This section describes the availability of cluster system in the following environments in Linux.
Cluster system in the physical environment
Cluster system in the virtual environment
Cluster system in the cloud environment
This section describes the availability of cluster system in the following environments in Linux.
Cluster system in the physical environment
Cluster system between guest OSes with the Host OS failover function (KVM)
Cluster system between guest OSes on multiple host OSes (KVM)
Cluster system between guest OSes on one host OS (KVM)
Cluster system between guest OSes on multiple compute nodes (RHOSP)
Cluster system between guest OSes on one compute node (RHOSP)
Cluster system between guest OSes on multiple ESXi hosts (VMware)
Cluster system between guest OSes on one ESXi host (VMware)
The table below summarizes the availability of error detection in each monitored cluster system.
Monitoring target | Physical server | KVM | RHOSP | VMware | ||||
|---|---|---|---|---|---|---|---|---|
Cluster system between guest OSes with the Host OS failover function | Cluster system between guest OSes on multiple host OSes | Cluster system between guest OSes on one host OS | Cluster system between guest OSes on multiple compute nodes | Cluster system between guest OSes on one compute node | Cluster system between guest OSes on multiple ESXi hosts | Cluster system between guest OSes on one ESXi host | ||
1. Unit | Y | Y | N | N | Y*1 | N | Y*2 | N |
2. Shared disk and path of disk access | Y | Y | Y | N | Y | N | Y | N |
3. Public LAN | Y | Y | Y | N | Y | N | Y | N |
4. OS (physical, host OS/ESXi host) | Y | Y | N | N | Y*1 | N | Y*2 | N |
5. OS (guest OS) | - | Y | Y | Y | Y | Y | Y*3 | Y*4 |
6. Service (cluster application) | Y | Y | Y | Y | Y | Y | Y | Y |
Service continuity when an error occurs Y: Available, N: Unavailable, - : Excluded
*1 The service can be continued by configuring high availability for compute instances.
For more information on configuring high availability for compute instances, refer to "High Availability for Compute Instances" in "Red Hat OpenStack Platform."
*2 Only when the I/O fencing function is used or VMware vCenter Server functional cooperation and VMware vSphere HA are used, if a hang-up is detected in a guest OS and the guest OS cannot be switched to the standby system automatically, the guest OS will be changed to LEFTCLUSTER state.
*3 When the guest OS cannot be switched to the standby system automatically, the guest OS becomes the LEFTCLUSTER state.
*4 Only when VMware vCenter Server functional cooperation is used, the guest OS can be switched automatically.
Figure 1.13 Physical environment
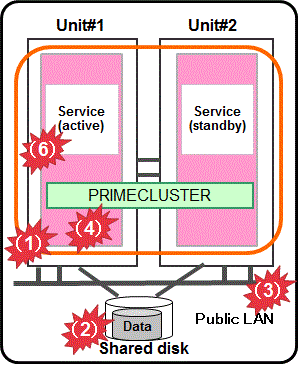
Figure 1.14 Virtual environment
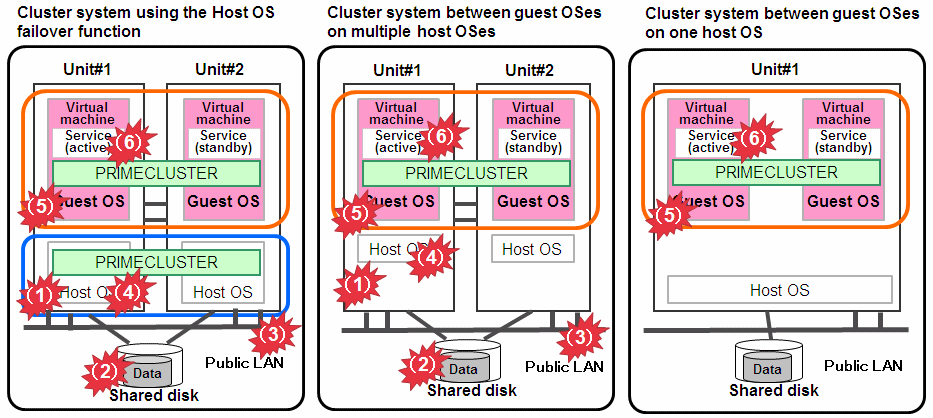
For the RHOSP environment, read "host OS" as "compute node". For the VMware environment, read "host OS" as "ESXi host."
How to detect an error in the following targets to be monitored
Unit
For PRIMEQUEST 2000, the asynchronous monitoring linked with Management Board (MMB), and for PRIMEQUEST3000, the asynchronous monitoring linked with iRMC/MMB, immediately detects a panic or a reset triggered by an error in CPU, memory, or others, and the service is switched to the standby system. For PRIMERGY and virtual environments, an error is detected by the heartbeat monitoring, and the service is switched to the standby system. *1
Shared disk and path of disk access
Combining with the volume management function (GDS), the system detects a failure of a disk access or disk access path (monitored by Gds resource) and the service is switched to the standby system when the disk cannot be accessed or an error occurs in the entire communication path of disk access.
Public LAN
Combining with the network multiplexing function (Global Link Services, hereinafter referred to as GLS), the system detects a failure of a network adapter or a path in the public LAN (monitored by Gls resource) and the service is switched to the standby system when an error occurs in the entire communication path of the network.
OS (physical and host OS/ESXi host)
An error is detected by the heartbeat monitoring, and the service is switched to the standby system. *1
OS (guest OS)
An error is detected by the heartbeat monitoring, and the service is switched to the standby system.
Service (cluster application)
When a resource error of the cluster application occurs, the service is switched to the standby system.
*1 For the cluster system between guest OSes (RHOSP, VMware) on different host OSes, the status becomes LEFTCLUSTER. After the guest OS is restarted by high availability configuration for compute instances (RHOSP) or the vSphere HA function (VMware), LEFTCLUSTER state of the guest OS is automatically cleared and the service is switched to the standby system.
This section describes the availability of cluster system in the following environment in Linux.
Cluster system between guest OSes (FJCS for OSS)
The table below summarizes the availability of error detection in each monitored cluster system.
Monitoring target | FJCS for OSS |
|---|---|
Cluster system between guest OSes | |
1. AZ | N |
2. Shared disk and path of disk access | Y |
3. Public LAN | Y |
4. OS (guest OS) | Y |
5. Service (cluster application) | Y |
Service continuity when an error occurs Y: Available, N: Unavailable, - : Excluded
Figure 1.15 FJCS for OSS environment
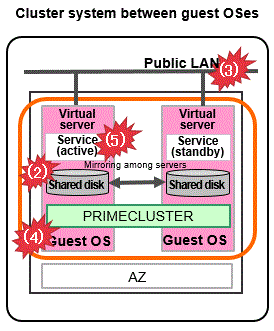
How to detect an error in the following targets to be monitored
AZ
AZ is not a target to be monitored.
Shared disk and path of disk access
Combining with the volume management function (GDS), the system detects a failure of a disk access or disk access path (monitored by Gds resource) and the service is switched to the standby system when the disk cannot be accessed or an error occurs in the entire communication path of disk access.
Public LAN
Combining with the network multiplexing function (GLS), the system detects a failure of a network adapter or a path in the public LAN (monitored by Gls resource) and the service is switched to the standby system when an error occurs in the entire communication path of the network.
OS (guest OS)
An error is detected by the heartbeat monitoring, and the service is switched to the standby system.
Service (cluster application)
When a resource error of the cluster application occurs, the service is switched to the standby system.