文字コード変換は、データを作成したコンピュータのOSによる文字コードの相違を解消させる機能です。
フォーマット変換は、入出力ともに同一の文字コード(シフトJIS、EUC、UTF-8/UCS-2、UTF-8/UTF-16、UTF-8/UTF-32)で行うことが前提です。したがって、入出力データの文字コードが異なっている場合には、フォーマット変換の前後どちらかで文字コード変換を実施しておく必要があります。
文字コード変換できるデータは、属性を意識しながら変換するため、Formatmanagerクライアントに登録されているフォーマットに限ります。
登録方法
[運用情報登録(文字コード変換)]画面で、以下の内容を設定します。
ファイル種別
フォーマットID
変換元文字コード
変換先文字コード
設定方法の詳細は、“ISI Formatmanagerクライアント(FEDIT/FL-TABLE)ヘルプ”、および“ISI Formatmanagerクライアント(FEDIT/FL-TABLE)チュートリアル”を参照してください。
文字コード変換のパターン
文字コード変換できるパターンは以下のとおりです。文字コード変換が可能な文字コード系の組み合わせは、文字コード変換ルールにより異なります。文字コード変換ルールは、FEDITシステムパラメタ定義ファイルの“CharCodeConversionRule”で指定します。FEDITシステムパラメタ定義ファイルについては、“ISI 導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更” または“ISI Java EE導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更”を参照してください。
以下に各文字コード変換ルールで使用できる文字コードの組み合わせを「○」「×」で示します。
MODE1(Formatmanager独自の変換規則)
MODE2(標準コード変換の変換規則)
MODE3(高速コード変換の変換規則)
入力データの文字コード | 出力データの文字コード | 文字コード変換ルール | ||||
|---|---|---|---|---|---|---|
1バイト系 | 2バイト系 | 1バイト系 | 2バイト系 | MODE1 | MODE2 | MODE3 |
JIS8 | シフトJIS | JIS7 | EUC | ○ | ○ | ○ |
EBCDICカナ | JEF | ○ | ○ | ○ | ||
EBCDIC ASCII | JEF | ○ | ○ | ○ | ||
EBCDICカナ | dbcs90 | ○ | ○ | ○ | ||
EBCDIC ASCII | dbcs90 | ○ | ○ | ○ | ||
JIS (7単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (8単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (ESCで切換え) | JIS | × | ○ | ○ | ||
EBCDICカナ | KEIS | × | ○ | ○ | ||
EBCDICカナ | JIPS(E) 領域重視 | × | ○ | ○ | ||
EBCDICカナ | JIPS(E) 字形重視 | × | ○ | ○ | ||
UNICODE(UCS-2BE) | × | ○ | ○ | |||
UNICODE(UCS-2LE) | × | ○ | ○ | |||
UNICODE(UTF-16BE) | × | ○ | ○ | |||
UNICODE(UTF-16LE) | × | ○ | ○ | |||
UNICODE(UTF-32BE) | × | ○ | ○ | |||
UNICODE(UTF-32LE) | × | ○ | ○ | |||
JIS7 | EUC | JIS8 | シフトJIS | ○ | ○ | ○ |
EBCDICカナ | JEF | ○ | ○ | ○ | ||
EBCDIC ASCII | JEF | ○ | ○ | ○ | ||
EBCDICカナ | dbcs90 | ○ | ○ | ○ | ||
EBCDIC ASCII | dbcs90 | ○ | ○ | ○ | ||
JIS (7単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (8単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (ESCで切換え) | JIS | × | ○ | ○ | ||
EBCDICカナ | KEIS | × | ○ | ○ | ||
