This section describes the availability of cluster system in the following environments in Oracle Solaris.
Cluster system in the physical environment
Cluster system in Oracle VM Server for SPARC environment
Cluster system in Oracle Solaris Zones environment
Cluster system in Oracle Solaris Kernel Zones environment
Cluster system in Oracle Solaris Non-global Zones environment
This section describes the availability of cluster system in the following physical environment and Oracle VM Server for SPARC environment in Oracle Solaris.
Cluster system in the physical environment
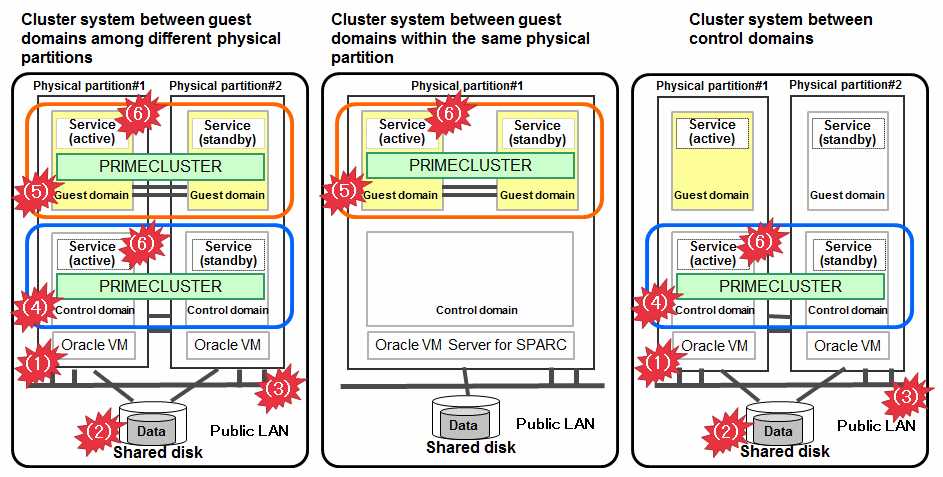
Cluster system between guest domains among different physical partitions in an Oracle VM Server for SPARC environment
Cluster system between guest domains within the same physical partition in an Oracle VM Server for SPARC environment
Cluster system between control domains in an Oracle VM Server for SPARC environment
The table below summarizes the availability of error detection in each monitored cluster system.
Monitoring target | Physical environment | Oracle VM Server for SPARC environment | ||
|---|---|---|---|---|
Cluster system between guest domains among different physical partitions | Cluster system between guest domains within the same physical partition | Cluster system between control domains | ||
1. Physical partition | Y | Y | N | Y |
2. Shared disk and path of disk access | Y | Y | N | Y |
3. Public LAN | Y | Y | N | Y |
4. OS (physical and control domains) | Y | Y | Y*1 | Y |
5. OS (guest domain) | - | Y | Y | Y*2 |
6. Service (cluster application) | Y | Y | Y | Y*3 |
Service continuity when an error occurs Y: Available, N: Unavailable, - : Excluded
*1 The service can be continued because the OS in the guest domain is available even when an OS error in the control domain occurs.
*2 The OS in the guest domain cannot be monitored. When the state of the guest domain (state displayed in the ldm list-domain) is in error, PRIMECLUSTER in the control domain monitors the state of the guest domain so that the service can be continued by switching the OS in the guest domain to the standby system.
*3 The service (cluster application) on the control domain can be monitored but the service on the guest domain cannot be monitored.
Figure 1.16 Physical environment
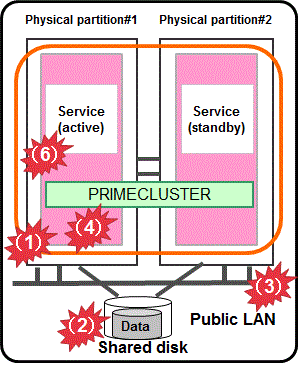
Figure 1.17 Oracle VM Server for SPARC environment
How to detect an error in the following targets to be monitored
Physical partition
The asynchronous monitoring linked with the system monitoring function of server immediately detects a panic or a reset triggered by an error in CPU, memory, or others, and the service is switched to the standby system.
Shared disk and path of disk access
Combining with the volume management function (GDS), the system detects a failure of a disk access or disk access path (monitored by Gds resource) and the service is switched to the standby system when the disk cannot be accessed or an error occurs in the entire communication path of disk access.
Public LAN
Combining with the network multiplexing function (GLS), the system detects a failure of a network adapter or a path in the public LAN (monitored by Gls resource) and the service is switched to the standby system when an error occurs in the entire communication path of the network.
OS (physical and control domains)
A panic or a reset of the OS is immediately detected by the asynchronous monitoring, and the service is switched to the standby system. A hang-up of the OS in the control domain is detected by the cyclic monitoring of cluster interconnect (LAN) and the service is switched to the standby system.
For the cluster system between guest domains within the same physical partition, an OS error in the control domain cannot be detected because it is a single domain.
