Symfoware Analytics Serverでは、テンソル解析を用いて外れ値検知アルゴリズムを組み込んだData Analytics Library for Pythonパッケージ“pgxa”を提供しています。このパッケージを使用して、Pythonスクリプトを作成することでデータ分析が行えます。パッケージの内容は以下の通りです。
サブモジュール名 | 説明 |
|---|---|
pgxa.desccat | 外れ値検知 |
パッケージは、以下に格納されています。
 [DWHサーバのインストールディレクトリ]\ext\PYTHON_PKG\pgxa
[DWHサーバのインストールディレクトリ]\ext\PYTHON_PKG\pgxa /opt/FJSVsymas/ext/PYTHON_PKG/pgxa
/opt/FJSVsymas/ext/PYTHON_PKG/pgxa![]() Python2.7以降で動作できます。
Python2.7以降で動作できます。
![]() Python2.6以降で動作できます。
Python2.6以降で動作できます。
テンソル解析を用いて複数項目を対象にクラスタリングを実施した結果から外れ値を検出します。
大規模離散データから特徴的なデータ集合を検出する場合に使用できます。利用シーンの例としてはサーバのアクセスログから通常のアクセスとは異なる不正アクセスのような異常な動作を検出できます。
従来のクラスタリング手法の課題である大量データに対応するために、クラスタリングは最小記述長原理に基づいた情報量の観点からデータ分割する手法で処理を実施しています。これは、pgxa.desccat.cluster()を実行することで実現できます。
また、数百万件のデータを入力として得られた数万個のクラスタに対してスコアリングを実施することで外れ値を検出します。
このクラスタの評価方法として圧縮率スコアのスコアリング方法を採用しています。
圧縮率スコア(pgxa.desccat.sccomp())は、クラスタ内にあるデータの符号長(ビット数)の圧縮率の平均値およびクラスタリング前のデータを比較して、その差分が大きいほど外れ値として評価します。
pgxa.desccat(外れ値検知)を構成する関数は以下のとおりです。
pgxa.desccat.cluster()
最小記述長に基づいたクラスタリングを行います。
pgxa.desccat.sccomp()
pgxa.desccat.clusterの出力結果に対して圧縮率スコアを算出します。
図6.3 外れ値検知の運用の流れ
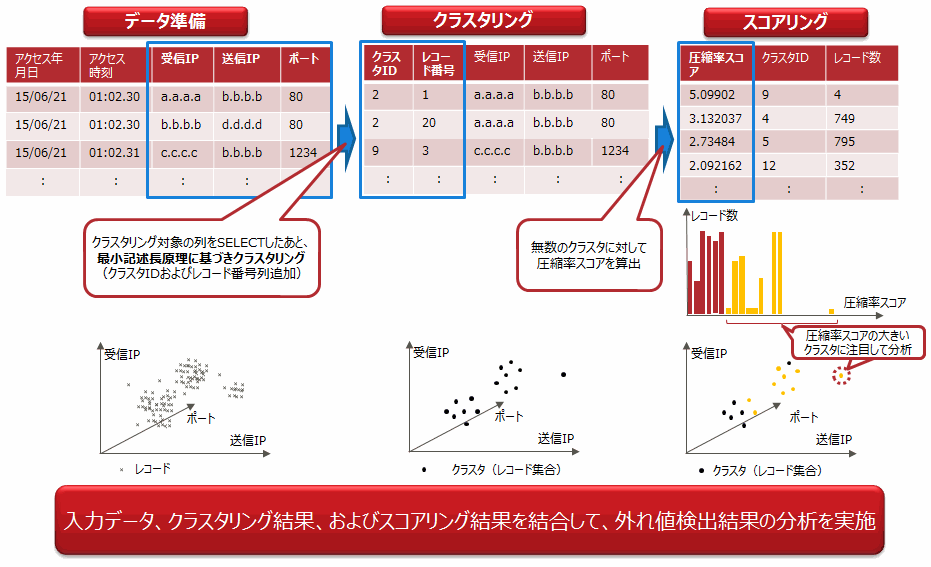
データ準備
対象のデータから外れ値検知として解析する列を選択して、クラスタリング実行時の入力データとします。入力データは、リスト型の辞書によるメモリまたはCSV形式のファイル名を指定してください。
クラスタリング
準備したデータに対するクラスタリングをpgxa.desccat.cluster()を使用して行います。
クラスタリングを行ったあと、各レコードにクラスタIDとレコード番号が付与されます。データ構造が類似したクラスタ(レコード集合)が生成されます。
クラスタIDとは、どのクラスタに分類されたかを示す識別子です。
スコアリング
クラスタリングの結果を入力とするスコアリング処理をpgxa.desccat.sccomp()を使用して行います。
圧縮率スコアが大きいものほどクラスタ内のレコード集合に外れ値があることを示します。このスコアをもとに圧縮率スコアが大きいクラスタに注目した分析および元データの内容と組み合わせたその他の分析を実施してください。また、圧縮率スコアが大きいクラスタに想定した特徴がみられない場合は、データ準備の列の選択から再度実施してください。
最小記述長に基づいたクラスタリングを行います。
書式
clusterdata = pgxa.desccat.cluster(
data=None,
colcnt=1,
loop=100,
loop_divide=100,
loop_marge=100,
epsilon1=0.01,
epsilon2=0.01)パラメーター
引数 | パラメーター | 必須 | 説明 |
|---|---|---|---|
第1引数 | data | ○ | 入力データをメモリまたはファイル名で指定します。
|
第2引数 | colcnt | カラム数をint型で指定します。省略した場合は、デフォルト値の1を採用します。
| |
第3引数 | loop | クラスタリング全体の最大ループ数をint型で指定します。1~100000の範囲で指定してください。省略した場合は、デフォルト値の100を採用します。 なお、通常はデフォルト値を指定してください。値を小さくすると処理速度が早くなりクラスタリングの精度が落ちる場合があります。 | |
第4引数 | loop_divide | クラスタ分割時の最大ループ数をint型で指定します。1~100000の範囲で指定してください。省略した場合は、デフォルト値の100を採用します。 なお、通常はデフォルト値を指定してください。値を小さくすると処理速度が早くなりクラスタリングの精度が落ちる場合があります。 | |