EBCDICカナ | JIPS(E) 領域重視 | × | ○ | ○ | ||
EBCDICカナ | JIPS(E) 字形重視 | × | ○ | ○ | ||
UNICODE(UCS-2BE) | × | ○ | ○ | |||
UNICODE(UCS-2LE) | × | ○ | ○ | |||
UNICODE(UTF-16BE) | × | ○ | ○ | |||
UNICODE(UTF-16LE) | × | ○ | ○ | |||
UNICODE(UTF-32BE) | × | ○ | ○ | |||
UNICODE(UTF-32LE) | × | ○ | ○ | |||
EBCDICカナ | JEF | JIS8 | シフトJIS | ○ | ○ | ○ |
JIS7 | EUC | ○ | ○ | ○ | ||
EBCDIC ASCII | JEF | ○ | × | × | ||
UNICODE(UCS-2BE) | × | ○ | ○ | |||
UNICODE(UCS-2LE) | × | ○ | ○ | |||
UNICODE(UTF-16BE) | × | ○ | ○ | |||
UNICODE(UTF-16LE) | × | ○ | ○ | |||
UNICODE(UTF-32BE) | × | ○ | ○ | |||
UNICODE(UTF-32LE) | × | ○ | ○ | |||
EBCDIC ASCII | JEF | JIS8 | シフトJIS | ○ | ○ | ○ |
JIS7 | EUC | ○ | ○ | ○ | ||
EBCDICカナ | JEF | ○ | × | × | ||
UNICODE(UCS-2BE) | × | ○ | ○ | |||
UNICODE(UCS-2LE) | × | ○ | ○ | |||
UNICODE(UTF-16BE) | × | ○ | ○ | |||
UNICODE(UTF-16LE) | × | ○ | ○ | |||
UNICODE(UTF-32BE) | × | ○ | ○ | |||
UNICODE(UTF-32LE) | × | ○ | ○ | |||
EBCDICカナ | dbcs90 | JIS8 | シフトJIS | ○ | ○ | ○ |
JIS7 | EUC | ○ | ○ | ○ | ||
EBCDIC ASCII | dbcs90 | JIS8 | シフトJIS | ○ | ○ | ○ |
JIS7 | EUC | ○ | ○ | ○ | ||
JIS (7単位半角カナ) | JIS | JIS8 | シフトJIS | × | ○ | ○ |
JIS7 | EUC | × | ○ | ○ | ||
UNICODE(UCS-2BE) | × | ○ | ○ | |||
UNICODE(UCS-2LE) | × | ○ | ○ | |||
UNICODE(UTF-16BE) | × | ○ | ○ | |||
UNICODE(UTF-16LE) | × | ○ | ○ | |||
UNICODE(UTF-32BE) | × | ○ | ○ | |||
UNICODE(UTF-32LE) | × | ○ | ○ | |||
JIS (8単位半角カナ) | JIS | JIS8 | シフトJIS | × | ○ | ○ |
JIS7 | EUC | × | ○ | ○ | ||
UNICODE(UCS-2BE) | × | ○ | ○ | |||
UNICODE(UCS-2LE) | × | ○ | ○ | |||
UNICODE(UTF-16BE) | × | ○ | ○ | |||
UNICODE(UTF-16LE) | × | ○ | ○ | |||
UNICODE(UTF-32BE) | × | ○ | ○ | |||
UNICODE(UTF-32LE) | × | ○ | ○ | |||
JIS (ESCで切換え) | JIS | JIS8 | シフトJIS | × | ○ | ○ |
JIS7 | EUC | × | ○ | ○ | ||
UNICODE(UCS-2BE) | × | ○ | ○ | |||
UNICODE(UCS-2LE) | × | ○ | ○ | |||
UNICODE(UTF-16BE) | × | ○ | ○ | |||
UNICODE(UTF-16LE) | × | ○ | ○ | |||
UNICODE(UTF-32BE) | × | ○ | ○ | |||
UNICODE(UTF-32LE) | × | ○ | ○ | |||
EBCDICカナ | KEIS | JIS8 | シフトJIS | × | ○ | ○ |
JIS7 | EUC | × | ○ | ○ | ||
