Mirroring Controllerには監視対象の資源へのアクセスにおいて、タイムアウト時間の超過やリトライ回数を越えたことで異常と判断する監視方法があります。これらの設定が適切でないと、誤検知のリスクや自動縮退の遅延を引き起こす場合があるため、適切な設計が必要となります。
例えば、異常監視に関するチューニングが適切に行われていない場合、以下のような事象が発生します。
タイムアウト時間が短い場合
冗長な縮退を引き起こして可用性が低下します。
タイムアウト時間が長い場合
業務継続に影響を与える障害が発生しても、自動縮退までの時間が長期化して業務停止を引き起こす可能性があります。
サーバ定義ファイルの以下のパラメータをシステムに応じた値に編集することで縮退運転の最適化を行うことができます。また、これらのパラメータを編集するには、“A.4 サーバ定義ファイル”を参照してください。
パラメータ | 指針 |
|---|---|
異常監視の監視間隔 | Mirroring Controllerによる異常監視がシステムに負荷を与えない範囲で設定しますが、通常は設定不要です(デフォルトは800ミリ秒)。 |
異常監視のタイムアウト時間 | サーバや管理用ネットワークの能力に対して負荷が継続的に掛かる時間を考慮します。例えば、高負荷のバッチ業務を実行する場合や高多重のオンライン業務が連続的に発生するような場合が想定されます(デフォルトは1秒)。 |
異常監視のリトライ回数 | 負荷が流動的なシステムなど、heartbeat_timeoutで指定した値を超える事象に対して安全値が必要な場合に設定しますが、通常は設定不要です(デフォルトは2回)。 |
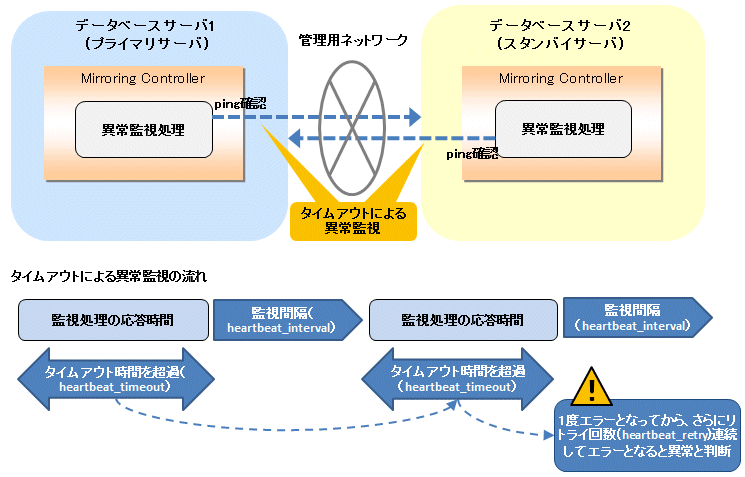
異常と判断するまでの時間の計算方法を以下に示します。
異常検出時間 = ( heartbeat_timeout(秒数) + heartbeat_interval(ミリ秒) / 1000 ) × ( heartbeat_retry(回数) + 1)
デフォルトの値を使用した場合の異常検出時間は以下となります。
異常検出時間 = ( 1 + 800 / 1000 ) × ( 2 + 1 )
= 5.4(秒)注意
裁定サーバを使用して自動縮退を行う運用の場合、Mirroring Controller裁定プロセスでの裁定処理のタイムアウト時間の設定をする際に計算するOS/サーバの生死監視時間は裁定サーバ側の裁定定義ファイルに指定したOSやノードの異常監視のパラメータの値を使用してください。
パラメータ | 指針 |
|---|---|
異常監視の監視間隔 | Mirroring Controllerによる異常監視がシステムに負荷を与えない範囲で設定しますが、通常は設定不要です(デフォルトはheartbeat_intervalの設定値です)(ミリ秒数)。 |
