運用時、電源が切断されたり、システムが強制停止された場合のトラブルについて対処法を説明します。
■トラブル一覧
No. | 現象 | Solaris | Linux |
|---|---|---|---|
クラスタシステム運用中、突然ノードの AC 電源が切断された場合、電源切断されたノードに LEFTCLUSTER 状態が設定され、コンソールが切断された | ○ | - | |
クラスタシステム運用中、誤って Break 信号を送信してしまった、STOP-A を押下してしまった、または、RCCU を電源断してしまったために OBP モードとなってしまった | ○ | - | |
3 ノード以上のクラスタ構成において、RCI 故障中に 2 ノード以上で同時にノード異常が発生し、異常の発生したノードの CF ノード状態が LEFTCLUSTER のままとなり、コンソールが切断されてしまった | ○ | - | |
RCI の故障中にクラスタインタコネクトの全パス故障またはシステムハングが発生したが、ノードが OBP モードに移行しなかった | ○ | - | |
他ノードから、強制停止(reset)させられた | ○ | - | |
他ノードから、強制停止(panic)させられた | ○ | ○ | |
運用中にパニックされていないにもかかわらず、パニックを検出した旨の以下のメッセージが出力された | ○ | - | |
運用ノードの Request スイッチを押しても、フェイルオーバが発生しない | ○ | - | |
クラスタインタコネクトをすべて抜いた際に LEFTCLUSTER となるが、RCI 経由のパニックに失敗する | ○ | - | |
待機ノードが PANIC した | ○ | - | |
ノード強制停止が失敗し、以下の RMS のメッセージが出力された | ○ | ○ | |
クラスタシステム運用中、ノード異常が発生してもフェイルオーバが発生しない | - | ○ | |
/var/opt/SMAWsf/log/SA_pprcir.log に以下のメッセージが表示され、RCI 経由でのリセット指示ができない | ○ | - | |
運用中に OBP プロンプトになっていないにもかかわらず、OBP プロンプトを検出した旨の以下のメッセージが出力された | ○ | - | |
クラスタのスプリットブレイン時に優先度の高いノードが強制停止された | ○ | ○ | |
クラスタアプリケーションの強制起動(hvswitch -f)を実行した直後に、他のノードが強制停止された【Solaris版 PRIMECLUSTER 4.3A10以降、またはLinux版 PRIMECLUSTER 4.3A30以降】 | ○ | ○ | |
SPARC M10、M12 のゲストドメイン間クラスタ環境において、ゲストドメインで OS パニック / リセット / OS ハング/クラスタインタコネクト断が発生した場合に制御ドメインが強制停止される | ○ | - | |
SPARC M10、M12 環境において、OS パニック / リセット / OS ハング/ クラスタインタコネクト断が発生した場合に強制停止に失敗する | ○ | - | |
PRIMEQUEST 環境において、OS パニック / リセット / OS ハング / クラスタインタコネクト断が発生した場合に、 SA_mmbp シャットダウンエージェントの強制停止状態が KillFailed になり、 SA_mmbr シャットダウンエージェントの強制停止状態が KillWorked になる | - | ○ | |
I/O フェンシング機能を使用する環境で、運用ノードが OS パニックから再起動する際に共用ディスクを認識できず、syslog に以下の GDS のエラーメッセージが出力される | ○ | ○ | |
RHOSP のコンピュートインスタンスの高可用設定を使用する環境において、コンピュートノード異常時に、クラスタノードのインスタンスが、他のコンピュートノードに移動されない | - | ○ | |
シャットダウン機構の再起動時を行った際に/var/log/messages に以下のいずれかのメッセージが出力された | - | ○ | |
クラスタノードにリセットやパニックなどのノード異常が発生したにもかかわらず、強制停止が行われなかった | - | ○ | |
FJcloud-ベアメタル環境において、ノードが停止したにもかかわらず、フェイルオーバが発生しなかった | - | ○ |
ノードの電源が実際に切断されていることを確認した後、cftool -k コマンドによりノードの状態を DOWN にしてください。
その後、コンソールを再接続し、ノードに電源を投入してください。
既存の生存ノードで cftool -n を発行し、OBP モードに移行したノードの状態が DOWN であるかを確認してください。
DOWN でない場合は、cftool -k を発行し、OBP モードに移行したノードの状態を DOWN にした後、以下のいずれかの対処を実施してください。
ok プロンプトから boot コマンドを実行してください
該当ノードの電源を落とし、再度電源を投入して起動してください
コンソールを再接続し、実際にノードが異常状態にあることを確認してから、cftool -k を発行しノードの状態を DOWN にしてください。