EBCDICカナ | JIPS(E) 領域重視 | JIS8 | シフトJIS | × | ○ | ○ |
JIS7 | EUC | × | ○ | ○ | ||
EBCDICカナ | JIPS(E) 字形重視 | JIS8 | シフトJIS | × | ○ | ○ |
JIS7 | EUC | × | ○ | ○ | ||
UNICODE(UCS-2BE) | JIS8 | シフトJIS | × | ○ | ○ | |
JIS7 | EUC | × | ○ | ○ | ||
EBCDICカナ | JEF | × | ○ | ○ | ||
EBCDIC ASCII | JEF | × | ○ | ○ | ||
JIS (7単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (8単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (ESCで切換え) | JIS | × | ○ | ○ | ||
UNICODE(UCS-2LE) | JIS8 | シフトJIS | × | ○ | ○ | |
JIS7 | EUC | × | ○ | ○ | ||
EBCDICカナ | JEF | × | ○ | ○ | ||
EBCDIC ASCII | JEF | × | ○ | ○ | ||
JIS (7単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (8単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (ESCで切換え) | JIS | × | ○ | ○ | ||
UNICODE(UTF-16BE) | JIS8 | シフトJIS | × | ○ | ○ | |
JIS7 | EUC | × | ○ | ○ | ||
EBCDICカナ | JEF | × | ○ | ○ | ||
EBCDIC ASCII | JEF | × | ○ | ○ | ||
JIS (7単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (8単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (ESCで切換え) | JIS | × | ○ | ○ | ||
UTF-8(4バイト) | × | × | ○ | |||
UTF-16BE | × | × | ○ | |||
UTF-16LE | × | × | ○ | |||
UTF-32BE | × | × | ○ | |||
UTF-32LE | × | × | ○ | |||
UNICODE(UTF-16LE) | JIS8 | シフトJIS | × | ○ | ○ | |
JIS7 | EUC | × | ○ | ○ | ||
EBCDICカナ | JEF | × | ○ | ○ | ||
EBCDIC ASCII | JEF | × | ○ | ○ | ||
JIS (7単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (8単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (ESCで切換え) | JIS | × | ○ | ○ | ||
UTF-8(4バイト) | × | × | ○ | |||
UTF-16BE | × | × | ○ | |||
UTF-16LE | × | × | ○ | |||
UTF-32BE | × | × | ○ | |||
UTF-32LE | × | × | ○ | |||
UNICODE(UTF-32BE) | JIS8 | シフトJIS | × | ○ | ○ | |
JIS7 | EUC | × | ○ | ○ | ||
EBCDICカナ | JEF | × | ○ | ○ | ||
EBCDIC ASCII | JEF | × | ○ | ○ | ||
JIS (7単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (8単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (ESCで切換え) | JIS | × | ○ | ○ | ||
UTF-8(4バイト) | × | × | ○ | |||
UTF-16BE | × | × | ○ | |||
UTF-16LE | × | × | ○ | |||
UTF-32BE | × | × | ○ | |||
UTF-32LE | × | × | ○ | |||
UNICODE(UTF-32LE) | JIS8 | シフトJIS | × | ○ | ○ | |
