データ管理機能は、様々なデータソースから収集したデータをスキーマレスで管理・加工し、検索機能で使用するデータを事前に準備します。
データの構造(スキーマ)を意識せず、そのままの形式で収集したデータを、使いたい項目だけを抽出・加工することで、検索用のデータの準備が容易にできます。
大量データから絞り込みや項目編集/結合をした検索用ファイルは、ディスク検索用データ格納ディレクトリ、または、インメモリ検索用データに取り込んでメモリ上に格納します。
スキーマレス加工では、以下の機能があります。これらは組合せが自由で、データ加工に必要な条件を指定して実行するだけです。
機能名 | 概要 |
|---|---|
抽出 | 検索条件に一致するデータを抽出し、結果をファイルに出力します。検索条件には、以下があります。
|
連結 | 入力ファイルと他のファイルを連結条件に合わせて結合・編集し、結果をファイルに出力します。
|
集計 | 入力ファイルのデータを任意のグループごとに集計し、結果をファイルに出力します。 |
ソート | 入力ファイルのデータを任意の項目ごとにソートし、結果をファイルに出力します。 |
本機能は、XML文書またはCSVファイルを入力とし、必要な加工処理を施してXML文書またはCSVファイルを出力します。
また、各機能を実現するインターフェースは、以下の2つを提供しています。
コマンド
C APIの関数
参照
スキーマレス加工の詳細については、“加工編 導入・運用ガイド”を参照してください。
スキーマレス加工のアプリケーション開発については、“7.2 データを管理する”を参照してください。
並列分散処理では、長時間かかっても処理できなかった大量のデータや繰り返しの多い複雑な処理を、数十~数千台のサーバで分散処理することによって、短時間で処理できます。
並列分散処理では、以下の機能があります。
機能名 | 概要 |
|---|---|
マスタサーバ | 大量のデータファイルをブロックに分けた上でファイル化(分散ファイルシステム)し、そのファイル名や保管場所を一元管理します。 |
スレーブサーバ | マスタサーバによってブロック化されたデータファイルを処理するサーバです。複数のスレーブサーバが並列分散処理することによって、短時間に分析処理を行います。 |
開発実行環境サーバ | 並列分散を行うMapReduceアプリケーション、Sparkアプリケーション、Hiveクエリを実行するサーバです。 |
本機能では、以下のOSSを標準装備します。
Apache Hadoopは、ビッグデータの効率的な分散・並列処理を行うOSSです。
Apache Hadoopの分散ファイルシステム(Hadoop Distributed File System。以降は、HDFSと略します)を利用し、大量データを分割かつ、数十~数千台のサーバに分散配置して並列処理することによって、大量のデータに対するバッチ処理を短時間で実施できます。
本製品がサポートするApache Hadoop機能については“B.2 Apache Hadoopの機能”を参照してください。
Apache Spark は、メモリ上で大規模データ加工が行えるクラスタコンピュータシステムです。
メモリ上に展開したデータを再利用することにより、複雑な処理を並列分散処理で高速に実行できます。
本製品がサポートするApache Spark機能については、“B.3 Apache Sparkの機能”を参照してください。
SQLライクなクエリ言語で分散・並列処理を実行できるOSSです。
以下の特長があります。
SQLライクなクエリ言語(Hive QL)