OS (guest domain)
A panic or a reset of the OS is immediately detected by the asynchronous monitoring, and the service is switched to the standby system. A hang-up of the OS in the guest domain is detected by the cyclic monitoring of cluster interconnect (LAN) and the service is switched to the standby system.
For the cluster system between control domains, an error of the service in a guest domain cannot be detected.
Service (cluster application)
When a resource error of the cluster application occurs, the service is switched to the standby system.
This section describes the availability of following cluster systems in Oracle Solaris Kernel Zones.
Cluster system between Kernel Zones among different physical partitions (Control domain)
Cluster system between Kernel Zones among different physical partitions (Guest domain)
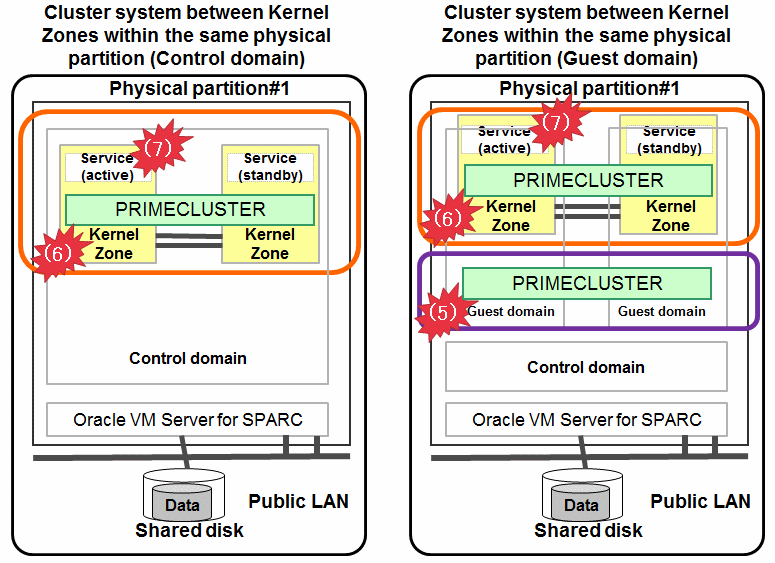
Cluster system between Kernel Zones within the same physical partition (Control domain)
Cluster system between Kernel Zones within the same physical partition (Guest domain)
The table below summarizes the availability of error detection in each monitored cluster system.
Monitoring target | Oracle Solaris Kernel Zones environment | |||
|---|---|---|---|---|
Cluster system between Kernel Zones among different physical partitions (Control domain) | Cluster system between Kernel Zones among different physical partitions (Guest domain) | Cluster system between Kernel Zones within the same physical partition (Control domain) | Cluster system between Kernel Zones within the same physical partition (Guest domain) | |
1. Physical partition | Y | Y | N | N |
2. Shared disk and path of disk access | Y | Y | N | N |
3. Public LAN | Y | Y | N | N |
4. OS (physical and control domains) | Y | Y*1 | N | Y*1 |
5. OS (guest domain) | - | Y | - | Y*2 |
6. OS (Kernel Zones) | Y | Y | Y | Y |
7. Service (cluster application) | Y | Y | Y | Y |
Service continuity when an error occurs Y: Available, N: Unavailable, - : Excluded
*1 The service can be continued because the OS in the guest domain is available even when an OS error in the control domain occurs.
*2 The service cannot be continued in the cluster system between Kernel Zones within the same guest domain.
Figure 1.18 Oracle Solaris Kernel Zones environment (among different physical partitions)
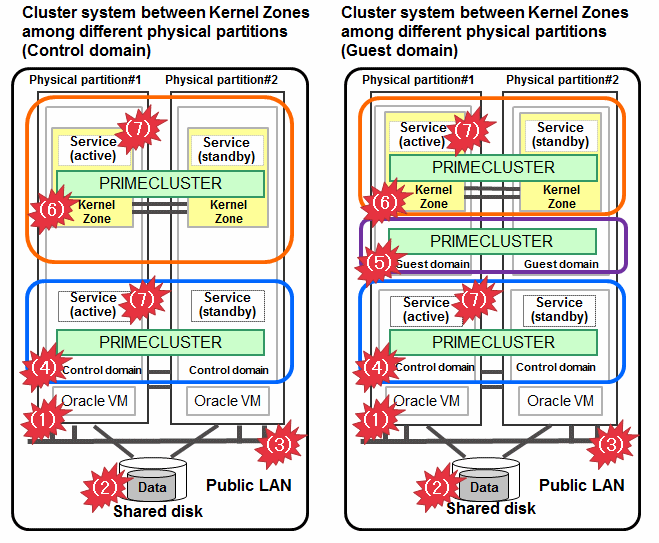
Figure 1.19 Oracle Solaris Kernel Zones environment (within the same physical partition)
How to detect an error in the following targets to be monitored
Physical partition
The asynchronous monitoring linked with the system monitoring function of server immediately detects a panic or a reset triggered by an error in CPU, memory, or others, and the service is switched to the standby system.