JIS7 | EUC | × | ○ | ○ | ||
EBCDICカナ | JEF | × | ○ | ○ | ||
EBCDIC ASCII | JEF | × | ○ | ○ | ||
JIS (7単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (8単位半角カナ) | JIS | × | ○ | ○ | ||
JIS (ESCで切換え) | JIS | × | ○ | ○ | ||
UTF-8(4バイト) | × | × | ○ | |||
UTF-16BE | × | × | ○ | |||
UTF-16LE | × | × | ○ | |||
UTF-32BE | × | × | ○ | |||
UTF-32LE | × | × | ○ | |||
UTF-8(4バイト) | UNICODE(UCS-2BE) | × | × | ○ | ||
UNICODE(UCS-2LE) | × | × | ○ | |||
UNICODE(UTF-16BE) | × | × | ○ | |||
UNICODE(UTF-16LE) | × | × | ○ | |||
UNICODE(UTF-32BE) | × | × | ○ | |||
UNICODE(UTF-32LE) | × | × | ○ | |||
UTF-16BE | UNICODE(UTF-16BE) | × | × | ○ | ||
UNICODE(UTF-16LE) | × | × | ○ | |||
UNICODE(UTF-32BE) | × | × | ○ | |||
UNICODE(UTF-32LE) | × | × | ○ | |||
UTF-16LE | UNICODE(UTF-16BE) | × | × | ○ | ||
UNICODE(UTF-16LE) | × | × | ○ | |||
UNICODE(UTF-32BE) | × | × | ○ | |||
UNICODE(UTF-32LE) | × | × | ○ | |||
UTF-32BE | UNICODE(UTF-16BE) | × | × | ○ | ||
UNICODE(UTF-16LE) | × | × | ○ | |||
UNICODE(UTF-32BE) | × | × | ○ | |||
UNICODE(UTF-32LE) | × | × | ○ | |||
UTF-32LE | UNICODE(UTF-16BE) | × | × | ○ | ||
UNICODE(UTF-16LE) | × | × | ○ | |||
UNICODE(UTF-32BE) | × | × | ○ | |||
UNICODE(UTF-32LE) | × | × | ○ | |||
注意
FEDITシステムパラメタ定義ファイルのIdentifyRecordMode定義文に互換モード(COMPATIBLE1またはCOMPATIBLE2)を指定している場合、伝票形式フォーマットの文字コード変換においてエンコーディングが混在しないUnicode系文字コード(UTF-8(4バイト)、UTF-16BE、UTF-16LE、UTF-32BE、UTF-32LE)は使用できません。
文字コード変換において、各属性は以下のように処理されます。
属性 | 処理内容 |
|---|---|
X属性(注) | 文字コード変換を行います。
|
K属性(注) | 文字コード変換を行います。 |
B属性 | 文字コード変換を行いません。入力データをそのまま複写するか、またはエンディアン交換を行って複写します。 |
H属性 | 文字コード変換を行いません。入力データをそのまま複写します。 |
N属性 | 文字コード変換を行います。 |
9属性 | 文字コード変換を行います。変換先の符号を示す部分には、文字コードがシフトJIS/EUCの場合は、FEDITシステムパラメタ定義ファイルの指定に従った値が出力されます。EBCDICの場合は、プラスコード(0xC)、マイナスコード(0xD)、符号なし(0xF)が出力されます。 FEDITシステムパラメタ定義ファイルについては、“ISI 導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更” または“ISI Java EE導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更”を参照してください。 |
C属性 | 文字コード変換を行います。 |
