Apache Hadoop環境で、Hadoop連携機能を利用する際の作業手順を示します。
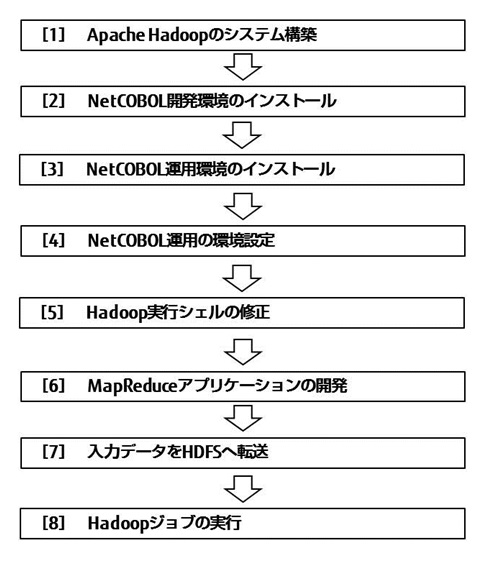
Apache Hadoopを導入します。マスタサーバ、スレーブサーバ、HDFSの導入が完了したら、手順[2]に進んでください。
COBOLアプリケーションをビルドするサーバにNetCOBOLの開発・運用パッケージをインストールします。
マスタサーバおよびスレーブサーバにNetCOBOLの運用パッケージをインストールします。COBOLアプリケーションをビルドするサーバとしてマスタサーバを選択した場合は、マスタサーバにNetCOBOLの運用パッケージをインストールする必要はありません。
MapReduceアプリケーションは、マスタサーバからスレーブサーバへのリモートコマンド実行(デフォルトでは SSH)によって起動されます。MapReduceジョブ実行ユーザーのログインシェルに、実行に必要な情報(環境変数や権限等)を設定してください。
利用するHadoopのバージョンに合わせて、Hadoop実行シェルを修正します。詳細は“Hadoopジョブの実行”を参照してください。
MapReduceアプリケーションは、NetCOBOLの開発環境を使用して開発します。詳細は“MapReduceアプリケーションの開発”を参照してください。
Apache Hadoopのコマンドを使用して、入力データをHDFSに転送します。
Hadoop実行シェルを利用して、MapReduceアプリケーションを実行します。詳細は“Hadoopジョブの実行”を参照してください。