PRIMECLUSTER HA manager is the Reliant Monitor Services (RMS) which ensures high availability of applications within the cluster. It monitors the state of resources for applications and the resources used by those applications. It conducts provision of wizard to enable the recovery of user's operation and assuring integrity as a user's asset.
HA manager protects data integrity by performing the following tasks:
Monitoring applications
Handling cluster partition
Starting applications automatically only when all cluster nodes are in a known state (except when otherwise controlled due to settings of the HV_AUTOSTARTUP_IGNORE or PARTIAL_CLUSTER environment variables)
RMS is configured with rules specific to the applications and the configuration of the cluster. When a detector reports a failure, RMS takes the appropriate actions to recover the resources that are needed to provide continued availability of the application. The recovery actions are defined for every application and resource.
RMS recovery actions are as follows:
Local recovery
The application's resources are recovered, and the application is restarted on the same cluster node.
Remote recovery
The application's resources are recovered, and the application is restarted on another cluster node.
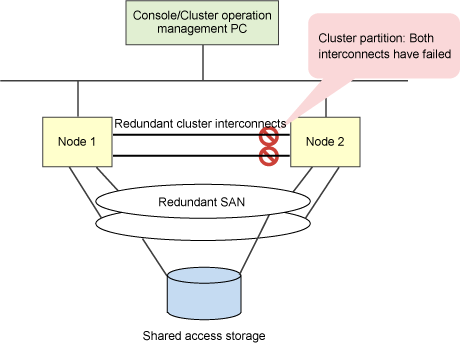
A cluster partition is the result of multiple failures in the cluster interconnects. Even though cluster interconnects fail, some or all of the nodes continue to operate, but the communication between some cluster nodes remain stopped (this is sometimes called split-brain syndrome). Redundant cluster interconnects are effective but not enough for preventing split-brain syndrome.
The figure below shows an example of two breaks in the redundant cluster interconnects in which Node 1 and Node 2 can no longer communicate with each other. However, both nodes still have access to the SAN. Therefore, if recovery actions were taken independently on each node, two instances of an application could be running unaware on the two nodes of the cluster. If these instances were to make uncoordinated updates to their data, then data corruption would occur. Clearly, this condition cannot be allowed.
Figure 1.2 Cluster partition in two-node cluster
To prevent data corruption, PRIMECLUSTER provides a system to ensure the integrity between nodes as follows:
When a heartbeat occurs and each node cannot communicate with a target node (if it is not clear that the nodes still operate or they have been stopped), set the target node as LEFTCLUSTER state.
Cancel LEFTCLUSTER state.
PRIMECLUSTER checks that nodes within the cluster system are the following states before starting a recovery processing at each node.
All the nodes are either UP or DOWN.
(no node is LEFTCLUSTER state)
Operating nodes can communicate every other operating node.
In PRIMECLUSTER, if the integrity between nodes is ensured as above, it is called "cluster consistent state (quarum)."
The terms consistent state and quorum are used interchangeably in PRIMECLUSTER documents. The cluster is in a consistent state when every node of the cluster is in a known state (UP or DOWN) and each node that is UP can communicate with every other node that is UP. The applications in the cluster should ensure that the cluster is in a consistent state before starting any operations that will alter shared data. For example, RMS ensures that the cluster is in a consistent state before it will start any applications in the cluster.
PRIMECLUSTER performs elimination through a variety of methods, depending on the architecture of the nodes. When PRIMECLUSTER determines that a node becomes the LEFTCLUSTER state, it eliminates that node; thereby, recovering the application and guaranteeing data integrity.
Note
The term quorum has been used in various ways in the literature to describe the handling of cluster partitions. Usually, this implies that when (n + 1)/2 nodes can see each other, they have a quorum and the other nodes will not perform any I/O operations. Because PRIMECLUSTER methods differ from the conventional meaning of quorum, the term cluster integrity was adopted. Some PRIMECLUSTER commands use the quorum term heritage, but in these cases cluster integrity is implied.
The purpose of the Cluster Integrity Monitor (CIM) is to allow applications to determine when it is safe to perform operations on shared resources. It is safe to perform operations on shared resources when a node is a member of a cluster that is in a consistent state.
A consistent state is when all the nodes of a cluster that are members of the CIM set are in a known and safe state. The nodes that are members of the CIM set are specified in the CIM configuration. Only these nodes are considered when the CIM determines the state of the cluster.
When a node first joins or forms a cluster, the CIM indicates that the cluster is consistent only if it can determine the following:
The status of the other nodes that make up the CIM set
Whether the nodes of the CIM set are in a safe state
The method used to determine the state of the members of the cluster is sometimes called the CIM method. The CIM can use several different CIM methods; however, the following are available by default and are discussed here:
NSM
The Node State Monitor (NSM) monitors the node states at fixed cycles, and it tracks the state of the nodes that are currently, or have been, members of the cluster. This is also known as the NULL or default CIM method. NSM is an integrated part of the PRIMECLUSTER CF.
RCI
The RCI (Remote Cabinet Interface) is a special SPARC Enterprise M series environmental control and state network that can asynchronously both report on the state of the systems and control the systems on Solaris systems. (For more information, refer to "PRIMECLUSTER Cluster Foundation (CF) Configuration and Administration Guide.")
XSCF SNMP
The XSCF SNMP (eXtended System Control Facility Simple Network Management Protocol) is a special SPARC M10, M12 environmental control and state network that can asynchronously both report on the state of the systems and control the systems on Solaris systems. (For more information, refer to "PRIMECLUSTER Cluster Foundation (CF) Configuration and Administration Guide.")