P属性 | 文字コード変換を行いません。数値を示す部分の入力データをそのまま複写します。変換先の符号を示す部分には、文字コードがシフトJIS/EUCの場合は、FEDITシステムパラメタ定義ファイルの指定に従った値が出力されます。EBCDICの場合は、プラスコード(0xC)、マイナスコード(0xD)、符号なし(0xF)が出力されます。 FEDITシステムパラメタ定義ファイルについては、“ISI 導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更” または“ISI Java EE導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更”を参照してください。 |
(注) 半角全角が混在している項目には、X属性を指定してください。
エンコーディングが混在するUnicode系文字コードでの各属性の文字コード
エンコーディングが混在するUnicode系文字コードで各属性に適用される文字コードは以下のとおりです。
属性 | UNICODE(UCS-2BE) | UNICODE(UCS-2LE) | UNICODE(UTF-16BE) | UNICODE(UTF-16LE) | UNICODE(UTF-32BE) | UNICODE(UTF-32LE) | 備考 |
|---|---|---|---|---|---|---|---|
X属性 | UTF-8(3バイト)(注3) | UTF-8(3バイト) | UTF-8(4バイト)(注4) | UTF-8(4バイト) | UTF-8(4バイト)(注4) | UTF-8(4バイト) |
|
K属性 | UCS-2BE | UCS-2LE | UTF-16BE | UTF-16LE | UTF-32BE(注5) | UTF-32LE(注5) | ASCII範囲内を除く(注1) |
B属性 | バイナリ | バイナリ | バイナリ | バイナリ | バイナリ | バイナリ |
|
H属性 | バイナリ | バイナリ | バイナリ | バイナリ | バイナリ | バイナリ |
|
N属性 | UTF-8(3バイト)(注2) | UTF-8(3バイト)(注2) | UTF-8(4バイト)(注2) | UTF-8(4バイト)(注2) | UTF-8(4バイト)(注2) | UTF-8(4バイト)(注2) |
|
9属性 | UTF-8(3バイト)(注2) | UTF-8(3バイト)(注2) | UTF-8(4バイト)(注2) | UTF-8(4バイト)(注2) | UTF-8(4バイト)(注2) | UTF-8(4バイト)(注2) | 符号部はASCII系(カスタマイズ可) |
C属性 | UTF-8(3バイト)(注2) | UTF-8(3バイト)(注2) | UTF-8(4バイト)(注2) | UTF-8(4バイト)(注2) | UTF-8(4バイト)(注2) | UTF-8(4バイト)(注2) |
|
P属性 | バイナリ | バイナリ | バイナリ | バイナリ | バイナリ | バイナリ | 符号部はASCII系(カスタマイズ可) |
(注1)ASCII系(0x00~0x7f)のコードが指定されていた場合は、変換不当となります。
(注2)使用可能な文字の範囲が限られているので、ASCII系(0x00~0x7f)と同等のコードになります。
(注3)“UTF-8(3バイト)”は1~3バイトで表現されるUCS-2の範囲のUTF-8を示します。
(注4)“UTF-8(4バイト)”は1~4バイトで表現されるUCS-4の範囲のUTF-8を示します。
(注5)UNICODE(UTF-32BE)またはUNICODE(UTF-32LE)を使用する場合、K属性項目の項目長は4の倍数桁にする必要があります。
エンコーディングが混在しないUnicode系文字コードでの各属性の文字コード
エンコーディングが混在しないUnicode系文字コードで各属性に適用される文字コードは以下のとおりです。
属性 | UTF-8(4バイト) | UTF-16BE | UTF-16LE | UTF-32BE | UTF-32LE | 備考 |
|---|---|---|---|---|---|---|
X属性 | UTF-8(4バイト) | UTF-16BE | UTF-16LE | UTF-32BE | UTF-32LE |
|
K属性 | UTF-8(4バイト) | UTF-16BE | UTF-16LE | UTF-32BE | UTF-32LE | ASCII範囲内を除く(注2) |
B属性 | バイナリ | バイナリ | バイナリ | バイナリ | バイナリ |
|
H属性 | バイナリ | バイナリ | バイナリ | バイナリ | バイナリ |
|
N属性 | UTF-8(4バイト) | UTF-16BE | UTF-16LE | UTF-32BE | UTF-32LE |
|