Shared disk and path of disk access
Combining with the volume management function (GDS), the system detects a failure of a disk access or disk access path (monitored by Gds resource) and the service is switched to the standby system when the disk cannot be accessed or an error occurs in the entire communication path of disk access.
Public LAN
Combining with the network multiplexing function (GLS), the system detects a failure of a network adapter or a path in the public LAN (monitored by Gls resource) and the service is switched to the standby system when an error occurs in the entire communication path of the network.
OS (physical and control domains)
A panic or a reset of the OS is immediately detected by the asynchronous monitoring, and the service is switched to the standby system. Additionally, a hang-up of the OS is detected by the cyclic monitoring of cluster interconnect (LAN), and the service is switched to the standby system.
For the cluster system between Kernel Zones within the same physical partition, an OS error in the control domain cannot be detected because it is a single domain.
OS (guest domain)
A panic or a reset of the OS is immediately detected by the asynchronous monitoring, and the service is switched to the standby system. Additionally, a hang-up of the OS is detected by the cyclic monitoring of cluster interconnect (LAN), and the service is switched to the standby system.
For the cluster system between Kernel Zones within the same guest domain, an OS error in the guest domain cannot be detected because it is a single domain.
OS (Kernel Zones)
A panic, a reset, or a hang-up of the OS is detected by the cyclic monitoring of cluster interconnect (LAN), and the service is switched to the standby system.
Service (cluster application)
When a resource error of the cluster application occurs, the service is switched to the standby system.
This section describes the availability of cluster system in the following environments in Oracle Solaris Non-global Zones.
Cold-standby environment (non-global zone on the standby system is inactive [service is also inactive on the standby system])
Warm-standby environment (non-global zone on the standby system is active [service is inactive on the standby system])
Single node cluster environment
The table below summarizes the availability of error detection in each monitored cluster system.
Monitoring target | Cold-standby | Warm-standby | Single node cluster |
|---|---|---|---|
1. Physical partition | Y | Y | - |
2. Shared disk and path of disk access | Y | Y | - |
3. Public LAN | Y | Y | - |
4. OS (global zone) | Y | Y | - |
5. OS (non-global zone) | Y | Y | Y*1 |
6. Service (cluster application) | Y | Y | Y*2 |
Service continuity when an error occurs Y: Available, N: Unavailable, - : Excluded
*1 When an error is detected, the service can be continued by restarting the non-global zone.
*2 When an error is detected, the service can be continued by restarting the service (cluster application).
Figure 1.20 Oracle Solaris Zones environment
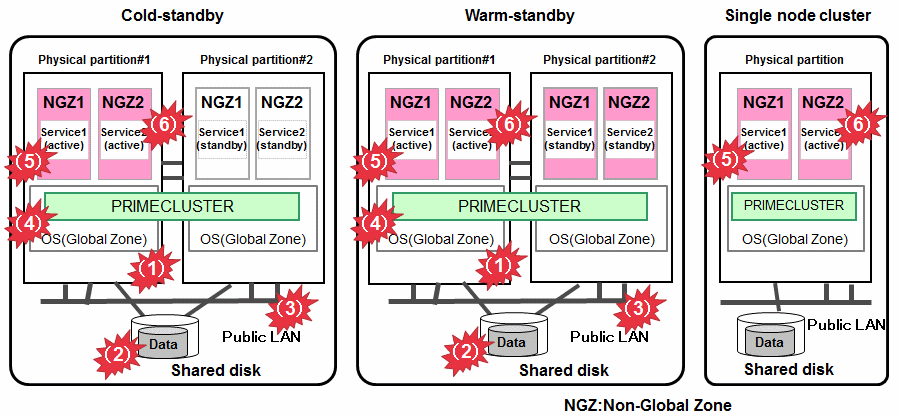
How to detect an error in the following targets to be monitored
Physical partition
The asynchronous monitoring linked with the system monitoring function of server immediately detects a panic or a reset triggered by an error in CPU, memory, or others, and the service is switched to the standby system.
Shared disk and path of disk access
Combining with the volume management function (GDS), the system detects a failure of a disk access or disk access path (monitored by Gds resource) and the service is switched to the standby system when the disk cannot be accessed or an error occurs in the entire communication path of disk access.
Public LAN
Combining with the network multiplexing function (GLS), the system detects a failure of a network adapter or a path in the public LAN (monitored by Gls resource) and the service is switched to the standby system when an error occurs in the entire communication path of the network.
OS (global zone)
A panic or a reset of the OS is immediately detected by the asynchronous monitoring, and the service is switched to the standby system. A hang-up of the OS in the global zone is detected by the cyclic monitoring of cluster interconnect (LAN) and the service is switched to the standby system.
OS (non-global zone)
Check for errors (login (zlogin command) is impossible) of the non-global zone, and the service is switched to the standby system.
For a single node cluster, the global zone of the PRIMECLUSTER restarts the non-global zone.
Service (cluster application)
When a resource error of the cluster application occurs, the service is switched to the standby system.
For a single node cluster, restart the non-global zone.