データベースプロセスの異常監視のタイムアウト時間 | データベースに対して負荷が継続的にかかる時間を考慮します。例えば、高負荷のバッチ業務を実行する場合や高多重のオンライン業務が連続的に発生するような場合が想定されます(デフォルトはheartbeat_timeoutの設定値です) (秒数)。 |
異常監視のリトライ回数 | 負荷が流動的なシステムなど、db_instance_check_timeoutで指定した値を超える事象に対して安全値が必要な場合に設定しますが、通常は設定不要です(デフォルトはheartbeat_retryの設定値です) (回数)。 |
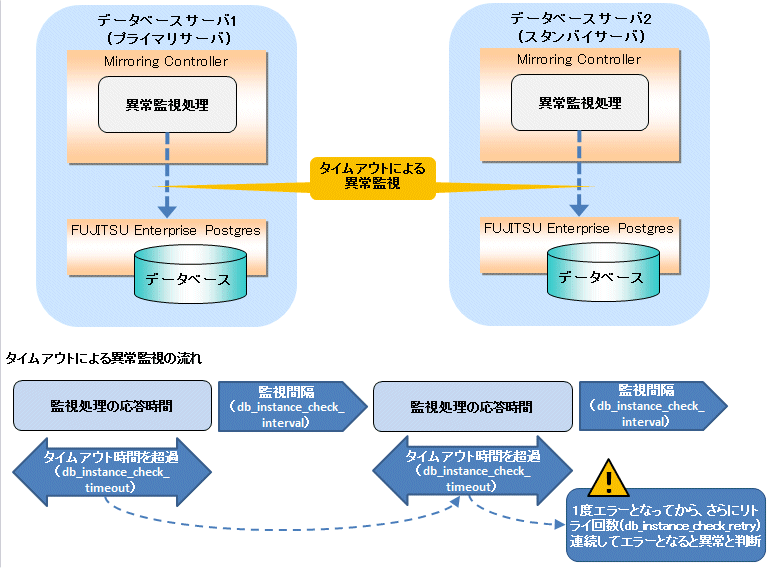
異常と判断するまでの時間の計算方法を以下に示します。
異常検出時間 = ( db_instance_check_timeout(秒数) + db_instance_check_interval(ミリ秒) / 1000 ) × ( db_instance_check_retry(回数) + 1 )
デフォルトの値を使用した場合の異常検出時間は以下となります。
異常検出時間 = ( 1 + 800 / 1000 ) × ( 2 + 1 )
= 5.4(秒)注意
サーバ識別子.confファイルのdb_instance_timeout_actionにmessageを指定した場合、db_instance_check_timeoutの指定値が短いと、データベースプロセスのダウンを無応答として検知し、自動縮退が発生するまでに時間がかかる場合があります。そのため、db_instance_check_timeoutには、適切なタイムアウト時間を指定してください。
パラメータ | 指針 |
|---|---|
異常監視の監視間隔 | Mirroring Controllerによる異常監視がシステムに負荷を与えない範囲で設定しますが、通常は設定不要です(デフォルトはheartbeat_intervalの設定値です)(ミリ秒数)。 |
異常監視のリトライ回数 | 一時的にログ転送LAN異常が発生する場合など、安全値が必要な場合に設定しますが、通常は設定不要です(デフォルトはheartbeat_retryの設定値です) (回数)。 |
ストリーミングレプリケーションの異常監視のタイムアウト時間 | ログ転送用ネットワークの能力および負荷やデータベースに対する負荷が継続的に掛かる時間を考慮します。例えば、WALが大量に発生するようなデータ更新を行う業務が連続的に発生するような場合には誤検知を回避する設定が必要です(デフォルトは60秒)。 |
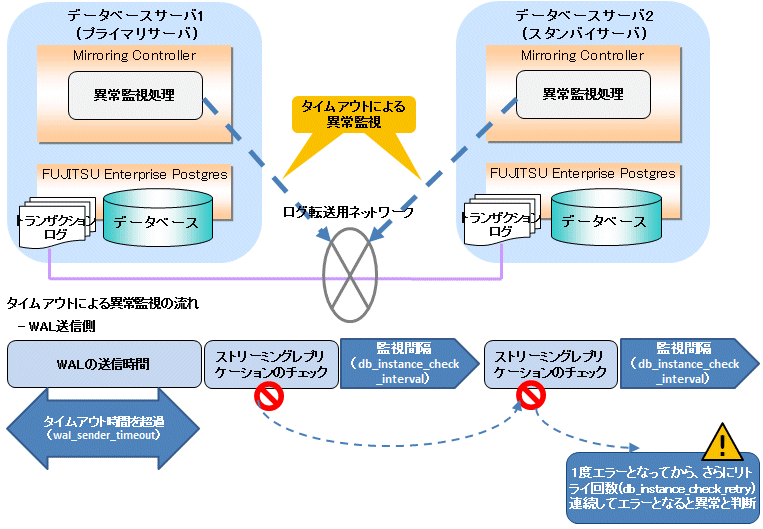