9属性 | UTF-8(4バイト) | UTF-16BE | UTF-16LE | UTF-32BE | UTF-32LE | 符号部はASCII系(カスタマイズ可) |
C属性 | UTF-8(4バイト) | UTF-16BE | UTF-16LE | UTF-32BE | UTF-32LE |
|
P属性 | バイナリ | バイナリ | バイナリ | バイナリ | バイナリ | 符号部はASCII系(カスタマイズ可) |
(注1)“UTF-8(4バイト)”は1~4バイトで表現されるUCS-4の範囲のUTF-8を示します。
(注2)ASCII系(0x00~0x7f)のコードが指定されていた場合は、変換不当となります。
(注3)使用可能な文字の範囲が限られているので、ASCII系(0x00~0x7f)と同等のコード範囲になります。
(注4)UTF-16BEまたはUTF-16LEを使用する場合、項目長は2の倍数桁にする必要があります。
(注5)UTF-32BEまたはUTF-32LEを使用する場合、項目長は4の倍数桁にする必要があります。
変換先と変換元の文字コードが同一な場合の処理内容
変換先と変換元の文字コードに、エンコーディングが混在するUnicodeとエンコーディングが混在しないUnicodeの組み合わせを指定している場合、属性によって適用される文字コードが変換元と変換先で同一になる場合があります。
変換元と変換先で適用される文字コードが同一な場合、以下のように処理されます。
属性 | 処理内容 |
|---|---|
X属性 | 文字コード変換を行いません。入力データをそのまま複写します。 |
K属性 | 文字コード変換を行いません。入力データをそのまま複写します。 |
B属性 | 文字コード変換を行いません。 |
H属性 | 文字コード変換を行いません。 |
N属性 | 文字コード変換を行います。 |
9属性 | 文字コード変換を行います。 |
C属性 | 文字コード変換を行います。 |
P属性 | 文字コード変換を行いません。 |
シフトJISの半角カナをEUCに変換した場合に、変換前のデータ長が変換後のデータ長の2倍になったり、JEFやdbcs90で制御文字(シフトインコード/シフトアウトコードなど)が付加されたりして、文字コード変換後のデータが、定義された項目のバイト数(桁数)を超える場合(桁あふれ)があります。文字コード変換のパターンを考慮し、桁あふれが発生しないサイズを一般フォーマットの拡張桁数に設定して、文字コード変換する必要があります。
なお、桁あふれが起きた場合、Formatmanagerではワーニングを出力し、定義された項目のバイト数分値をセットして、以降のデータを切り捨てます。
桁あふれが発生した場合の処理の詳細は、以下のとおりです。
変換先コードがEUC・シフトJIS・UNICODE(UCS-2BE)・UNICODE(UCS-2LE)・UNICODE(UTF-16BE)・UNICODE(UTF-16LE)・UNICODE(UTF-32BE)・UNICODE(UTF-32LE)・UTF-8(4バイト)・UTF-16BE・UTF-16LE・UTF-32BE・UTF-32LEの場合
文字コード変換により漢字コードの一部が桁あふれを起こした場合、そのコードは代替文字に置き換わります(ワーニング0x800a)。置き換わる文字については“代替文字について”を参照してください。
ただし、全角空白文字の一部が桁あふれを起こしかつ、以降すべてが空白である場合に限りワーニングは出力されません。(注1)
(例:EBCDICカナ「アアア□□」→EUC 「@ア@ア@ア_」
アは半角カナのイメージ、@:半角カナはEUCで2バイトになるので付加コードのイメージ、□:全角空白、_:半角空白)
変換先コードがJEF・dbcs90・JIS・KEIS・JIPS(E) 領域重視・JIPS(E) 字形重視の場合
文字コード変換により漢字コードの一部が桁あふれを起こした場合、そのコードは漢字シフトアウトコードに置き換わります(ワーニング0x800a)。
ただし、全角空白文字の一部が桁あふれを起こし、かつ以降すべてが空白である場合に限りワーニングは出力されません。
(例:EUC「1個2個3個□□□」→JEF「1@個@2@個@3@個@」
□:全角空白、_:半角空白、@:制御文字)
また、漢字シフトアウトコードだけが格納できない場合は、ワーニング出力は行いません。漢字シフトイン状態のままとなります。
一部が桁あふれを起こし、その漢字コードの直前が漢字シフトインコードの場合は、漢字シフトインコードも削除されて、半角空白が詰められます。
可能な限り、漢字シフトアウト状態で完結するようにしますが、漢字シフトアウトコードだけが出力できない場合に限り、漢字シフトイン状態で完結します。