全ノードの /var/adm/messages を参照し、以下のエラーメッセージが出力されていないか確認してください。
FJSVcluster: エラー: 7040: コンソールへの接続ができなくなりました。(node:nodename portno:portnumber detail:code)
FJSVcluster: エラー: 7042:コンソールへの接続ができません。(node:nodename portno:portnumber detail:code)
上記エラーメッセージが出力されている場合はそのエラーメッセージの対処法に従ってください。上記エラーメッセージが出力されていない場合は、原因として以下の可能性が考えられます。
モードスイッチが SECURE になっている (PRIMEPOWER 200,400,600 の場合のみ)
この場合、モードスイッチを AUTO にしてください。
/etc/default/kbd で以下の行が有効になっている
KEYBOARD_ABORT=disable または KEYBOARD_ABORT=alternate
この場合、以下の行をコメントアウトし、ノードを再起動してください。
KEYBOARD_ABORT=disable または KEYBOARD_ABORT=alternate
RCCU のアカウントまたは スーパーユーザのパスワードが設定されている (PRIMEPOWER 4.1 または 4.1A10 で、パッチ 912745-02 を適用していない場合のみ)
この場合、RCCU のアカウントまたはスーパーユーザのパスワードを削除してください。削除方法については、"リモートコンソール接続装置 取扱説明書" を参照してください。
RCCU の電源断などにより、運用中に突然 ok プロンプトになった場合、他のノードからノードの状態確認が行えなえず、クラスタ整合状態ではないと判断され、シャットダウン機構により強制停止 (reset) が行われます。
このトラブルは、PRIMECLUSTER 4.0 のみ対象となります。
運用中に、RCCU の電源を切断しないでください。
RMS 間の heartbeat が切断されたため、相手ノードを強制停止した可能性があります。Heartbeat が切断された原因としては以下の場合があります。
RMS の動作に支障があるため、hvdet_system プロセスを使用して監視するリソースを減らしてください。
RMS が必要とするメッセージキューパラメタ値が不足しているためにノード間通信が失敗し、パニックが発生した可能性があります。
/etc/system の msgsys:msginfo_msgtql の値を 65535 以上に変更してください。
CF 間の heartbeat が切断されたため、相手ノードから強制停止された可能性があります。Heartbeat が切断された原因としては以下の場合があります。
Linux
プロセスの動作優先度(nice値)を keventd、events、または kworker *1) の優先度よりも高くチューニングしているプロセス群(スレッドを含む)が、CFのハートビート処理の監視時間を超えてCPUを占有しています。
*1)ワークキューに登録した処理タスクを実行する汎用のカーネルスレッドです。PRIMECLUSTER のハートビート処理は、このカーネルスレッドを使用しています。
nice値は、RHEL4 では -10 (keventd)、RHEL5 では -5 (keventd)、RHEL6 では 0 (events)、RHEL7 以降では 0 (kworker) が設定されています。
nice 値の変更により CPU を長時間占有する可能性のあるプロセスの動作優先度を高くする場合、nice値を RHEL4 では -10 より大きな値、RHEL5 では -5 より大きな値に設定してください。
また、RHEL6 以降では CPU を長時間占有する可能性のあるプロセスの動作優先度を高くしないでください。
SF (シャットダウン機構) の設定において、コンソール非同期監視の設定を行っている環境で、相手ノードのコンソールに login し、コンソール上で、"panic[cpu" の文字列を含むファイルを表示したためと考えられます。
本メッセージは、コンソール非同期監視がコンソール上に該当文字列を検出した際に出力されるメッセージです。動作としては仕様どおりであり、対処は不要です。
RCCU 装置とクラスタホストの IP アドレスを同一セグメントにしてください。
非同期監視の設定が正しく行われていない可能性があります。
非同期監視の設定を見直し、正しく設定してください。
複数ノードで RCI アドレスが同一となっているなど RCI アドレスの設定に誤りがあり、RCI 経由でのノードのパニックに失敗している可能性があります。
RCI アドレスの見直しが必要となりますので、当社技術員 (CE) に連絡してください。
RMS が必要とするメッセージキューパラメタ値が不足しているためにノード間通信が失敗し、 パニックが発生した可能性があります。
/etc/system の msgsys:msginfo_msgtql の値を 65535 以上に変更してください。