MMB
The MMB (Management Board) is a special PRIMEQUEST environmental control and state network that can asynchronously both report the status of the systems and control the systems on Linux systems. (For more information, refer to "PRIMECLUSTER Cluster Foundation (CF) Configuration and Administration Guide.")
PRIMECLUSTER allows you to register and use multiple CIM methods. When multiple CIM methods are registered, CIM uses the lower priority method to check the state of a node only if the higher priority method cannot determine the node state. For example, if RCI and NSM are registered as CIM methods and RCI has the higher priority, then CIM uses the CIM method that uses RCI to check the node status.
If the target is a node or a partition, the RCI CIM method returns UP or DOWN, and then processing ends. However, if the node being checked by the RCI method is not connected to the RCI or if the RCI is not operating properly, then the RCI method will fail. CIM then uses the NSM-based CIM method to check the node state.
Similarly if MMB and NSM are registered as CIM methods and MMB has the higher priority, then CIM uses the CIM method that uses MMB to check the node status. In this case, if the target is a PRIMEQUEST node, the MMB CIM method returns UP or DOWN, and then processing ends. However, if the node being checked by the MMB method is not connected to the MMB or if the MMB is not operating properly, then the MMB method will fail. CIM then uses the NSM-based CIM method to check the node state.
The CIM reports on whether a node state in a cluster is consistent (true), or a node state is not consistent (false) for the cluster. True and false are defined as follows:
TRUE
A known state for all CIM nodes
FALSE
An unknown state for any cluster CIM node
The CIM allows applications to determine when a cluster is in a consistent state, but it does not take action to resolve inconsistent clusters. Many different methods to ensure consistent clusters have been used in the high-availability field, but there is only one method that has proven completely effective and does not require cooperation between the nodes. PRIMECLUSTER uses this method known as the Shutdown Facility (SF) to return to a consistent cluster state when something occurs to disrupt that state. In the cluster partition example shown in Figure 1.2 Cluster partition in two-node cluster, both nodes will report the other node as having the state LEFTCLUSTER. The CIM will return a FALSE status. To get the cluster into a consistent state, SF forces one of the nodes into a safe state by either forcing a panic or shutting off the power.
The SF can be configured to eliminate nodes through a variety of methods. When the SF receives a request to eliminate a node, it tries to shut down the node by using the methods in the order that were specified. Once a method has successfully eliminated the node, the node's state is changed to DOWN by the SF.
The transition from LEFTCLUSTER to DOWN is the signal used by the various cluster services to start recovery actions. Note that different systems will support different shutdown methods. For example, the cluster console is available for Solaris, but is not available for Linux.
If all of the configured SF methods fail to return a positive acknowledgement that the requested node has been eliminated, then no further action is taken. This leaves the cluster in an inconsistent state and requires operator intervention to proceed.
This approach ensures that damage to user data could not occur by inadvertently allowing an application to run in two parts of a partitioned cluster. This also protects from the situation where a node fails to respond to heartbeats (for example, an extreme system load) and then comes back to life later. In this case, the application on the node that returns to life may continue to run even though the other node has taken action to start that application.
Note
PRIMECLUSTER allows you to use various hardware-specific methods to set definition that reset nodes on which Solaris or Linux operate. For more information, refer to "PRIMECLUSTER Cluster Foundation (CF) Configuration and Administration Guide."
PRIMECLUSTER provides a mechanism where hardware monitors can be used to quickly detect a system state change and inform the cluster membership functions. Without this monitoring capability, only the cluster heartbeat timeout will detect that a node has panicked; this will take up to 10 seconds with the default heartbeat interval. When a Monitoring Agent (MA) is used, it can detect a node panic very quickly. For example, with PRIMEPOWER hardware and the RCI, the MA takes less than 1 second to detect a system panic. MAs are implemented as plug-ins that interfaces with the Shutdown Facility.
The MA technology allows PRIMECLUSTER to recover from monitored node failures very quickly. For non-cluster aware applications the time from when a node panic occurs to the time that the application recovery begins can be as short as 2.5 seconds under optimal conditions. The time the application takes to start up and become ready to operate varies from one application to another. For cluster-aware applications, such as Oracle RAC, the time from a system panic to the time Oracle has started recovery and is processing queries on the surviving nodes can be as short as 6.5 seconds. At this point, Oracle may still be performing some recovery actions that might impact performance, but it is able to respond to user queries.
If a node fails, PRIMECLUSTER does the following:
Detects a node failure
Notifies of the failure
Confirms the node state
Eliminates the node
The MA notifies SF of a node failure on detecting it. SF seeks a redundant confirmation regarding the node state to assess the reliability of the failure notification. This verification procedure is required to prevent the node that is normally running from being shut down.
SF confirms the node state as follows:
Collects the node state information from all registered MAs again.
Checks if the response to the CF heartbeat request is returned.
SF prompts the MA to eliminate the failed node when all the MAs notify SF of the node failure, and CF notifies SF of the failure in responding to the heartbeat request. When the node elimination is done, this brings the other node DOWN.
I/O Fencing function
Uses an exclusive control function by SCSI-3 Persistent Reservation in the cluster configuration connected to the shared disk device and prevents simultaneous access from both of the nodes.
This function can be only used in the following virtualization environments.
VMware environment
Oracle VM Server for SPARC environment
To properly recover an application, RMS must know about the resources an application requires for proper operation. The configuration of the resources and the relationship between the resources can be very complex. RMS Wizard Tools performs configuration definition to specify these information to the RMS. These information can be configured through GUI by using userApplication Configuration Wizard.
The configuration tool foundations (RMS Wizard Tools) capture generic information about the cluster and common application services.