第5引数 | loop_marge | クラスタ結合時の最大ループ数をint型で指定します。1~100000の範囲で指定してください。省略した場合は、デフォルト値の100を採用します。 なお、通常はデフォルト値を指定してください。値を小さくすると処理速度が早くなりクラスタリングの精度が落ちる場合があります。 | |
第6引数 | epsilon1 | クラスタ分割時の評価値幅係数をfloat型で指定します。0~100の範囲でfloat型の実数値で指定してください。ただし、0は含みません。 データの内容により、クラスタを作成せずに終了する場合があります。その場合には、本引数の値を大きくすることでクラスタが生成されやすくなります。 | |
第7引数 | epsilon2 | クラスタ結合時の評価値幅係数をfloat型で指定します。0~100の範囲でfloat型の実数値で指定してください。ただし、0は含みません。 データの内容により、クラスタを作成せずに終了する場合があります。その場合には、本引数の値を大きくすることでクラスタが生成されやすくなります。ただし、第6引数の影響は小さいです。 |
注意
ループ数の変更は、第3引数loopを優先して変更してください。
評価値係数の変更は、第6引数epsilon1を優先して変更してください。
入力データは、カラム数の指定値に合わせて設定します。また、カラムに対応するデータ型は文字列で指定してください。
第1引数にメモリで指定した場合の指定方法
1レコードにlist型でカラム数分のデータをセットします。defaultdict型にlist型のデータをセットしてください。このデータを入力データに設定します。
カラム数が3の場合の入力データ例を以下に示します。
例)
レコード | list[0] 入力データ(list型にカラム数分をセット) | ||
|---|---|---|---|
defaultdict[1](list) | "a.a.a.a" | "b.b.b.b" | 80 |
defaultdict[2](list) | "b.b.b.b" | "d.d.d.d" | 80 |
defaultdict[3](list) | "c.c.c.c" | "b.b.b.b" | 1234 |
… | … | … | … |
第1引数にファイル名で指定した場合の指定方法
CSV形式のファイル名を指定します。データ形式は、文字コードは“UTF-8”(BOMなし)、改行コードには“LF”を指定します。その他の形式については、“H.4 CSVファイルのデータ形式”にしたがってください。
以下にカラム数が3の場合の入力データ例を示します。
例)
"a.a.a.a","b.b.b.b",80 "b.b.b.b","d.d.d.d",80 "c.c.c.c","b.b.b.b",1234
戻り値
パラメーター | 説明 |
|---|---|
clusterdata | クラスタリング結果データが返却されます。入力データの先頭2列にデータが追加されdefaultdict(list)型で返却されます。list型の先頭に第1列目クラスタID(int型)、第2列目レコード番号(int型)が追加されます。 |
クラスタリング結果データの出力を示します。
クラスタIDには、どのクラスタに分類されたかを示す識別子が1~レコード数の範囲で設定されます。また、レコード番号は入力データの行番号が設定されます。
例)
レコード | list[0] | list[1] | list[2] | ||
|---|---|---|---|---|---|
dict[1](list) | 10 | 1 | "a.a.a.a" | "b.b.b.b" | 80 |
dict[2](list) | 15 | 3 | "c.c.c.c" | "b.b.b.b" | 1234 |
dict[3](list) | 31 | 2 | "b.b.b.b" | "d.d.d.d" | 80 |
… | … | … | … | … | … |
例外
処理中に異常が発生した場合は、例外オブジェクトが返却されます。例外オブジェクトのメッセージ番号およびエラーメッセージの内容を参照して対処してください。
例外オブジェクト | 説明 |
|---|---|
pgxa.desccat.DesccatInputError | 入力パラメーターに誤りがあります。以下の情報を返却します。
|
pgxa.desccat.DesccatClusterError | クラスタリング処理中にエラーが発生しました。以下の情報を返却します。
|
実行例
import pgxa.desccat
from collections import defaultdict
data = defaultdict(list)
col = []
col.append("135.008.060.182")
col.append("172.016.112.050")
col.append(1106)
col.append(25)
data[1] = col
## data add #
try:
clusterdata = pgxa.desccat.cluster( data, 0, 100, 100, 100, 0.01, 0.01 );
