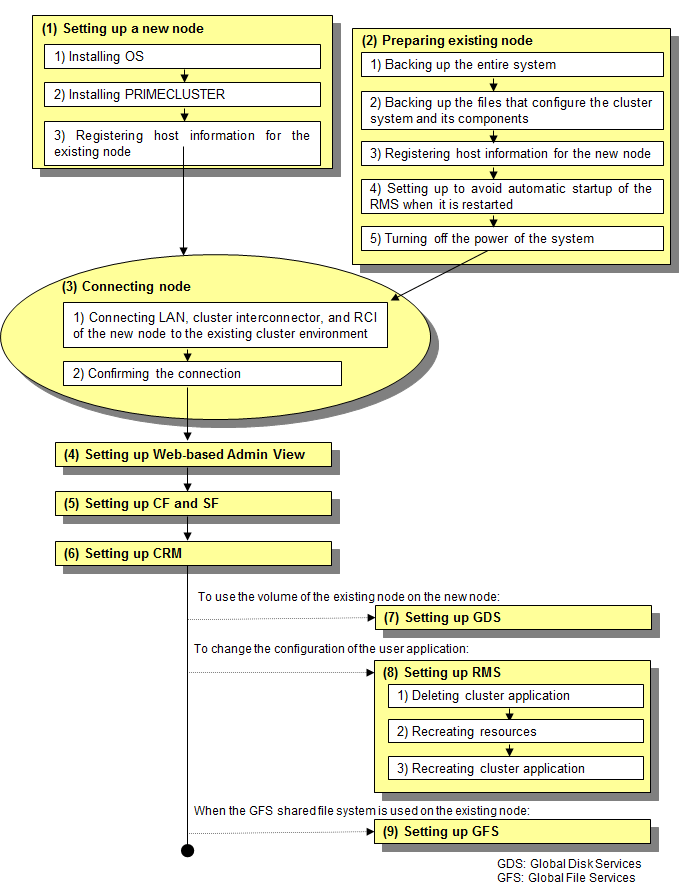
The node expansion procedure is explained below:
Note
Use the same OS version, collective updates, and patches as those of the existing cluster nodes.
Stop operation when nodes are to be added.
Two or more nodes cannot be added at the same time. When multiple nodes are to be added, add them one by one.
The nodes to be added must be of the same model as the existing cluster nodes.
In the following explanation, node1 and node2 are used as the node names of the existing cluster nodes while node3 is used as the node name of the new node.
Take the following steps to set up the new node.
The new node should be prepared such that the operating system, PTFs, FibreChannel, and packages such as the multipath software have already been installed.
Procedure
Install PRIMECLUSTER on the new node.
This must be done in a single user mode.
For details, see the "PRIMECLUSTER Installation Guide."
Configure NTP.
Configure NTP for the new node to match the NTP of the existing nodes.
Define the following information in the "/etc/inet/hosts" file of the new node.
The IP address of the existing cluster nodes and the host name that is associated with the IP address
The IP address of the remote console that is connected to the existing cluster nodes and the host name that is associated with the IP address
The IP address of the CIP interface of the existing cluster nodes and the CIP name which uses that IP address
Turn off the power to the new node.
Take the following steps to prepare the existing nodes.
Procedure
Preparing for unexpected failures, you need to back up the entire system of all existing cluster nodes, the PRIMECLUSTER system and the configuration files of each component.
Back up the entire system.
Stop RMS by executing the following command on any one of the existing cluster nodes.
node1# hvshut -a
Reboot all the existing cluster nodes from a single user mode.
node1# /usr/sbin/shutdown -g0 -i0 -y
....
ok boot -s
....
Type control-d to proceed with normal startup,
(or give root password for system maintenance):
....Mount the file system on all the existing cluster nodes.
node1# mountall -l node1# zfs mount -a
Back up the entire system or property in the shared disk by executing the "ufsdump(1M)" or "dd(1M)" command.
Back up the PRIMECLUSTER system and the configuration files of each component.
Back up the configuration files of the PRIMECLUSTER system on all existing cluster nodes. See "Chapter 13 Backing Up and Restoring a PRIMECLUSTER System".
Back up the configuration files that are used for GLS on all existing cluster nodes.
To back up the configuration files for GLS (redundant line control), use the following command (For details on the "hanetbackup" command, see the " PRIMECLUSTER Global Link Services Configuration and Administration Guide: Redundant Line Control Function "):
node1# /opt/FJSVhanet/usr/sbin/hanetbackup -d /var/tmp/backup To back up the configuration files for the GLS multipath function:
node1# cd /etc/opt/FJSVmpnet node1# tar cvf - conf | compress > /var/tmp/backup/mpnetfile.tar.Z
Define the following information in the /etc/inet/hosts file of all the existing cluster nodes.
