Hadoop連携機能には、以下の特徴があります。
MapタスクおよびReduceタスクをそれぞれCOBOLアプリケーションとして実行することができます。
(このCOBOLアプリケーションのことを、以降MapReduceアプリケーションといいます)
MapReduceアプリケーションでは、COBOLのファイルをREAD/WRITE文でアクセスすることができます。
複数のファイルを入力にすることができます。
MapReduceアプリケーションの入出力ファイルを以下の呼び名で表現します。
Hadoop入力データファイル
Map入力データファイル
Map出力データファイル
Reduce入力データファイル
Reduce出力データファイル
Hadoop出力データファイル
これらのファイルで利用可能なファイル編成は以下のとおりです。
行順ファイル
レコード順ファイル
物理順ファイル
これらのファイルは、MapReduceアプリケーションでアクセスするためにファイル識別名やファイル編成をあらかじめ設定ファイルに記述しておく必要があります。この設定ファイルを「MapReduce設定ファイル」といいます。
なお、入出力処理の対象となるファイルの割当ては、COBOLランタイムシステムが自動的に行います。このため、ファイル識別名に対応するファイル名の指定を利用者が行う必要はありません。
参考
物理順ファイルは、富士通のメインフレーム上で動作するCOBOL85でサポートされているファイル編成です。
COBOLアプリケーションで物理順ファイルを直接入出力することはできません。このため、SIMPLIA/TF-MDPORT等を利用してMapReduceアプリケーションでデータや文字コードの変換を行う必要があります。
注意
Hadoop連携機能で利用可能な物理順ファイルは以下の形式です。
可変長レコード形式(V 形式レコード)の物理順ファイル(※)かつ、
BDW(Block Descriptor Word)を持たないファイルかつ、
RDW(Record Descriptor Word)を持つファイル。
※ 固定長レコード形式(F形式レコード)については、レコード順固定長ファイルとして利用することができます。
MapReduceアプリケーションと入出力ファイル、MapReduce設定ファイルの概念を以下の図に示します。
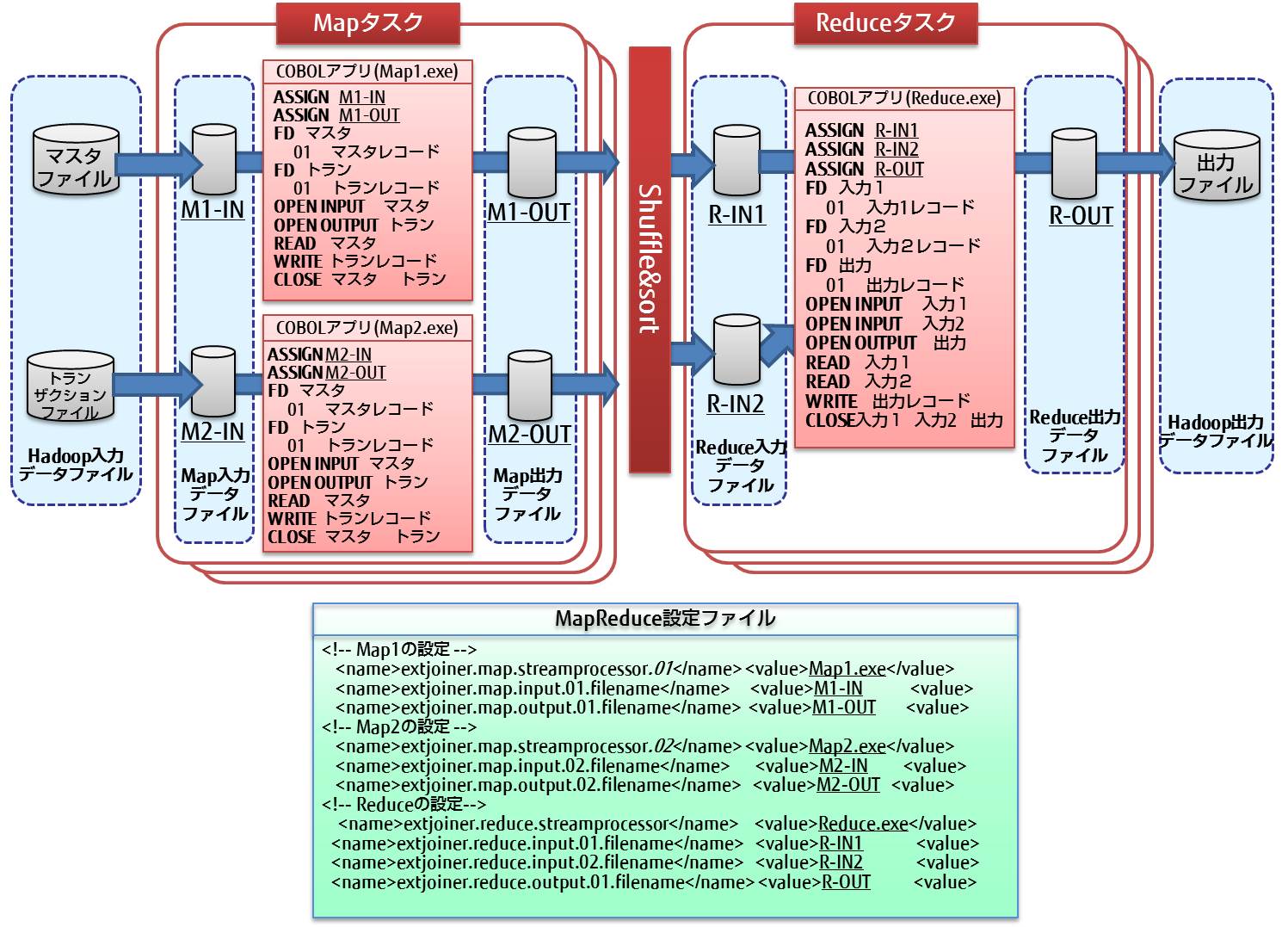
以降では、各ファイルとMapタスク、Shuffle&sort、およびReduceタスクについて説明します。