This subsection describes the system configuration of the smart workload recovery feature. Design and deploy your AWS environment based on your system configuration. For deployment instructions, see "A.2 Installation".
Point
For an overview of smart workload recovery feature, see "1.9 Smart workload recovery" in the "PRIMECLUSTER Concept Guide".
For more information about AWS resources and services, see the official AWS documentation.
System configuration
Smart workload recovery is a single-node cluster system that is operational only and does not have a standby system. Remove the instance from the AZ in which the cluster node instance is running in the event of failure and launch a new instance in another AZ.
Before you can switch to an AZ, you must create a network environment, such as a subnet.
Resource monitor and switcher work with services such as AWS CloudWatch and AWS Lambda to provide instance switching. The tag identifies the cluster node instance and the subnet to which it switches. Therefore, you set the specified tags on your instances and subnets.
Figure A.1 System configuration
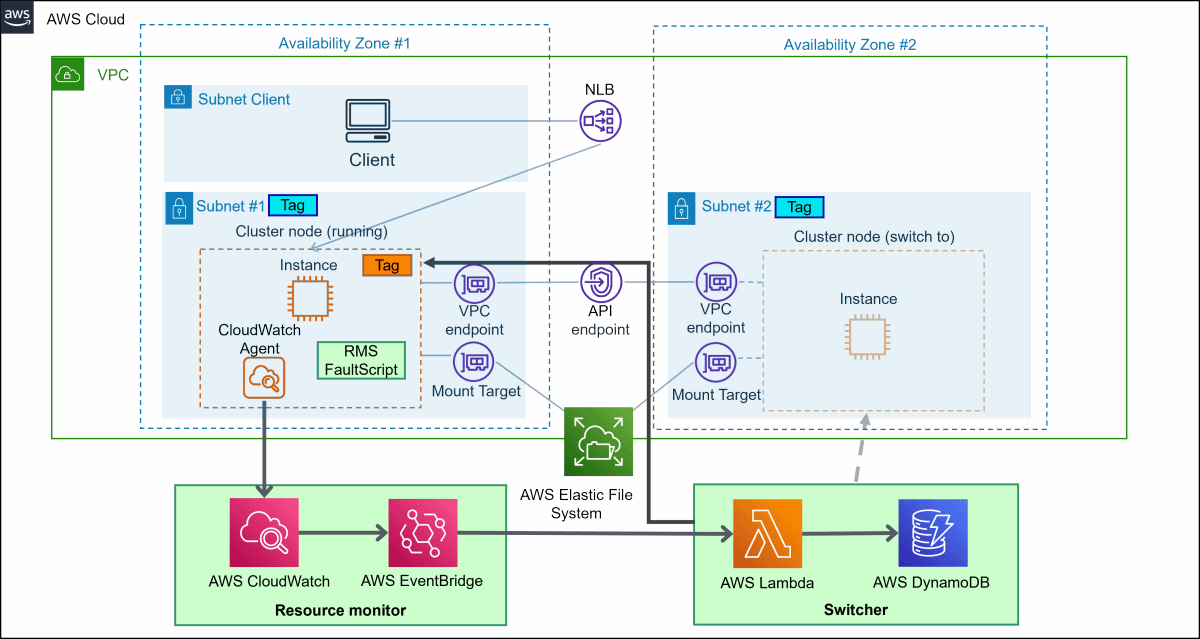
Component Description
A description of each component is provided below. It also provides an overview of the tasks required to design and deploy an AWS environment. The tasks described below that are required at the time of implementation are performed in "A.2 Installation" and later.
Network
Network configuration involves deploying an Elastic Load Balancing (ELB) Network Load Balancer (NLB) or an Application Load Balancer (ALB) for network handover by creating a subnet for each AZ that you want to switch over in a single Amazon Virtual Private Cloud (VPC). It also ensures connectivity with API endpoints so that CloudWatch Agent can access Amazon CloudWatch services.
Tag the subnet so that switcher recognizes it as the subnet on which you want to redeploy the instance. Subnet tags are described in "A.2.1.1 Creating VPC and Subnet".
Note
You can select either NLB or ALB for network takeover. The design and implementation diagrams are illustrated using NLB as an example.
Security groups
Design your security groups according to your security requirements.
You also have a blackhole security group as a security group that blocks all traffic. Switcher removes an instance from the AZ in which the cluster node instance is running in the event of failure and launches a new instance in a different AZ. Quarantine a cluster node by configuring a blackhole security group on the instance that you want to delete.
Disk
You place the data that you want to share on EFS. Create a mount target for EFS for each AZ that you want to switch.
The deployment creates an EFS file system to store RMS logs. If you want to store data that users share, create a separate file system for EFS.
Instance
Prepare an AMI for the instance that will be your cluster node. Create an instance of the AMI, install RMS of PRIMECLUSTER on the instance to detect error in the application, and create and register FaultScript. You also install a CloudWatch Agent on the instance to pass metrics and logs for the instance to Amazon CloudWatch, resource monitor. After you install the required software, you create an image of your instance.
Tag the instances so that switcher can recognize them.
Resource monitor
Resource monitor is collectively referred to as Amazon CloudWatch and Amazon EventBridge. It works with Amazon CloudWatch to collect metrics and logs from your instances. It also works with Amazon EventBridge to notify switcher of instance error as events.