CF の状態が LEFTCLUSTER の場合、異常ノードを停止した後、"cftool -k" を実行して、CF の状態が DOWN となったことを確認してください。このとき、RMS の SysNode リソースの状態が Wait の場合は、"hvutil -u SysNode" を実行してください。
CF の状態が UP で、かつ、RMS の SysNode リソースの状態が Wait の場合、異常ノードを停止して、CF の状態が DOWN となったことを確認した後、"hvutil -u SysNode" を実行してください。
CF の状態が DOWN で、かつ、RMS の SysNode リソースの状態が Wait の場合、"hvutil -u SysNode" を実行してください。
PRIMEQUEST 2000/1000シリーズを使用した環境で、CF ノード名の変更、または PRIMECLUSTER を再インストールし前回インストール時とは異なる CF ノード名を使用している場合に本現象が発生する可能性があります。
すべてのノードをシングルユーザモードで起動後、以下のファイルを削除し、ノードを再起動してください。
PRIMEQUEST 1400S/1400E/1400L/1800E/1800Lの場合
/etc/opt/FJSVpsa/local/set.node
PRIMEQUEST 1400S2/1400E2/1400L2/1800E2/1800L2/PRIMEQUEST 2000 シリーズの場合
/etc/fujitsu/SVmco/local/set.node
モードスイッチが、MANUAL、MAINTENANCE の場合には、RCI 経由でのリセット指示はできません。
RCI 経由でのリセットを行う場合は、モードスイッチを AUTO にしてください。
SF(シャットダウン機構) の設定において、コンソール非同期監視の設定を行っている環境で、相手ノードのコンソールにログインし、コンソール上で OBP プロンプトを表す文字列 ("ok") を含むファイルを表示したためと考えられます。
本メッセージは、コンソール非同期監視がコンソール上に該当文字列を検出した際に出力されるメッセージです。動作としては仕様どおりであり、対処は不要です。
生存優先度が高い場合でも、異常が発生したクラスタノードは強制停止の対象になります。
例) システムのハングやパニック、システム高負荷時が続いた場合。
強制停止されたノードで異常がなかったか確認してください。
クラスタアプリケーションを強制起動する際に、RMS が起動していないノードが存在していた場合、RMS はそのノードを強制停止した後、クラスタアプリケーションの強制起動を開始します。
クラスタアプリケーションの強制起動時に、RMS からノードが強制停止されないよう、RMS が起動していないノードの OS を停止するか、シングルユーザモードで起動していることを確認してから、クラスタアプリケーションの強制起動を行ってください。
シャットダウン機構ウィザードの 「■XSCFの設定」 (XSCF の情報を入力する画面) において、ゲストドメインのドメイン名ではなく、制御ドメインのドメイン名 (primary) を入力したことが原因です。
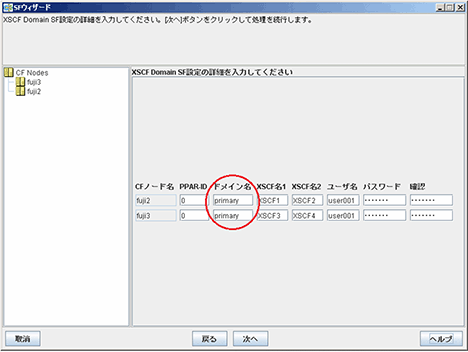
事前にゲストドメイン上で virtinfo -a コマンドを実行し、Domain name に表示されるドメイン名を確認してください。
例)
# virtinfo -a Domain role: LDoms guest Domain name: domain1
Domain UUID: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx Control domain: m10-1 Chassis serial#: XX00000000
Cluster Admin 画面の CF メインウィンドウで、[ツール]メニューの [シャットダウン機構]-[設定ウィザード] を選択してシャットダウン構成ウィザードを起動し、確認したドメイン名を再設定してください。
シャットダウン機構ウィザードの 「■XSCFの設定」(XSCF の情報を入力する画面) において、誤った PPAR-ID を設定したことが原因です。
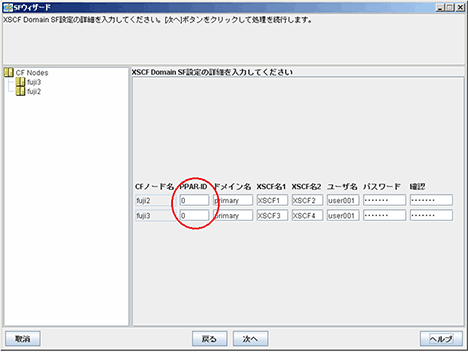
SPARC M10-1、M10-4、M12-1、M12-2 の場合
Cluster Admin 画面の CF メインウィンドウで、[ツール]メニューの [シャットダウン機構]-[設定ウィザード] を選択してシャットダウン構成ウィザードを起動します。
PPAR-ID を "0" に再設定します。
SPARC M10-4S、M12-2S の場合
XSCF で showpparstatus コマンドを実行し、PPAR-ID の情報を確認します。
Cluster Admin 画面の CF メインウィンドウで、[ツール]メニューの [シャットダウン機構]-[設定ウィザード] を選択してシャットダウン構成ウィザードを起動します。
PPAR-IDを "1." で確認した値に再設定します。
PRIMEQUEST 環境において、メモリダンプが正しく設定されていないことが原因です。
以下のマニュアルを参照し、メモリダンプの設定を行ってください。
PRIMEQUEST 1000 シリーズの場合