(注1) UTF-32では、以下のデータを空白として扱います。
エンディアン | 文字の位置 | 末尾の文字の長さ | 空白として扱うデータ |
|---|---|---|---|
ビッグエンディアン | 末尾 | 1バイト | {0x00} |
2バイト | {0x00, 0x00} | ||
3バイト | {0x00, 0x00, 0x00} | ||
4バイト | {0x00, 0x00, 0x30, 0x00} | ||
末尾以外 | - | {0x00, 0x00, 0x30, 0x00} | |
リトルエンディアン | 末尾 | 1バイト | {0x00} |
2バイト | {0x00, 0x00} | ||
3バイト | {0x00, 0x00, 0x00} | ||
4バイト | {0x00, 0x30, 0x00, 0x00} | ||
末尾以外 | - | {0x00, 0x30, 0x00, 0x00} |
末尾の文字の長さが4バイト未満の場合、すべてのバイトが最終詰め文字(0x00)のデータを空白として扱います。
変換先がJEFの場合、漢字シフトインコードは、常に0x28となります。変換先項目がX属性の場合には、必要に応じて漢字シフトコードを付加します。変換先項目がK属性の場合には、漢字シフトコードは付加しません。
変換元がJEFの場合、漢字シフトインコードは、0x28/0x38のどちらでもかまいません (dbcs90では0x0eだけなので問題ありません)。変換元項目がX属性の場合には、漢字シフトコードが含まれていることを前提に処理します。漢字シフトコードが含まれていないと結果は不定です。変換元項目がK属性の場合には、漢字シフトコードが含まれていないことを前提に処理します。漢字シフトコードが含まれていると結果は不定です。
文字コード変換機能は、内蔵している「標準コード変換」(iconv)を使用しており、その仕様に従います。また、Formatmanagerの動作するマシンにInterstage Charset Managerがインストールされていて、かつFEDITシステムパラメタ定義ファイルのUseCharsetManager定義文に“TRUE”が指定されている場合には、そちらの標準コード変換が使用されます。Charset Manager 6.0/V6.0L10以降の標準コード変換に対応しています。なお、Formatmanagerの動作するマシンにInterstage Charset Managerがインストールされていない場合は、文字コード変換表が使用できないため、規定されたコード範囲外の文字(外字)の変換はできません。標準コード変換の詳細は、Interstage Charset Managerのマニュアルを参照してください。また、FEDITシステムパラメタ定義ファイルについては、“ISI 導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更” または“ISI Java EE導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更”を参照してください。
標準コード変換におけるコード変換仕様は、環境変数ICONV_CONVERT_TYPEの指定に従います。dbcs90・KEIS・JIPS(E)とEUCとの変換におけるEUCコードの種別は、標準コード変換における“S90”相当に固定です。また、dbcs90・KEIS・JIPS(E)とシフトJISとの変換におけるシフトJISコードの種別は、標準コード変換における“SJISMS”相当に固定です。
本バージョンからの標準コード変換を使用した変換規則と、従来バージョンのFormatmanager独自の変換規則は異なります。異なる点を、以下に示します。
[標準コード変換とFormatmanager独自変換規則の違い]
1バイトコード系の変換規則 (標準コード変換:標準コード変換の変換規則、Formatmanager:F6680準拠)
1バイトコード系の制御コード (標準コード変換:制御コードあり、Formatmanager:制御コードなし)
変換不可能置換文字 (置き換わる文字については“代替文字について”を参照してください。)
これらの変換規則を切り換えたい場合は、FEDITシステムパラメタ定義ファイルで変更することができます(デフォルトは標準コード変換です)。FEDITシステムパラメタ定義ファイルについては、“ISI 導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更” または“ISI Java EE導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更”を参照してください。