The IP address of the node to be added and the name of the host that is associated with the IP address
The IP address of the remote console that is connected to the node to be added and the host name that is associated with the IP address
Edit the "/opt/SMAW/SMAWRrms/bin/hvenv.local" file as shown below so that RMS does not start automatically on any of the existing cluster nodes, even when a cluster node is rebooted.
node1# vi /opt/SMAW/SMAWRrms/bin/hvenv.localexport HV_RCSTART=0
To add a new node, all the existing cluster nodes must be turned off.
Join a new node with the existing cluster nodes.
Procedure
Connect the LAN, Cluster Interconnect, and the RCI of the new node to the existing cluster environment.
At this time, configure the RCI address for the new node.
(This operation is done by your Fujitsu CE.)
After setting the RCI address, boot up the existing cluster nodes and check that no error message is output to the console or syslog.
Boot the new node and confirm that the new node and its remote console are correctly configured in the network by executing the "ping(1M)" command.
Confirm that the RMS is stopped on any one of the existing cluster nodes, and then stop the SF by executing the following commands on each existing cluster node.
Confirm that RMS is stopped.
node1# hvdisp -a
hvdisp: RMS is not runningStop SF. Execute the following command on all the existing cluster nodes.
node1# sdtool -e
node1# sdtool -s
(SMAWsf, 30, 13) : The RCSD is not running
If the GFS shared file system is used in an existing node, take the following steps to stop the GFS operation.
Execute the following command for the entire GFS shared file system on any one of the existing cluster nodes, and then unmount the file system.
node1# sfcumntgl <mount point>
Execute the following command, and then stop the GFS daemon on all cluster nodes.
node1# sfcfrmstopThis section explains how to configure Web-Based Admin View.
The nodes on which you need to configure Web-Based Admin View vary depending on the following cases;
Target node:
When the existing management server is used
The management server must be defined on the new node.
Configure Web-Based Admin View on the new node.
When the new node is used as the management server
The definition of the new management server must be defined on all the nodes.
Configure Web-Based Admin View on all the nodes.
Procedure
Set up Web-Based Admin View on the node.
See "4.2.3.1 Initial setup of the operation management server."
Confirm that Web-Based Admin View is running correctly.
For confirmation, use any one of the cluster nodes as explained in "4.2.3.2 Confirming Web-Based Admin View Startup."
Make the CF and SF configuration by using Cluster Admin. This section explains how to configure CF and SF. See "2.1.4 Example of creating a cluster" in the "PRIMECLUSTER Cluster Foundation (CF) Configuration and Administration Guide."
Procedure
Start the Web browser on a client and connect to the primary management server to display Web-Based Admin View.
Log on to Web-Based Admin View and then select the "Global Cluster Services" menu (see Figure 3).
Select a node name to be added on the node selection screen (see Figure 6).
Click the "Configure" button in the left-hand side panel on the screen, to start the CF wizard (see Figure 8).
Select an existing cluster system name from the "Create/Join Cluster" screen and then click the "Add local node to an existing CF Cluster" option button. Then, choose the "Next" button (see Figure 10).
Select a node that you want to add from [Available Nodes] on the "Selecting cluster nodes and the cluster name" screen, and then add the node to [Clustered Nodes] (see Figure 11).
When the Cluster Interconnect confirmation screen appears, confirm that the combination of network interface cards is correct on all nodes. Then, click the "Next" button (see Figure 14).
Check the "For RMS" checkbox for the CIP subnet settings (note that the RMS cannot use the CIP if this is not set.)
When the "Complete Configuration" dialog box appears, close that screen and click the "Finish" button. This completes the CF settings.
Configure SF.
For details, see "5.1.2 Configuring the Shutdown Facility."