except DesccatInputError , DesccatInternalError , DesccatClusterError as e:
print e.msgno :: e.msgpgxa.desccat.clusterの出力結果に対して圧縮率スコアを算出します。
書式
sccomp = pgxa.desccat.sccomp (clusterdata)
パラメーター
引数 | パラメーター | 必須 | 説明 |
|---|---|---|---|
第1引数 | clusterdata | ○ | pgax.desccat.clusterの出力結果を指定します。 |
戻り値
パラメーター | 説明 |
|---|---|
sccomp | 圧縮率スコアが返却されます。defaultdict(list)型で返却されます。クラスタID分のレコードが返却され、レコードの内容はlist型で以下の値が返却されます 1項目:圧縮率スコア 2項目:クラスタID 3項目:クラスタ内レコード数 |
圧縮率スコアの出力を示します。
例)
データ型 | list[0] | list[1] | list[2] |
|---|---|---|---|
defaultdict [1](list) | 2.639857 | 15 | 70 |
defaultdict [2](list) | 2.639857 | 31 | 24 |
defaultdict [3](list) | 2.13068 | 10 | 3 |
… | … | … | … |
例外
処理中に異常が発生した場合は、例外オブジェクトが返却されます。例外オブジェクトのメッセージ番号およびエラーメッセージの内容を参照して対処してください。
例外オブジェクト | 説明 |
|---|---|
pgxa.desccat.DesccatInputError | 入力パラメーターに誤りがあります。以下の情報を返却します。
|
pgxa.desccat.DesccatScoreError | スコアリング処理中にエラーが発生しました。以下の情報を返却します。
|
Symfoware Analytics Serverでは、Data Analytics Library Pythonパッケージを利用したデータ分析を行うサンプルスクリプトを提供しています。
pgxa.desccat.clusterおよびpgxa.desccat.sccompを用いて、クラスタリングおよびスコアリング結果を出力するサンプルスクリプトを以下に格納しています。
格納先)
[DWHサーバのインストールディレクトリ]\template\python\desccat_test.py/opt/FJSVsymas/template/python/desccat_test.pyサンプルスクリプトをもとに、実際に使用するスクリプトを作成してください。
サンプルスクリプトの処理の流れは以下の通りです。
入力データの作成
クラスタリングの実行(pgxa.desccat.cluster)
スコアリングの実行(pgxa.desccat.sccomp)
サンプルスクリプトの実行結果を以下に示します。
実行結果) DWHサーバインストールディレクトリが“C:\SymfoAS”である場合set PYTHONPATH=C:\SymfoAS\ext\PYTHON_PKG python C:\SymfoAS\template\python\desccat_test.py ## Input Data ## ['135.008.060.182', '172.016.112.050', 1106, 25] ['111.222.111.033', '172.016.112.050', 99, 25] Clustering:OK ## Clustering Result ## [1, 1, ['135.008.060.182', '172.016.112.050', 1106, 25]] [2, 2, ['111.222.111.033', '172.016.112.050', 99, 25]] Scoreing:OK ## Scoreing Result ## [0.6931471805599453, 2, 1] [0.6931471805599453, 1, 1]
実行結果)# PYTHONPATH=/opt/FJSVsymas/ext/PYTHON_PKG python /opt/FJSVsymas/template/python/desccat_test.py ## Input Data ## ['135.008.060.182', '172.016.112.050', 1106, 25] ['111.222.111.033', '172.016.112.050', 99, 25] Clustering:OK ## Clustering Result ## [1, 1, ['135.008.060.182', '172.016.112.050', 1106, 25]] [2, 2, ['111.222.111.033', '172.016.112.050', 99, 25]] Scoreing:OK ## Scoreing Result ## [0.6931471805599453, 2, 1] [0.6931471805599453, 1, 1]