文字コード変換できない文字が入力された場合の置き換え文字については、“表6.38 文字コード変換ルールにおける代替文字”を参照してください。FEDITシステムパラメタ定義ファイルのCharCodeConversionRule定義文に定義した値により動作が異なります。FEDITシステムパラメタ定義ファイルについては、“ISI 導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更” または“ISI Java EE導入ガイド”の“FEDITシステムパラメタ定義ファイルの変更”を参照してください。
| CharCodeConversionRule にCOMPATIBLE または MODE1を指定した場合 | CharCodeConversionRule にSTANDARD または MODE2を指定した場合 | CharCodeConversionRule にMODE3を指定した場合 |
|---|---|---|---|
X属性項目の代替文字 | 半角空白または全角空白 | 標準コード変換のデフォルト動作(半角アンダースコアまたは全角アンダースコア) | 半角アンダースコアまたは全角アンダースコア |
K属性項目の代替文字 | 全角空白 | 全角空白 | 全角アンダースコア |
1つの入力ファイルに複数のフォーマットが混在するデータ(混在フォーマット)も文字コード変換ができます。混在フォーマットの文字コード変換では、入力データを異なる一般フォーマットが複数連なっている形式として扱い、それぞれの一般フォーマットに対して、文字コード変換を行います。そのため、入力レコードと出力レコードは文字コードが異なるだけで、出現順序は同じになります。
各レコードには、それぞれのレコードを識別する“識別子”を定義します。その識別子の値に応じて一般フォーマットが識別され、文字コード変換が行われます。
図6.45 混在フォーマット 文字コード変換の例
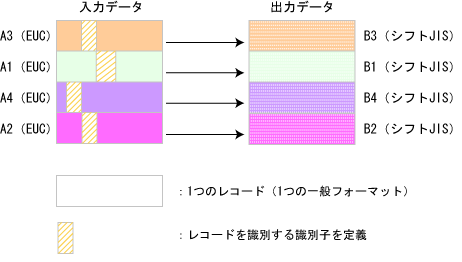
混在フォーマットの文字コード変換は、[混在フォーマット 文字コード変換]画面で、各レコードの識別子を定義して混在フォーマットIDを定義し、[運用登録]画面で混在フォーマットIDを指定することで実行することができます。
システムによっては、使用している文字コードの中でも、さらに使用できる文字の範囲を限定したい場合があります。例えば、「Unicodeでシステムを運用しているが、半角カナは使用不可とする」といった場合です。Formatmanagerの文字コード変換では、Interstage Charset Manager V8.2.0以降のCharset Validator機能を使用して、あらかじめ定義されたバリデーションポリシーに違反した文字を遮断できます。文字種ポリシーチェックは文字コードの変換のタイミングで行います。
文字種ポリシーチェック機能の利用に必要な定義や操作を、以下に示します。
[文字種ポリシーチェック機能の利用]
Formatmanagerが動作するマシンに、Interstage Charset Managerをインストールし、Charset Validator機能を利用可能にします。
Interstage Charset Managerの機能でバリデーションポリシーファイルを作成します。バリデーションポリシーファイルは、C言語用のコマンドで作成してください。詳細は、Interstage Charset Managerのマニュアルを参照してください。
作成したバリデーションポリシーファイルをFormatmanagerが動作するマシンに配置します。バリデーションポリシーファイルの配置方法は、“ISI 運用ガイド”の“バリデーションポリシーファイルの配置” または“ISI Java EE運用ガイド”の“バリデーションポリシーファイルの配置”を参照してください。
Formatmanagerクライアントを使用し、文字種ポリシー登録(文字種ポリシーIDの作成)、および一般フォーマット登録(文字種ポリシーチェックを行う項目に文字種ポリシーIDを設定)を行います。設定方法の詳細は、“ISI Formatmanagerクライアント(FEDIT/FL-TABLE)ヘルプ”を参照してください。
ポイント
文字種ポリシーチェック機能は、X属性、またはK属性の項目に対してだけ実行できます。
バリデーションポリシー違反を検出した場合、処理を中断するか、代替文字に置き換えて処理を続行するかを選択できます。
シフトコードを持つ文字コード系をチェックすることはできません。
文字種ポリシーチェック機能は、文字コード変換ルールが標準コード変換、または高速コード変換時だけ実行できます。