Confirm that the CF and SF have been configured correctly by executing the following commands on the GUI screen or on any one of the cluster nodes.
node1# cftool -n
Node Number State Os Cpu node1 1 UP Solaris Sparc node2 2 UP Solaris Sparc node3 3 UP Solaris Sparc
node1# sdtool -s
Cluster Host Agent SA State Shut State Test State Init State
------------ ----- -------- ---------- ---------- ----------
node1 SA_xscfsnmpg0p.so Idle Unknown TestWorked InitWorked
node1 SA_xscfsnmpg1p.so Idle Unknown TestWorked InitWorked
node1 SA_xscfsnmpg0r.so Idle Unknown TestWorked InitWorked
node1 SA_xscfsnmpg1r.so Idle Unknown TestWorked InitWorked
node2 SA_xscfsnmpg0p.so Idle Unknown TestWorked InitWorked
node2 SA_xscfsnmpg1p.so Idle Unknown TestWorked InitWorked
node2 SA_xscfsnmpg0r.so Idle Unknown TestWorked InitWorked
node2 SA_xscfsnmpg1r.so Idle Unknown TestWorked InitWorked
node3 SA_xscfsnmpg0p.so Idle Unknown TestWorked InitWorked
node3 SA_xscfsnmpg1p.so Idle Unknown TestWorked InitWorked
node3 SA_xscfsnmpg0r.so Idle Unknown TestWorked InitWorked
node3 SA_xscfsnmpg1r.so Idle Unknown TestWorked InitWorkedThis section explains how to set up the Customer Resource Management (CRM) resource database.
Procedure
Reconfigure the resource database on the existing nodes.
Confirm the following:
All of the existing nodes have been started.
CIP entry of the new node is in /etc/cip.cf of the existing nodes.
The resource database uses /etc/cip.cf to associate CF node names with CIP names.
Reconfigure the resource database.
The procedure is shown below:
Log into any one of existing nodes using a system administrator access privilege.
Specify the "-a" and the "-g" options in the "clsetp(1M)" command.
# /etc/opt/FJSVcluster/bin/clsetup -a node -g file
As a result of this operation, a new node will be added to the resource database of the existing nodes.
The configuration information on the resource database, created after the execution of the "clsetup(1M)" command, is used when the resource database of the new node is configured. Therefore, do not specify a directory that will be automatically deleted when rebooting the node with the "-g" option (for example: /tmp).
Specify the CF node name in node, and a full path name of the file name of the resource database configuration information. "tar.Z" extension will be appended to the resource database configuration information.
For example, to add a new node which has a CF node name of fuji4, and a configuration information file name of /mydir/rdb, the command to be executed will be as shown below:
# /etc/opt/FJSVcluster/bin/clsetup -a fuji4 -g /mydir/rdbThe configuration information file of the resource database will be created as /mydir/rdb.tar.Z.
Confirm that the new node has been added to the resource database.
Execute the "clgettree(1)" command, and then confirm that the new node is displayed on the output result. At this time, the state of the new node is displayed as UNKNOWN.
Set up the resource database of the new node.
Before setting up the resource database of the new node, confirm the following:
The content of /etc/cip.cf of the new node must be the same as that of the existing nodes.
Confirm that the CIP of the new node is in /etc/cip.cf of the new node and that the content of /etc/cip.cf is the same as that of the existing nodes.
Communication must be enabled in CIP
Confirm that the new node is connected to all of the existing nodes by CIP using the "ping(1M)" command.
If two or more CIPs are configured in the new nodes, use the first CIP for the resource database. Then, connection will be enabled. An example using "fuji4RMS" as the new node is shown below:
# ping fuji4RMSAfter confirming the above, set up the resource database of the new node.
The procedure is as follows:
Log into the new node using a system administrator access privilege.
Copy the "resource database configuration information" file created in Step 2) in "Recreate the settings for the resource database of the existing nodes" to the new node.
Specify the -s option in the clsetup(1M) command, and execute it.
# /etc/opt/FJSVcluster/bin/clsetup -s file
Specify file with a full path name of the resource database configuration file.
When the resource database configuration information file "rdb.tar.Z" is copied to /mydir, the command to be executed will be as shown below:
# /etc/opt/FJSVcluster/bin/clsetup -s /mydir/rdb.tar.ZConfirm that the resource database of the new node is configured.
Execute the clgettree(1) command for the new node and confirm the following:
The new node is displayed.
The state of the new node is displayed as ON.
The output result is the same as that of the existing nodes.
Register the hardware, which is connected to the new node, to the resource database.
Log into any one of nodes using a system administrator access privilege, and execute the command shown below:
# /etc/opt/FJSVcluster/bin/clautoconfig -rSetting up synchronization with the resource database
If the individual nodes are restarted at different times after node expansion, the tuning parameter must be set up to be synchronized with the resource database. For details, see "4.5.1 Start up synchronization and the new node" in the "PRIMECLUSTER Cluster Foundation (CF) Configuration and Administration Guide."
If a new node was added to the GDS configuration, it is necessary to change the class scope by executing the sdxattr command.
For information on the change procedure, see "PRIMECLUSTER Global Disk Services Configuration and Administration Guide."