The deployment involves adding CloudWatch Alarm and Amazon EventBridge rules.
Switcher
Switcher detects failure in the target instance with an event in Amazon EventBridge. After the event is detected, AWS Lambda redeploys the instance to the subnet in the unhealthy AZ. You store the data held by switcher in Amazon DynamoDB.
The deployment involves registering your AWS Lambda function and your Amazon DynamoDB table.
Point
About Creating Multiple Resources
When you design a smart workload recovery feature, you might have multiple resources of the same type. The situation is described below. Here's how to design a smart workload recovery feature in that situation.
Region
If you want to use multiple regions, design them as follows.
Amazon DynamoDB as a Switcher
You must have one Amazon DynamoDB table for each region.
Tags to set for instances on cluster nodes ([fujitsu.pclswr.id] key)
The [fujitsu.pclswr.id] key in the tag must be a unique integer value for each instance. Unique integer values must be unique for each region.
VPC
If you use multiple VPCs, design them as follows.
Blackhole Security Group
You must have one Blackhole security group for each VPC.
Switcher for AWS Lambda
You must have one AWS Lambda function for each VPC.
Switcher for Amazon EventBridge
You must have one set of Amazon EventBridge events (two events) for each VPC.
Cluster node instances
When using instances of multiple cluster nodes, design as follows.
ELB
Prepare a NLB of ELB or ALB for an instance.
EFS
Prepare an EFS to store the data that you want to share for an instance.
Amazon CloudWatch for Resource monitor
You must have one set of Amazon CloudWatch Alarm (two alarms) for each instance.
Operation
The following describes the behavior of each component when a cluster application error/RMS error occurs in a system using the smart workload recovery feature in an AWS environment.
Figure A.2 How smart workload recovery works in AWS environment
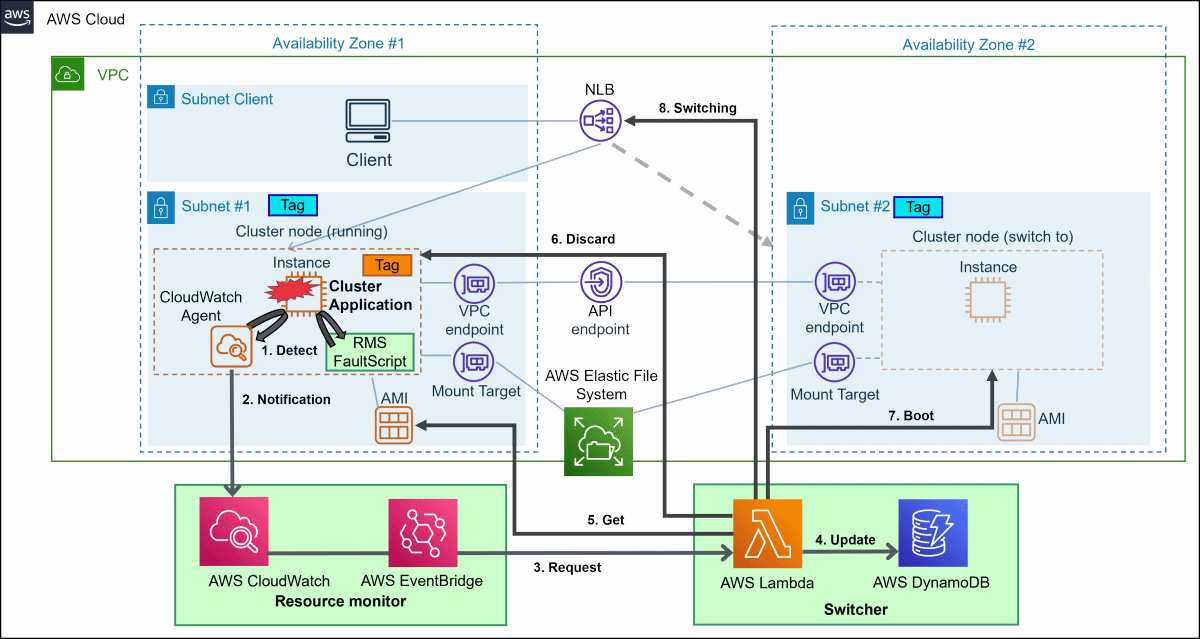
RMS detects cluster application error
RMS notifies resource monitor by running FaultScript and shutting down the instance
When resource monitor receives an error, it requests switcher to switch.
Switcher Updates tables in Amazon DynamoDB
Switcher retrieves the AMI of the instance from which it was switched
Switcher destroys the switching instance
Switcher launches instances in any AZ that is different from the source
Switcher switches instances of load balancer target groups
CloudWatch Agent detects RMS error
CloudWatch Agent notifies resource monitor
When resource monitor receives an error, it requests switcher to switch
Switcher updates tables in Amazon DynamoDB
Switcher retrieves the AMI of the instance from which it was switched
Switcher destroys the switching instance
Switcher launches instances in any AZ that is different from the source
Switcher switches instances of load balancer target groups
The instance inherits the following when you switch.
AMI ID
Instance type
Key pair name
Security group ID
Tags
IAM Role
CloudWatch Alarm
RMS log
User's shared data
Note
When you switch instances, only CloudWatch Alarm required by resource monitor are guaranteed to be carried over to the switched instance.