スキーマ情報をメタストアデータベースに格納し、SQLライクなHive QLで記述したクエリで並列分散処理が実行できます。
複数ユーザーでスキーマ情報を共有するため、別途導入したRDBMSをメタストアデータベースとして利用することを推奨します。
各種実行エンジンのサポート
MapReduce以外に、Apache Sparkの実行エンジンをサポートしています。
本製品がサポートするApache Hive機能については、“B.4 Apache Hiveの機能”を参照してください。
注意
並列分散処理は、複数のサーバを使って分散処理しますので、単一サーバ構成では使用できません。
参照
Apache Hadoop、Apache SparkおよびApache Hiveの詳細情報については、OSSのオンラインドキュメントを参照してください。
本製品での並列分散処理の使い方については、“分散処理編 ユーザーズガイド”を参照してください。
組織横断のデータ活用を支援するために、データのアクセシビリティ向上、データ品質の可視化、およびデータのセキュリティを確保するデータガバナンス機能を提供します。本機能は並列分散処理機能と一緒に提供されます。
収集・加工したデータを業務と紐づけ、組織のデータ管理ルールに沿って管理することで、組織横断のデータ活用を支援します。
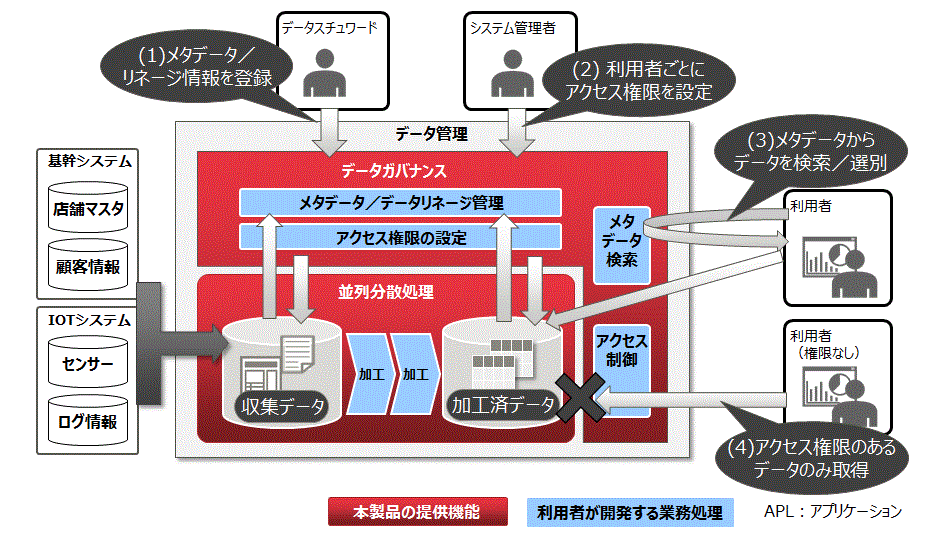
データ管理者がスキーマ情報や業務上の意味、作成者などのデータ自体を説明する情報(メタデータ)を、格納したデータに付与することで、データの利用者が必要なデータの検索ができます。また、収集データからどのような加工・変換されてデータが作成されたのかに関する来歴情報(データリネージ)を記録することで、データの信頼性をデータの作成者以外でも確認することができ、品質の高いデータを利用できます。
本機能では、以下のOSSを標準装備します。
Apache Atlasは、データ活用に不可欠なメタデータやデータリネージといった情報を蓄積できるOSSです。Apache Atlasを使って、メタデータの登録・参照、データの分類、および、データリネージの記録が実施できます。
本製品がサポートするApache Atlas機能については、“B.5 Apache Atlasの機能”を参照してください。
組織のアクセスルールに従って、ディレクトリやファイル単位、テーブルやカラム単位でアクセス権を付与し、機密情報を含むデータでも安全に活用できます。
セキュリティ管理では、以下の機能があります。
機能名 | 概要 |
|---|---|
アクセスポリシーによるアクセス制御 | Apache Hadoopが保持するデータに対して柔軟なアクセス制御を実施できます。 |
監査ログの記録 | 利用者のデータ操作を記録することができます。 |
本機能では、以下のOSSを標準装備します。
Apache Rangerは、データに対する柔軟なアクセス制御や監査ログを記録することができるOSSです。
本製品がサポートするApache Ranger機能については、“B.6 Apache Rangerの機能”を参照してください。
注意
セキュリティ管理機能は、並列分散処理上で動作しますので、単一サーバ構成では使用できません。
ポリシー定義の管理を行うためのデータベースソフトウェアのインストールが別途必要です。詳細については“3.2.3.3.2 セキュリティ管理を使用する場合”を参照してください。
参照
Apache Rangerの詳細情報については、OSSのオンラインドキュメントを参照してください。
本製品でのアクセス制御の使い方については、“分散処理編 ユーザーズガイド”を参照してください。