This section explains how to register a new node (SysNode) in a userApplication that has been running on an existing node.
Procedure
Configuration for each resource
Take the following steps depending upon the resources in the existing userApplication:
Cmdline
Create the Start, Stop, and Check scripts in the new node or copy them from the existing node. If "Path enter" is selected from "Creation method" when creating the existing Cmdline resource, specify the paths to the scripts. If "New" is selected, the scripts under /opt/FJSVwvucw/scripts/start, /opt/FJSVwvucw/scripts/stop, and /opt/FJSVwvucw/scripts/check must be stored in the same directory of the new node. You also need to add the access privilege by executing the "chmod(1)" command.
Gds
Take the following steps to expand the class scope:
Expand the class scope.
See "PRIMECLUSTER Global Disk Services Configuration and Administration Guide."
Execute the following command on any one of the cluster nodes:
# /opt/SMAW/SMAWRrms/bin/hvgdsetup -a class
hvgdsetup with -a option performs the following tasks on
nodes to which the specified disk class belongs.
1) Make GDS disk class on resource database not activated
automatically when the node boots. If this operation has
been done before, nothing will be performed anymore.
2) Next make volumes of the specified disk class
enabled manual online on a node on which an application
is offline or faulted while the application is online
or standby on another node.
3) Then make volumes of the specified disk class stopped
immediately.
This process is executed on the nodes to which the disk
class belongs.
Do you want to continue with these processes ? [yes/no] yesThe following message might appear after executing the "hvgdsetup" command. This does not disrupt ongoing operation.
FJSVcluster: error: clrmd: 7516: An error occurred in the resource deactivation processing. (resource:resource rid:rid detail:detail) WARNING !! Failed to control 'dc_class' in the following node(s). node(s) node_name: Check the state of the nodes. If any nodes have failed, you may ignore this message.
Fsystem
Add the mount point entry to /etc/vfstab.pcl on the new node.
Gls
Take the following steps for Gls:
Set up the virtual interface for the takeover IP address on the new node and register it as a cluster resource. For details, see the "PRIMECLUSTER Global Link Services Configuration and Administration Guide: Redundant Line Control Function."
Restart Gls by executing the following command:
node3# /opt/FJSVhanet/usr/sbin/resethanet -sTakeover network
Nothing needs be done at this time. In Procedure 3, however, it is necessary to recreate the resources.
Procedure
Create a state transition procedure on the new node and register the procedure resource with the cluster resource manager. For more details, see "E.1 Registering a Procedure Resource".
Process monitoring
Add the startup command to the new node. Also, you need to add the access privilege by using the "chmod(1)" command. Then, recreate the resources in Procedure 3.
Deleting userApplication
Delete the existing userApplication by using the userApplication Configuration Wizard. At this time, select "Delete only userApplication."
For more details, see "10.3.1 Changing the Cluster Application Configuration."
Recreating the takeover network and process monitoring resources
If the takeover network resource and the process monitoring resource are registered in the cluster system, first delete and then recreate those resources.
See "10.5 Deleting a Resource," "6.7.1.5 Creating Takeover Network Resources," and "6.7.1.7 Creating Process Monitoring Resources."
Recreating userApplication
Recreate the userApplication that was deleted in Procedure 2, using the same procedure as that used to create it. Note that the new node must be registered when SysNode is to be selected. For details, see "6.7.2 Creating Cluster Applications."
Copy /opt/SMAW/SMAWRrms/bin/hvenv.local of the existing node to /opt/SMAW/SMAWRrms/bin/ of the new node.
Edit /opt/SMAW/SMAWRrms/bin/hvenv.local in each node with the "vi" editor, and delete the following entry:
export HV_RCSTART=0
If the GFS shared file system is used in an existing node, set up the GFS shared file system on the new node by using the following procedure:
Procedure
Confirm the GFS daemon (sfcfrmd) is not running by executing the "ps" command on all cluster nodes. If GFS daemon is running, see Step 5 of "8.2.1.3 Connecting a Node" when stop the GFS daemon.
Execute sfcsetup on the new node, and then register the node information in the management partition.
Execute sfcfrmstart and then start up the GFS daemon on all cluster nodes.
Execute sfcnode on any one of the cluster nodes, and then add the node configuration information of the new node.
Create a mount point and set up /etc/vfstab on the new node.
Execute sfcmntgl on any one of the cluster nodes and then mount the GFS shared file system.
See
For information on how to use each command, see "PRIMECLUSTER Global File Services Configuration and Administration Guide."