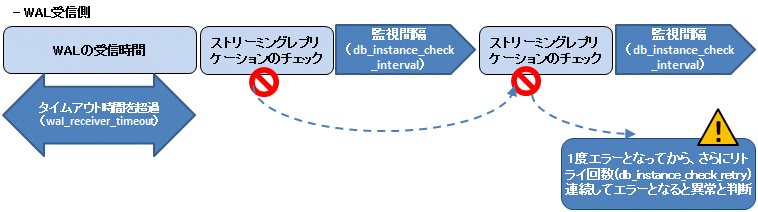
異常と判断するまでの時間の計算方法を以下に示します。
異常検出時間 = wal_sender_timeout(秒数) + ( db_instance_check_interval(ミリ秒) / 1000 × ( disk_check_retry(回数) + 1 ) ) または = wal_receiver_timeout(秒数) + ( db_instance_check_interval(ミリ秒) / 1000 × ( disk_check_retry(回数) + 1 ) )
デフォルトの値を使用した場合の異常検出時間は以下となります。
異常検出時間 = 60 + (800 / 1000 × (2 + 1))
= 62.4(秒)パラメータ | 指針 |
|---|---|
異常監視の監視間隔 | Mirroring Controllerによる異常監視がシステムに負荷を与えない範囲で設定しますが、通常は設定不要です(デフォルトはheartbeat_intervalの設定値です) (ミリ秒数)。 |
異常監視のリトライ回数 | 一時的なディスクの入出力障害が発生する可能性が想定される場合など、安全値が必要な場合に設定しますが、通常は設定不要です(デフォルトはheartbeat_retryの設定値です) (回数)。 |
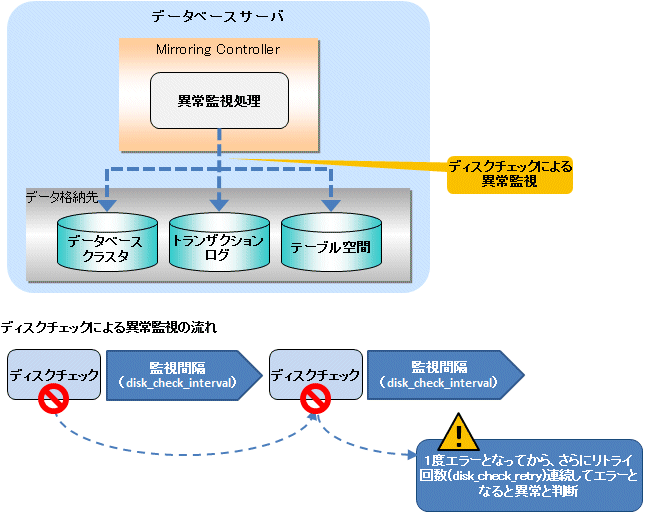
異常と判断するまでの時間の計算方法を以下に示します。
異常検出時間 = disk_check_interval (ミリ秒) / 1000 × ( disk_check_retry(回数) + 1 )
デフォルトの値を使用した場合の異常検出時間は以下となります。
異常検出時間 = 800 / 1000 × ( 2 + 1 )
= 2.4(秒)注意
上記のチューニングは、タイムアウトを検知してからプライマリサーバを切り替えるなどの操作を行うまでの時間に影響します。そのため、誤検知を行わない設計を行った上で、切り替え/切り離し時間を考慮した値に補正してください。
OSやサーバの生死監視においてハートビート異常で即時に自動縮退を行う選択を行った場合には、スプリットブレインを発生させる危険性があります。詳細は、“付録D ハートビート異常で即時に自動縮退を行うを選択した場合の注意事項“を参照してください。
参考
監視対象の資源によっては、Mirroring Controllerがデータベースインスタンスへの接続やSQLアクセスにより異常監視を行うものがあります。この異常監視を行うための接続先データベース名や接続ユーザー名は、サーバ定義ファイル内のパラメータに従います。また、アプリケーション名は‘mc_agent’です。