS Lambda
1つのVPCに対して、AWS Lambdaの関数を1つ用意してください。
切替機構のAmazon EventBridge
1つのVPCに対して、Amazon EventBridgeのイベントを1セット(イベントは2つ)用意してください。
クラスタノードのインスタンス
複数のクラスタノードのインスタンスを使用する場合は、以下のように設計してください。
ELB
1つのインスタンスに対して、ELBのNLBまたはALBを1つ用意してください。
EFS
1つのインスタンスに対して、共用するデータを格納するEFSを用意してください。
リソース監視機構のAmazon CloudWatch
1つのインスタンスに対して、Amazon CloudWatchのアラームを1セット(アラームは2つ)用意してください。
動作
AWS環境でスマートワークロードリカバリ機能を使用したシステムにおけるクラスタアプリケーション異常/RMS異常発生時の各コンポーネントの動作は以下のとおりです。
図A.2 AWS環境におけるスマートワークロードリカバリ機能の動作
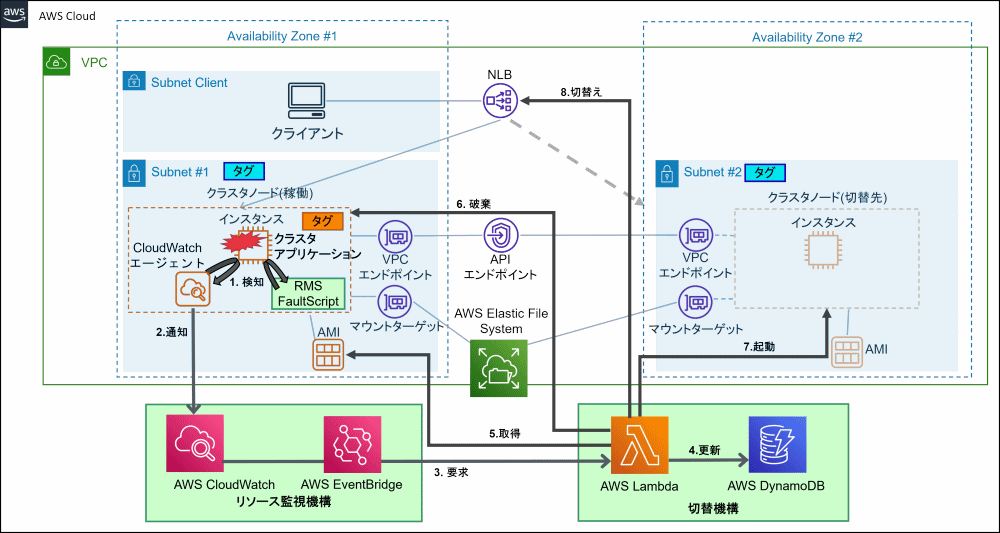
RMSがクラスタアプリケーションの異常を検知
RMSがFaultScriptを実行し、インスタンスを停止することで、リソース監視機構に通知
リソース監視機構は異常を受け付けると、切替機構に対して切替えを要求
切替機構はAmazon DynamoDBのテーブルを更新
切替機構は切替え元のインスタンスのAMIを取得
切替機構は切替え元のインスタンスを破棄
切替機構は切替え元とは異なる任意のアベイラビリティゾーンでインスタンスを起動
切替機構はロードバランサのターゲットグループのインスタンスの切替えを実施
CloudWatchエージェントがRMSの異常を検知
CloudWatchエージェントがリソース監視機構に通知
リソース監視機構は異常を受け付けると、切替機構に対して切替えを要求
切替機構はAmazon DynamoDBのテーブルを更新
切替機構は切替え元のインスタンスのAMIを取得
切替機構は切替え元のインスタンスを破棄
切替機構は切替え元とは異なる任意のアベイラビリティゾーンでインスタンスを起動
切替機構はロードバランサのターゲットグループのインスタンスの切替えを実施
切替え時にインスタンスには以下が引き継がれます。
AMI ID
インスタンスタイプ
キーペア名
セキュリティグループID
タグ
IAMロール
CloudWatchアラーム
RMSのログ
ユーザの共用データ
注意
インスタンスの切替え時に、切替え先インスタンスに引き継がれることが保証されるCloudWatchアラームは、リソース監視機構に必要なCloudWatchアラームのみです。