PRIMEQUEST 1000 シリーズ導入マニュアル
PRIMEQUEST 1000 シリーズ ServerView Mission Critical Option ユーザマニュアル
PRIMEQUEST 2000 シリーズの場合
PRIMEQUEST 2000 シリーズ導入マニュアル
PRIMEQUEST 2000 シリーズ ServerView Mission Critical Option ユーザマニュアル
PRIMEQUEST 400/500 シリーズの場合
PRIMEQUEST 500/400 シリーズ導入マニュアル
PRIMEQUEST 500/400 シリーズ運用マニュアル
PRIMEQUEST 500/400 シリーズリファレンスマニュアル:メッセージ/ログ
I/O フェンシング機能を使用するために必要な SCSI-3 Persistent Reservation に準拠した応答を、ストレージがサーバに対して返していない可能性があります。
使用するストレージのマニュアルを参照して、ストレージが SCSI-3 Persistent Reservation に準拠した応答を行う設定となっているか確認してください。設定に誤りがある場合、設定変更を行った後、本メッセージが出力されたノードを再起動してください。
コンピュートインスタンスの高可用設定を使用する環境において、生存優先度が低いクラスタノードのインスタンスが存在するコンピュートノードで異常が発生した場合は、そのクラスタノードのインスタンスは他のコンピュートノードに移動されません。
"PRIMECLUSTER 導入運用手引書(Linux)" の "コンピュートノードが異常となった場合の対処方法"を参照し、手動で復旧を行ってください。
シャットダウン機構の停止操作と起動操作を連続して実行したことにより、シャットダウン機構の起動操作とシャットダウンデーモンの自動再起動機能の動作が競合した可能性があります。
シャットダウンエージェントの状態が、すべて InitWorked, TestWorked の場合、シャットダウン機構の動作に影響はないため、対処の必要はありません。
シャットダウンエージェントの状態が異常な場合、このメッセージを記録して、調査用の情報を採取します。その後、当社技術員(SE)にお問い合わせください。
強制停止の開始前に、クラスタノードが再起動し、CF の起動が行われた可能性があります。
この場合、強制停止の実行は取り消されます。
ノード異常が発生した時刻以降に、異常が発生していないノードの syslog に以下のメッセージが出力されている場合、本事象に該当します。
CF: クラスタ名: CFノード名 is Down. (#0000 1)
正常な動作のため、対処の必要はありません。
ACPI による電源管理が無効にされていない場合、FJcloud-ベアメタル環境において、SA_vmk5r シャットダウンエージェントは強制停止に失敗します。
強制停止されたノードの /var/log/messages に以下のメッセージが出力されている場合、ACPI による電源管理が無効にされていません。
"systemd-logind: Power key pressed." "systemd-logind: Powering Off..." "systemd-logind: System is powering down."
全ノードで以下のGRUB2ファイルを編集し、GRUB_CMDLINE_LINUXの項目に ACPIによる電源管理を無効とする設定("acpi=off")を追加してください。
例)
# vi /etc/default/grub GRUB_TIMEOUT=5 GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)" GRUB_DEFAULT=saved GRUB_DISABLE_SUBMENU=true GRUB_TERMINAL_OUTPUT="console" GRUB_CMDLINE_LINUX="crashkernel=auto spectre_v2=retpoline rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet acpi=off" GRUB_DISABLE_RECOVERY="true"
全ノードで grub.cfgファイルを再ビルドします。
BIOS ベースの環境の場合
# grub2-mkconfig -o /boot/grub2/grub.cfgUEFI ベースの環境の場合
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg全ノードを再起動してください。
全ノードで、/proc/cmdlineファイルに"acpi=off"が追加されていることを確認してください。
例)
# cat /proc/cmdline BOOT_IMAGE=/vmlinuz-3.10.0-1127.el7.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto spectre_v2=retpoline rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet LANG=ja_JP.UTF-8 acpi=off