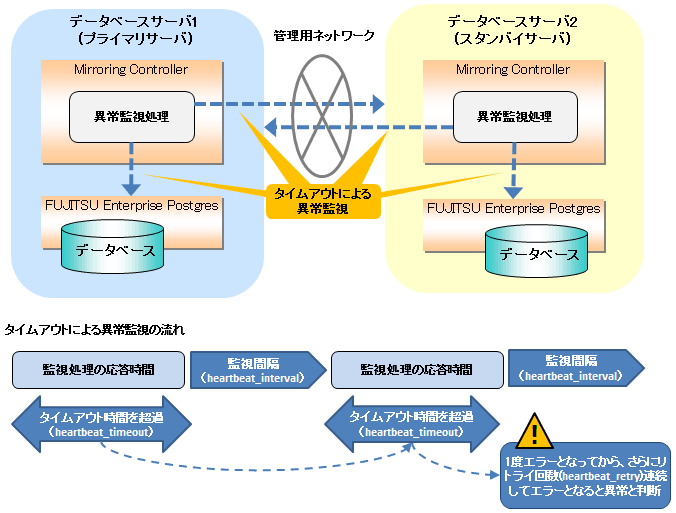
Mirroring Controllerには監視対象の資源へのアクセスがタイムアウト時間を越えたことで異常と判断する監視方法があります。このタイムアウト時間が短いと、スタンバイサーバの切り替え/切り離しを高速に行うことができる一方、誤検知のリスクがあるため、適切な設計が必要となります。
サーバ定義ファイルの以下のパラメータをシステムに応じた値に編集することで縮退運転の最適化を行うことができます。また、これらのパラメータを編集するには、“付録A パラメータ”を参照してください。
パラメータ | 指針 |
|---|---|
異常監視の監視間隔 | Mirroring Controllerによる異常監視がシステムに負荷を与えない範囲で設定しますが、通常は設定不要です(省略値は800ミリ秒)。 |
異常監視のタイムアウト時間 | サーバやネットワークの能力に対して負荷が継続的に掛かる時間を設定します。例えば、高負荷のバッチ業務を実行する場合や高多重のオンライン業務が連続的に発生するような場合が想定されます。 |
異常監視のリトライ回数 | 負荷が流動的なシステムなど、heartbeat_timeoutで指定した値を超える事象に対して安全値が必要な場合に設定しますが、通常は設定不要です(省略値は2回)。 |
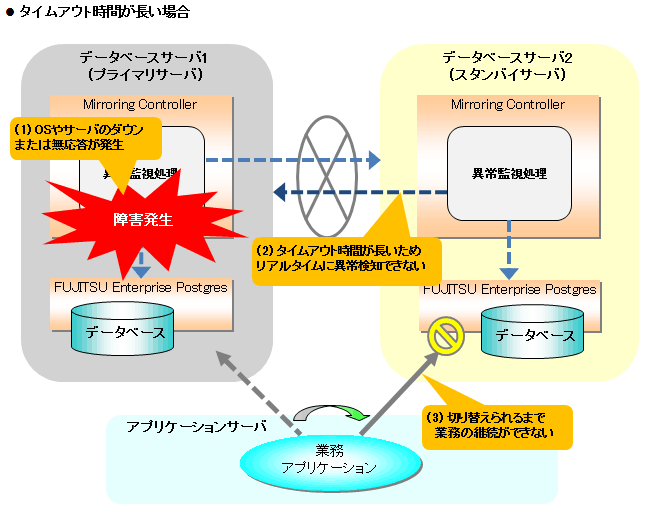
異常監視に関するチューニングが適切に行われていない場合には、以下のような事象が発生します。
OSやサーバのダウンおよび無応答による監視についての注意事項
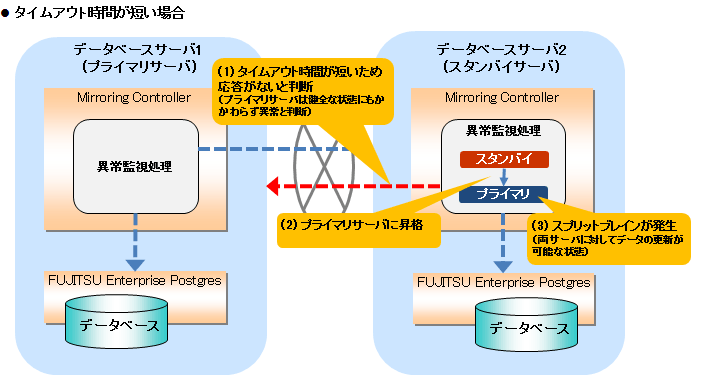
OSやサーバのダウンおよび無応答は上記の通りタイムアウトによる監視を行っています。そのため、チューニングが正しく行われていないと、サーバが健全な状態にもかかわらず誤ってスプリットブレインを発生させる危険性があります。
スプリットブレインとは、一時的に両サーバがプライマリサーバとして動作してしまうために、両サーバでデータの更新業務が行われる現象をいいます。
以下の条件の場合にスプリットブレインが発生していることが確認できます。
両サーバでmc_ctlコマンドをstatusモードで実行した結果、両サーバの“host_role”が“primary”と出力される。かつ、
いずれかのサーバのシステムログに、以下のメッセージが出力されている。
プライマリサーバへの昇格処理が完了しました (MCA00062)
以下の手順で行います。なお、新プライマリサーバは上記の検出方法の2)で確認されたサーバとなります。
旧プライマリサーバおよび新プライマリサーバで動作しているすべてのアプリケーションを停止します。
データベースの調査と復旧を行います。
新プライマリサーバに反映されていない更新結果を旧プライマリサーバのデータベースから調査して、必要に応じて新プライマリサーバに適用します。
旧プライマリサーバのインスタンスおよびMirroring Controllerを停止します。
手順1.で停止したアプリケーションを再開します。
旧プライマリサーバを復旧します。
“3.4 スタンバイサーバのセットアップ”を参照して、新プライマリサーバから旧プライマリサーバを新スタンバイサーバとして構築(セットアップ)します。
注意
上記のチューニングは、タイムアウトを検知してからプライマリサーバを切り替えるなどの操作を行うまでの時間に影響します。そのため、誤検知を行わない設計を行った上で、切り替え/切り離し時間を考慮した値に補正してください。